编程问题---第一次
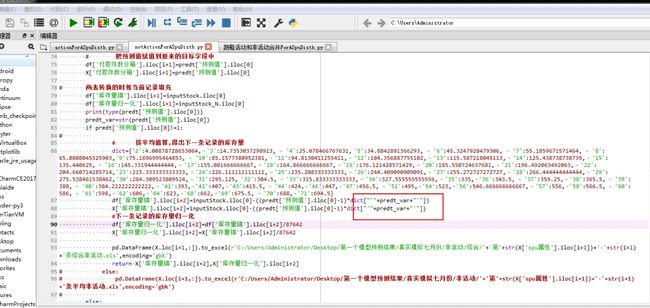
单引号的输入
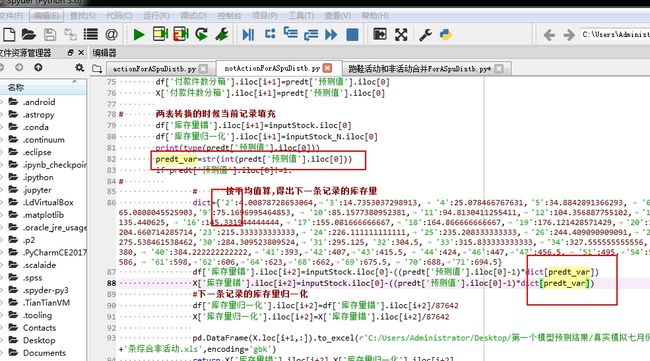
字典的key值输入不用加引号
列数不能超过256
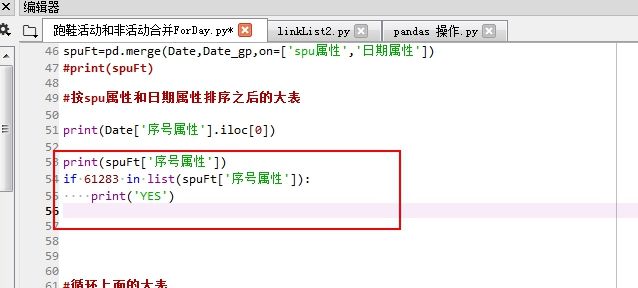
In 不能直接用于series 只能用于 list 可以用 isin
print(spuFt['序号属性'].isin([61283]))
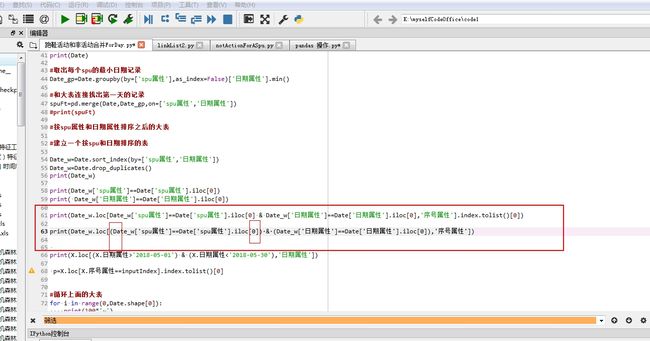
多条件筛选 每个条件需要加括号
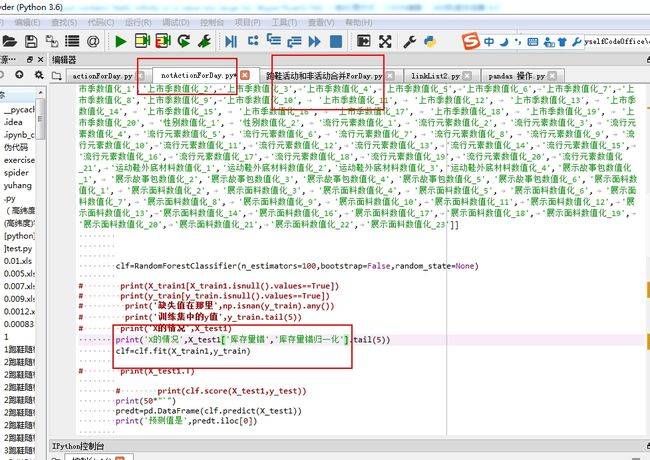
子模块被主模块引用的 如果子模块有变动 需要重新运行导入一遍 才能运行更改过的子模块
Python中的break和continue的使用方法
一、continue的使用方法(结束当前的循序,进行下一个数的循环)
# *****************************************************************************
# This is a program to illustrate the useage of continue in Python.
# If you want to stop executing the current iteration of the loop and skip ahead to the next
# continue statement is what you need.
# ****************************************************************************
for i in range (1,6):
print 'i=',i,
print 'Hello,how',
if i==3:
continue
print 'are you today?'
执行结果例如以下:
>>> ================================ RESTART ======================
>>>
i= 1 Hello,how are you today?
i= 2 Hello,how are you today?
i= 3 Hello,how
i= 4 Hello,how are you today?
i= 5 Hello,how are you today?
>>>
二、break的使用方法(结束总的循环)
# *****************************************************************************
# This is a program to illustrate the useage of break in Python.
# What if we want to jump out of the loop completely—never finish counting, or give up
# waiting for the end condition? break statement does that.
# ****************************************************************************
for i in range (1,6):
print 'i=',i,
print 'Hello,what is ',
if i==3:
break
print 'the weather today?'
执行结果例如以下:
>>> ================================ RESTART ========================
>>>
i= 1 Hello,what is the weather today?
i= 2 Hello,what is the weather today?
i= 3 Hello,what is
>>>
Jupyter 工作目录更改
https://blog.csdn.net/lixintong1992/article/details/53012921
ipython notebook 改名叫jupyter了。
在cmd中,输入“ipython notebook”或“jupyter notebook”打开notebook,此时cmd的当前路径即为notebook的工作路径。
另外,可通过设置config文件的方法来设置固定的工作路径。
方法是:
1 选择一个用于存放config文件的文件夹
2 在cmd中进入该文件夹的路径
3在cmd中 输入命令jupyter notebook --generate-config
4 此时在该文件夹中便生成一个notebook的config文件,文件名是“jupyter_notebook_config.py”
5 打开该文件,修改
“# The directory to use for notebooks and kernels.”下面的
“# c.NotebookApp.notebook_dir = ””为
“c.NotebookApp.notebook_dir = ‘指定的工作路径’”(注意将#号删除)
配置文件位置
C:\Users\用户名.jupyter\jupyter_notebook_config.py
出现Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build*解决办法
2018年01月16日 17:00:30 阅读数:16493 标签: linuxubuntu 更多
个人分类: linux
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011324454/article/details/79076885
我在使用sudo pip install jupyter的时候出现了Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-sr2_jA/distribute/这个错误,百度了好久也试了前人的很多方法,最后在stack overflow上看到了一句代码见奇效
(就是没有安装好)
easy_install -U setuptools
· 1
然后在执行sudo pip install jupyter竟然没有报错安装成功了
pip还不能完全取代easy_install,哈哈哈
https://blog.csdn.net/infovisthinker/article/details/54705826
Tensorflow-gpu 安装

