HashTable/HashMap/ConcurrentHashMap
概述:
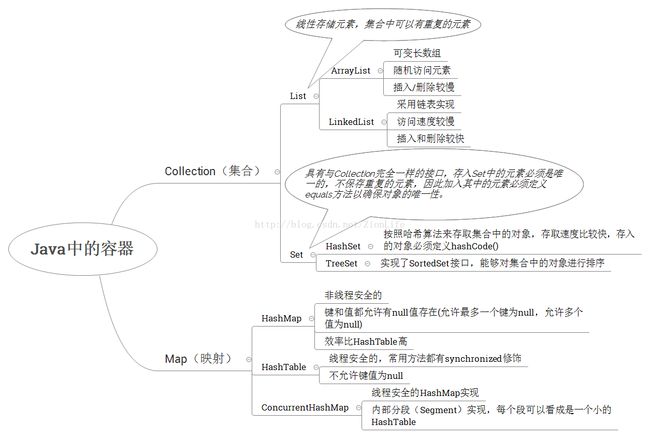
Hashtable 是散列表,存储的是键值对(key-value)的映射。Hashtable 继承与Dictionary,实现了Map、Cloneable、Serializable接口。它是线程安全的。Hashtable 中的映射不是有序的。
Hashtable 有四个构造函数,分别是:
// 默认构造函数。
public Hashtable()
// 指定“容量大小”的构造函数
public Hashtable(int initialCapacity)
// 指定“容量大小”和“加载因子”的构造函数
public Hashtable(int initialCapacity, float loadFactor)
// 包含“子Map”的构造函数
public Hashtable(Map t)
重点解析:
HashTable是通过“拉链法”解决冲突的。HashTable中的几个重要变量:
private transient HashtableEntry[] table;
private transient int count;
private float loadFactor;
private int threshold;
private transient int modCount = 0;
①、table是HashtableEntry数组,HashtableEntry是实现了Map、Entry接口的单链表,其内部有对自己另一个实例的引用next。②、count指示了当前Hashtable 中Entry的数量。③、loadFactor是加载因子,是Hashtable 在其容量自动增加之前可以达到多满的一个度。默认值是0.75,是时间和空间寻求的折中。④、threshold是Hashtable进行rehash的一个临界值,其值为(capacity * loadFactor)。⑤、modCount是Hashtable 被结构性更改的次数(指的是改变entries的数量或rehash)
主要看下put方法和get方法:
put:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
HashtableEntry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (HashtableEntry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
HashtableEntry e = tab[index];
tab[index] = new HashtableEntry<>(hash, key, value, e);
count++;
return null;
}
put方法前使用了syncronized修饰,说明Hashtable是线程安全的。传入key和value,首先取得key的hashcode(key.hashCode()),然后先于0x7FFFFFFF与运算(网上说法是为了避免hash是负数),然后与链表数组的长度(即HashtableEntry[] tab)进行求余,得到在链表数组中的index。然后判断在tab[index]这条链中是否存在哈希码与键都相同的,如果存在则替换并返回旧的值。否则构造一个新的HashtableEntry作为table[index]的头结点,并把原来的tab[index]作为插入对象的下一个结点,返回null。
get:
public synchronized V get(Object key) {
HashtableEntry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (HashtableEntry e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
get方法更容易点。还是先获取哈希码,计算index。然后依次查找是否存在哈希码与key都匹配的,若存在就返回。
与HashMap的区别
可以将HashMap看成是Hashtable的轻量级实现。他们都完成了Map接口。
主要区别在于
①、HashMap允许键值为null(允许最多一条记录的键为null,允许多条记录的值为null),而Hashtable不允许。
②、且HashMap是线程不安全的,效率上可能高于Hashtable,而Hashtable是线程安全的(方法由synchronized修饰)。
ConcurrentHashMap
Hashtable是线程安全的,synchronized是针对整张表,即每次锁住整张表让线程独占,ConcurrentHashMap则允许多个修改并发进行,其关键在于使用了锁分离技术,使用多个锁来控制对hash表不同部分进行的修改。
ConcurrentHashMap内部使用段(Segment)来表示不同的部分,每个段其实就是一个小的hash表,它们有自己的锁,只要多个修改发生在不同的段上,它们就可以并发进行。
针对有些需要跨段的方法,比如size()、containsValue()等,需要锁定的是整张表,因此需要按顺序锁定所有的段,操作完毕后再按顺序释放所有的段。这里的顺序很重要,否则可能发生死锁。
ConcurrentHashMap中的读操作不用加锁,完全允许多个读操作并发进行。