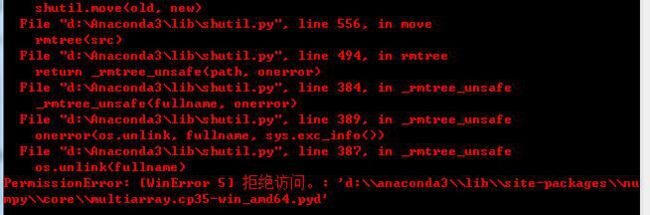
今天因为安装自然语言分词gensim 3.0.0模块,需要升级numpy到1.11.3以上版本,没有问题啊,升级呗,结果升级安装提示:
PermissionError: [WinError 5] 拒绝访问。: 'd:\\anaconda3\\lib\\site-packages\\nu
mpy\\core\\multiarray.cp35-win_amd64.pyd'
哔了狗啊,以前都没有问题,咋回事呢,在试试安装whl版本的numpy,下载了117M的numpy-1.13.3+mkl-cp35-cp35m-win_amd64.whl,使用命令:
pip install numpy-1.13.3+mkl-cp35-cp35m-win_amd64.whl
哎呦我去,依然是这个错误:
咋整?问度娘,度娘说,你的参数需要加上--user,于是再次安装:
pip install --user numpy-1.13.3+mkl-cp35-cp35m-win_amd64.whl
结果万事大吉!
模块和主解释器的关系
先建立环境 然后在环境里面再安装这个模块
print((rdm.rand()/10.0-0.05)) # 构造-0.05 到0.05 范围的值
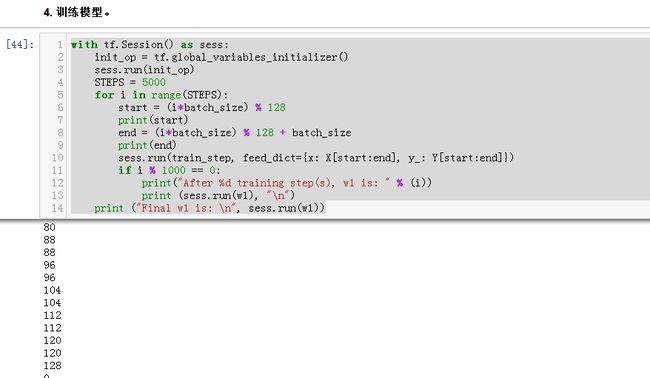
构造一个 通过batch 取完数据集里面的所有值 一次取一个batch
128/8=16
16次 完成128个数据 一个batch 的遍历
5000/128=312
完成312 次 128个数据的迭代
移动平均,差分等 看
G:\BaiduNetdiskDownload\46-时间序列预测\时间序列\46.3差分自回归移动平均模型(ARIMA) 笔记
问题:把列值作为index
Parse_dates=[0]

Inverse_transform 把归一化的值转回来
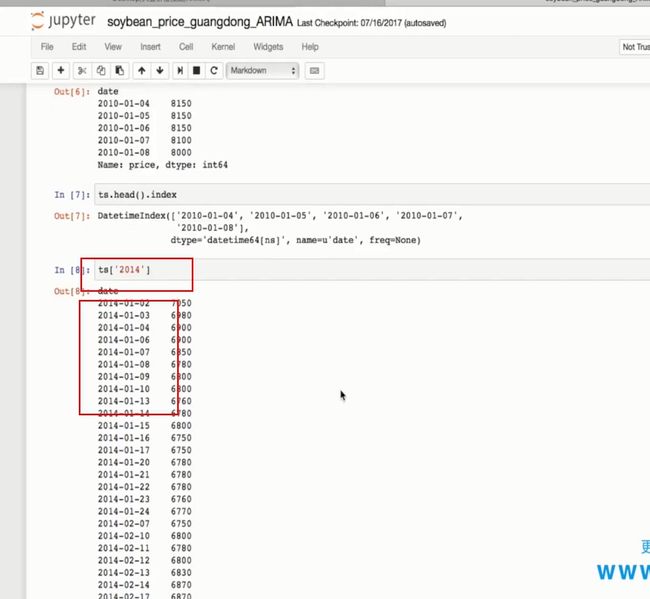
卧槽 直接匹配出2014年的
查看空缺值有几个空格
Print 是经过格式化了
要直接在控制台输出 才知道具体是什么
按tab键补全
G:\BaiduNetdiskDownload\炼数成金《深度学习框架Tensorflow学习与应用》\第二周\第二周 2-2 变量的使用
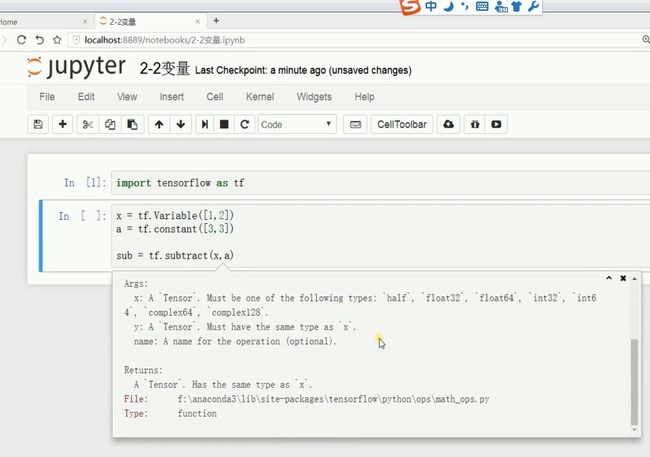
连续按两次 shift +tab 键 可以看到详细的方法描述 属性
1324 446
print((rdm.rand()/10.0-0.05)) # 构造-0.05 到0.05 范围的值 构造某个范围内的数
start = (i*batch_size) % 128
end = (i*batch_size) % 128 + batch_size
Y = [[x1+x2+(rdm.rand()/10.0-0.05)] for (x1, x2) in X] # 同时循环出多个数
Reduce_mean
with tf.Session() as sess:#最后一句不需要sess.run()
v=tf.constant([[1,3,1],[4,2,2]])
sess.run(v)
print(tf.reduce_mean(v).eval())
举例说明:
00001.
# 'x' is [[1., 2.]
00002.
00003.
# [3., 4.]]
00004.
x是一个2维数组,分别调用reduce_*函数如下:
首先求平均值:
00001.
tf.reduce_mean(x) ==> 2.5 #如果不指定第二个参数,那么就在所有的元素中取平均值
00002.
00003.
tf.reduce_mean(x, 0) ==> [2., 3.] #指定第二个参数为0,则第一维的元素取平均值,即每一列求平均值
00004.
00005.
tf.reduce_mean(x, 1) ==> [1.5, 3.5] #
00006.
指定第二个参数为1,则第二维的元素取平均值,即每一行求平均值
Reshape [-1,1] 的问题 一般都是数值内嵌方括号的问题
https://blog.csdn.net/NockinOnHeavensDoor/article/details/80660158
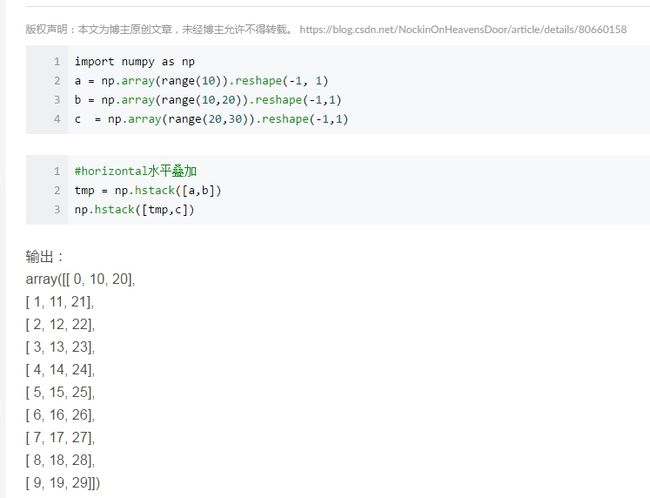

https://blog.csdn.net/wlwl2015/article/details/81902540
Reshape(-1,1)
-1 表示不知道有多少行 可以指定列数
00001.
z = np.array([[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]])
z.shape
z.reshape(-1, 2)
array([[ 1, 2],
[ 3, 4],[ 5, 6],[ 7, 8],[ 9, 10],[11, 12],[13, 14],[15, 16]])
In [14]: x=np.array([[1,2],[3,4]])
# flattenh函数和ravel函数在降维时默认是行序优先
In [15]: x.flatten()
Out[15]: array([1, 2, 3, 4])
In [17]: x.ravel()
Out[17]: array([1, 2, 3, 4])
# 传入'F'参数表示列序优先
In [18]: x.flatten('F')
Out[18]: array([1, 3, 2, 4])
In [19]: x.ravel('F')
Out[19]: array([1, 3, 2, 4])
#reshape函数当参数只有一个-1时表示将数组降为一维
In [21]: x.reshape(-1)
Out[21]: array([1, 2, 3, 4])#x.T表示x的转置
In [22]: x.T.reshape(-1)
Out[22]: array([1, 3, 2, 4])
· 22
两者区别
>>> x = np.array([[1, 2], [3, 4]])>>> x.flatten()[1] = 100>>> x
array([[1, 2],
[3, 4]]) >>> x.ravel()[1] = 100>>> x
array([[ 1, 100],
[ 3, 4]])
00001. 0.3 秒暂停一下
注意事项:
PyCharm一个窗口只能运行一个工程,如需创建多个关联不大的程序有以下方式:
1. 在创建工程的时候以新窗口打开(否则当前窗口会被关闭)
2.在当前工程上直接新建其他程序(可以使用文件夹分隔)
3.当需要同时运行多个耗时程序时,IDE会有卡顿

If 的条件语句 必须连续 不能有超空格

右边的变量管理器不是实时更新的
https://blog.csdn.net/lanchunhui/article/details/49493633
·
range()返回的是range object,而np.nrange()返回的是numpy.ndarray()
range尽可用于迭代,而np.nrange作用远不止于此,它是一个序列,可被当做向量使用。
range()不支持步长为小数,np.arange()支持步长为小数
两者都可用于迭代
两者都有三个参数,以第一个参数为起点,第三个参数为步长,截止到第二个参数之前的不包括第二个参数的数据序列
某种意义上,和STL中由迭代器组成的区间是一样的,即左闭右开的区间。[first, last)或者不加严谨地写作[first:step:last)

np.newaxis的功能是插入新维度,看下面的例子:
a=np.array([1,2,3,4,5])
print a.shape
print a
输出结果
(5,)
[1 2 3 4 5]
可以看出a是一个一维数组,
x_data=np.linspace(-1,1,300)[:,np.newaxis]
a=np.array([1,2,3,4,5])
b=a[np.newaxis,:]
print a.shape,b.shape
print a
print b
输出结果:
(5,) (1, 5)
[1 2 3 4 5]
[[1 2 3 4 5]]
x_data=np.linspace(-1,1,300)[:,np.newaxis]
a=np.array([1,2,3,4,5])
b=a[:,np.newaxis]
print a.shape,b.shape
print a
print b
输出结果
(5,) (5, 1)
[1 2 3 4 5]
[[1]
[2]
[3]
[4]
[5]]
可以看出np.newaxis分别是在行或列上增加维度,原来是(6,)的数组,在行上增加维度变成(1,6)的二维数组,在列上增加维度变为(6,1)的二维数组

三维的表现形式
问题?
如果 算法里面 如果出现 need real figure not str 有可能是给算法设置的参数有问题

数组元素之间没有符号 ,每一行之间是 \n
List 元素之间是逗号,一行与一行之间是逗号

跳出多循环
https://blog.csdn.net/zSean/article/details/75057806
Tensorflow中tf.get_variable和tf.variable_scope的使用
https://www.jianshu.com/p/a1a9e44708f6 操作
import tensorflow as tf
data = [[[1, 1, 1], [2, 2, 2]],
[[3, 3, 3], [4, 4, 4]],
[[5, 5, 5], [6, 6, 6]]]
# print(type(data))
x = tf.strided_slice(data,[0,0,0],[1,2,1])
with tf.Session() as sess:
print(sess.run(x))

看数组的维度
最外面有几层中括号 就有几维
第一维度是识别 减少一个方括号之后 直到第二个多层中括号遇到的逗号之前 从左往右看f
倒数第二维的识别 看能否直接去掉最外一层括号 (要确保最外面一层要比里面任何一层的单边方括号数量都要多)
最后一个维度的识别,最里层中括号所包含的元素个数
问题? UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 第一个实现 strict 改成ignore 可以解决问题
最好的解决的方案是通过notepad 打开 然后保存为正确的编码格式最好

通过这个函数可以进入

r = r.decode('utf-8')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5
解决方法:
1.查看文件的编码格式
2.Csv,xls 相互交换查看
f = r'K:\myselfCodeOffice\code1\dataset_2.csv'
# df =codecs.open(f,'rb','ascii','ignore') # 读入股票数据
2. F的 关闭文件 重新打开运行
4.

当有一个实例在运行的时候 同时再运行第二个实例的时候就会出现编码错误
有时候可行 有时候又不可行 真是服了
问题? 查看别人的代码很多问题就有可能是之前编辑的代码版本太低,直接注释掉 之后 改用新版本的代码改写
库不存在,has no attribution 等
module 'PyQt5.QtGui' has no attribute 'QApplication'
问题:
Parent directory of crack_capcha.model doesn't exist, can't save. (tensorflow 报错)
在保存模型的时候报的错,
使用代码:
saver.save(sess, "crack_capcha.model", global_step=step)
解决方案:
在crack_capcha.model 的前面加./,即使用代码:
saver.save(sess, "./crack_capcha.model", global_step=step)
问题即可解决。
为什么呢?./代表代码执行的根目录,之前直接那样写是找不到文件存放的目录的,或者也可以直接写绝对路径。
问题?
Python 安装库,包
https://blog.csdn.net/wait_for_eva/article/details/79440510
指定编译器
自己硬盘上指定位置就行了,这个就这样。
安装包
easy_install和pip都可以安装,但是装逼气氛浓厚,配置和使用问题多。
对于windows的用户,那是相当的不友好。
明明按照步骤来的,就是会错。
不过现在不用担心了,windows嘛,干嘛要装逼呢,windows上图形界面才是王道好不好。
反正我垃圾,研究没那么深,也用不着。
![]()
还是刚才那里,点那个加号
![]()
1. 先搜索框中搜索
2. 在资源池中确定资源
3. 直接安装就行了
方便吧,快捷吧
配置PIP源
更换pip源更是方便。
![]()
![]()
如你所见,右边三个分别是
1. 增加
2. 删除
3. 修改
都是pip源的操作,豆瓣源就很好,你可以试试
https://pypi.douban.com/simple/
默认的pip源实在是low,配置一下还得写pip.ini,尤其是.pip文件夹,问题是windows允许你.(点)么。
操蛋,这样就好多了。
这样子不仅能装了,而且速度快多了,以前真的是水深火热。
尤其你想scrapy?TensorFlow?
以前我装一个matplotlib基本都不可能。
依赖包多,我一个一个来。
直接装的,源码装的,whl文件装的,结果有些还是不了。
这下舒服多了。
学框架,至少得获取到框架不是。
https://www.cnblogs.com/hkgov/p/7799078.html
更换安装源
问题:弹到另一个屏幕 隐藏的问题
右键点出来 然后 用 Fn加快捷键 最大化而出现窗口
https://blog.csdn.net/wj1066/article/details/78853717
https://blog.csdn.net/maymay_/article/details/80241627
pandas中时间窗函数rolling的使用
pycharm debug出现UnicodeDecodeError: 'utf-8' codec can't decode 解决办法
原先我的python文件都是在最初建的一个project下,在另外一个文件夹下新建一个python文件,直接用pycharm点开就不会出现这种问题,于是我把这个project对应文件夹下的除.py文件外其他的都删除。这个问题目前来说没有出现了。 --------------------- 本文来自 zhxh0609 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/shaiguchun9503/article/details/81115605?utm_source=copy
乱码问题
如果代码打开是乱码,先用notepad 打开再改成正确的代码编码保存之后再打开就可以了

ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
为什么这里不能用and 或者 or
问题
这种问题一般是对一个表的更改不小心错误的赋值给另一个表了
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
如果等于其本身 也会有警告
问题?
应该是超出最大行的限制了
excel 无法粘贴信息,原因是复制区域与粘贴区域形状不同
问题
setting an array element with a sequence
矩阵的列没有对齐,把没对齐的数据补上就可以了 维度变换有错
原因是在把数据输入网络的时候列表的行数列数不匹配,比如
[[1,2], [2, [3, 4]]]
[[1,2], [2, 3, 4]]
而tensor必须要2*2或者3*3的输入才行
问题
Numpy array: sequence too large
sequence too large error means that you are creating a multidimension array that the dimension is large that 32. For example: np.empty([1]*33) will this error. Are you sure you want to create >32 dimension array? If you want to create an empty array the same shape as model[MN][i], you should use: empty_like(). – HYRY Jul 17 '13 at 1:22
问题
ValueError: Cannot feed value of shape (1,) for Tensor u'Placeholder:0', which has shape '(1, 1)'
其实原因很简单,我这里的feed需要(1,1)的矩阵,也就是一维的且只有一个元素的矩阵,但[x_]和[y_]在tensorflow里会被认为是一维的但元素个数不知的数组。所以加个方括号, 即[[x_]]和[[y_]]就搞定了
因为在给函数传参数shape时需要传递形状,如shape=[2,2],表示2维矩阵,每个维度有两个元素,只是代表形状,不是具体的矩阵
当传递给feed里面的占位符时,需要实际具体的矩阵而不是形状,如传二维的矩阵:x_data:[[1,1],[1,1]]
问题?
OSError: Initializing from file failed
当你用pandas读取文件报这种错误时,一般是因为你的文件名中带有中文,例如:
res = pd.read_csv('我的文件.csv')
这种情况就会报错,只需要这样更改就可以:
f = open('我的文件.csv')
res = pd.read_csv(f)
另一种方法
temp=pd.read_csv(f,encoding='gbk',engine='python') 加个engine=’python’ 用于python3.6 也可以
问题?
路径里面最好不要有中文
https://www.cnblogs.com/hhh5460/p/5615729.html 转换的总结
https://blog.csdn.net/csdn15698845876/article/details/73380803 stack
https://www.cnblogs.com/hhh5460/p/5615729.html sklearn 并行 高效的处理数据 重点
使用sklearn优雅地进行数据挖掘
Pipeline
https://www.cnblogs.com/bambipai/p/7658311.html
https://mp.weixin.qq.com/s?__biz=MzI5MjM4MDM1Nw==&mid=2247484382&idx=1&sn=2b8c4cb3b538ea442d302d8557e0e4ab&chksm=ec030874db748162a49452b8ba75c9d308e5d95a1b6acc71a440365090f492c2ab39b539fb21&mpshare=1&scene=1&srcid=08186LQegqpH9Onh1Vm5PXjd#rd
pipeline
在用pandas进行数据重排时,经常用到stack和unstack两个函数。stack的意思是堆叠,堆积,unstack即“不要堆叠”,我对两个函数是这样理解和区分的。
常见的数据的层次化结构有两种,一种是表格,一种是“花括号”,即下面这样的l两种形式:

|
|
store1 |
store2 |
store3 |
| street1 |
1 |
2 |
3 |
| street2 |
4 |
5 |
6 |
表格在行列方向上均有索引(类似于DataFrame),花括号结构只有“列方向”上的索引(类似于层次化的Series),结构更加偏向于堆叠(Series-stack,方便记忆)。stack函数会将数据从”表格结构“变成”花括号结构“,即将其行索引变成列索引,反之,unstack函数将数据从”花括号结构“变成”表格结构“,即要将其中一层的列索引变成行索引。例:
raise ValueError("cannot reindex from a duplicate axis")
ValueError: cannot reindex from a duplicate axis
这个是存在重复字段
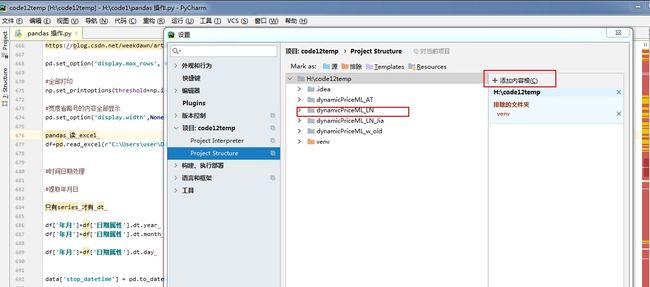
Pycharm 当前目录设置 重点
目录结构
这应该是一个web服务,dao,db是数据库相关,engines是主要的引擎部分,service是相关服务,utils是工具类,web应该是含有主要的后台服务。可以从web开始看
第一步:
NewProject,跳转到下放页面:
![]()
![]()
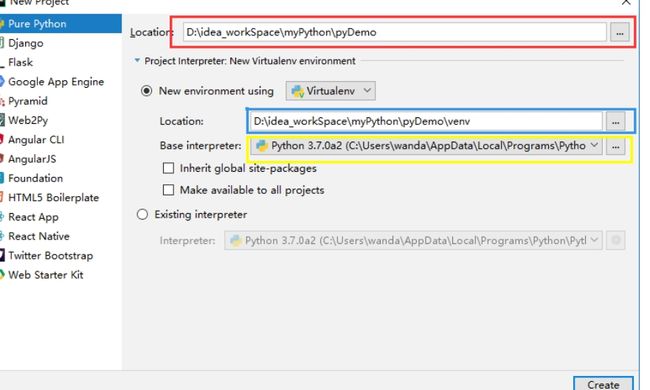
“红色框”是项目所在的路径。(注意:项目路径不要包含中文)
“蓝色框”是根据红色框的路径自动生成,我们不用管它,它是pyCharm自动根据项目路径,
在项目中添加了“venv”文件夹,是项目的依赖。
“黄色框”中的路径是这个项目所依赖的python,路径是你本地python的python.exe的全路径,是项目的依赖。
点击右下角的“Create”按钮,创建项目。
create virtual......
第二步:
简单的python项目创建成功,看一下目录结构:
![]()

“红色框”:我建的工作文件,文件下有自己写的demo01程序。
“蓝色框”:pyCharm为我们生成的依赖文件夹,可以看到灰色字(library root),
这是我们项目的依赖,所以不要动。(注:venv可以创建虚拟环境,让多个项目之间的Python依赖隔离开,不会在项目之间冲突。)
“黄色框”:写的简单的示例python代码。

当调试出现乱七八糟的结果而不是需要的结果的时候 就是代码出错了
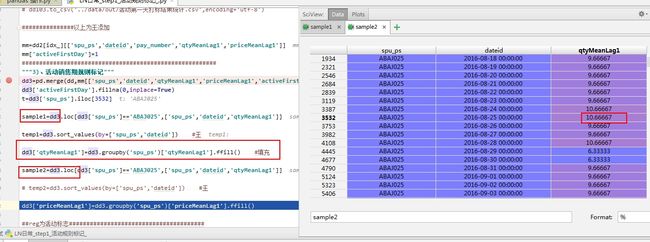
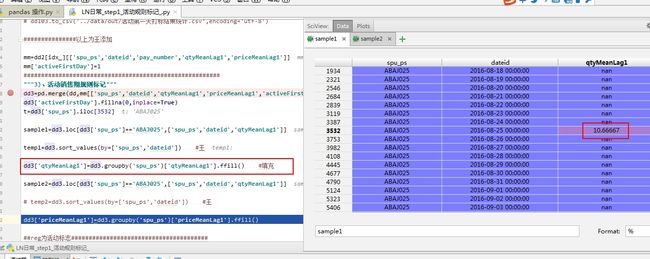
奇怪了 怎么填充了这么多值 而且是不同的 应该是相同的才对
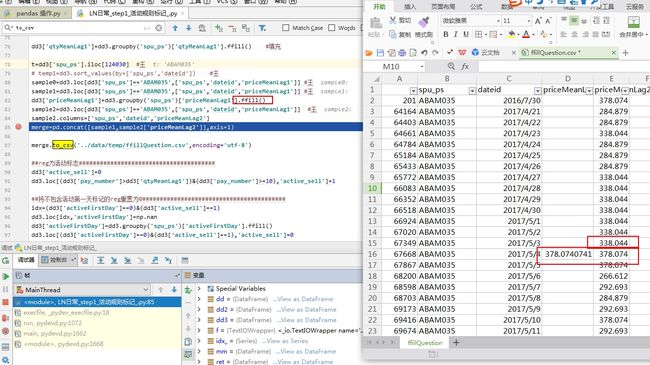
并不是以378 来填充的 见鬼了
python路径拼接os.path.join()函数完全教程
https://blog.csdn.net/weixin_37895339/article/details/79185119
路径拼接
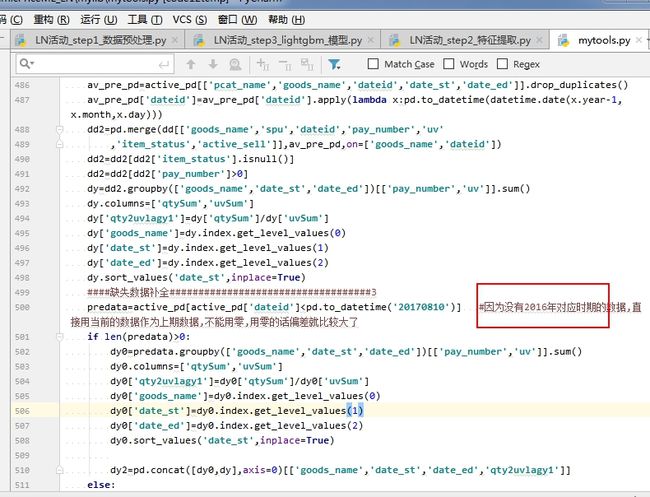
#因为没有2016年对应时期的数据,直接用当前的数据作为上期数据,不能用零,用零的话偏差就比较大了
https://www.cnblogs.com/chownjy/p/8663024.html python self
如果self指向类本身,那么当有多个实例对象时,self指向哪一个呢?
总结
self在定义时需要定义,但是在调用时会自动传入。
self的名字并不是规定死的,但是最好还是按照约定是用self
self总是指调用时的类的实例。
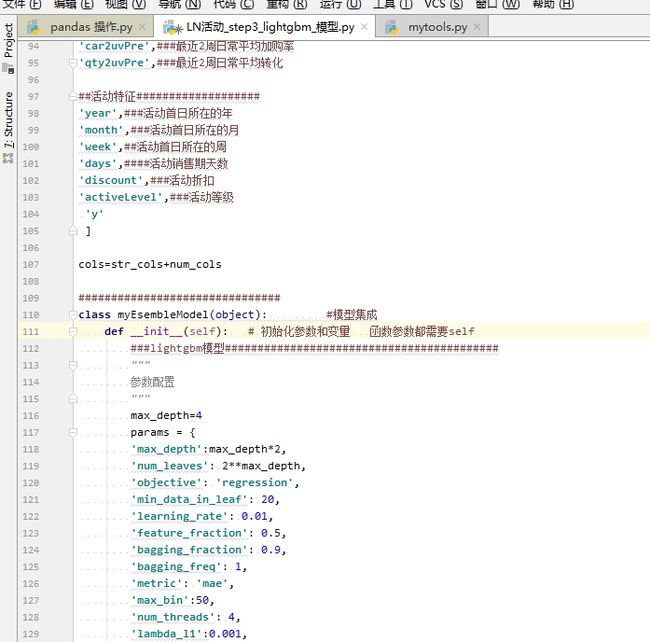
类里面的函数的第一个参数都需要self
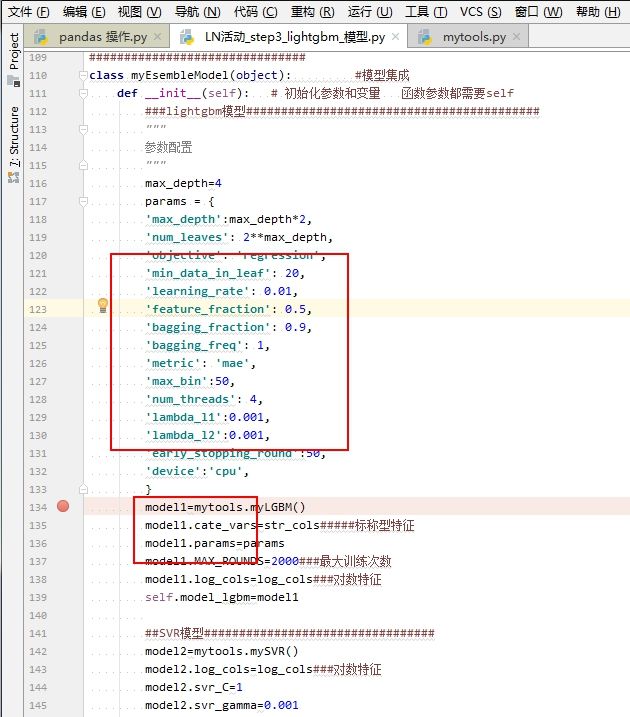
模型本身的参数直接赋值:上面是模型本身的参数
下面是非模型本身的参数,自己定义的参数 要再次赋值
https://blog.csdn.net/quiet_girl/article/details/72517053
Fit_transform
和transform的区别
· # 从sklearn.preprocessing导入StandardScaler
· · from sklearn.preprocessing import StandardScaler
· · # 标准化数据,保证每个维度的特征数据方差为1,均值为0,使得预测结果不会被某些维度过大的特征值而主导
· · ss = StandardScaler()
· · # fit_transform()先拟合数据,再标准化
· · X_train = ss.fit_transform(X_train)
· · # transform()数据标准化
· · X_test = ss.transform(X_test)
· --------------------- 作者:nana-li 来源:CSDN 原文:https://blog.csdn.net/quiet_girl/article/details/72517053?utm_source=copy 版权声明:本文为博主原创文章,转载请附上博文链接!
Dictvector 直接独热编码
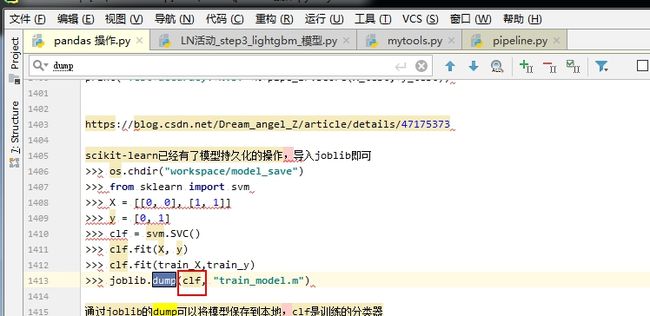
Joblib 第一个参数是模型
https://mp.weixin.qq.com/s?__biz=MzI5MjM4MDM1Nw==&mid=2247484382&idx=1&sn=2b8c4cb3b538ea442d302d8557e0e4ab&chksm=ec030874db748162a49452b8ba75c9d308e5d95a1b6acc71a440365090f492c2ab39b539fb21&mpshare=1&scene=1&srcid=08186LQegqpH9Onh1Vm5PXjd#rd
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
pipe_lr = Pipeline([('sc', StandardScaler()),
('pca', PCA(n_components=2)),
('clf', LogisticRegression(random_state=1))
])
上面的括号里面表示按顺序直线
pipe_lr.fit(X_train, y_train)
print('Test accuracy: %.3f' % pipe_lr.score(X_test, y_test))
# Test accuracy: 0.947
https://blog.csdn.net/lanchunhui/article/details/50354978
Ravel >>> x = np.array([[1, 2], [3, 4]])
>>> x
array([[1, 2],
[3, 4]])
>>> x.flatten()
array([1, 2, 3, 4])
>>> x.ravel()
array([1, 2, 3, 4])
两者默认均是行序优先
>>> x.flatten('F')
array([1, 3, 2, 4])
>>> x.ravel('F')
array([1, 3, 2, 4])
>>> x.reshape(-1)
array([1, 2, 3, 4])
>>> x.T.reshape(-1)
array([1, 3, 2, 4])
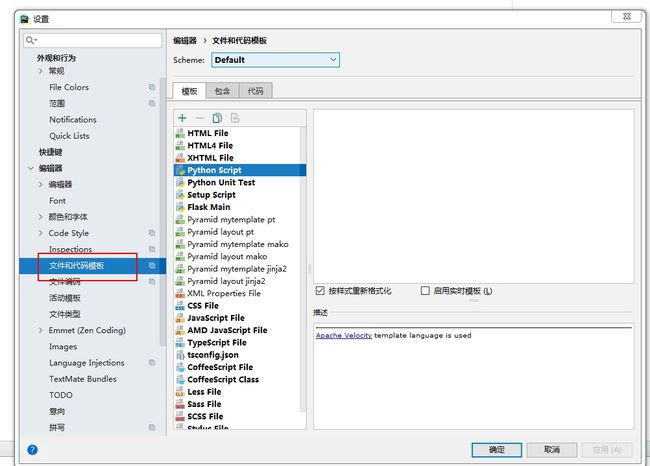
Python修改代码模板
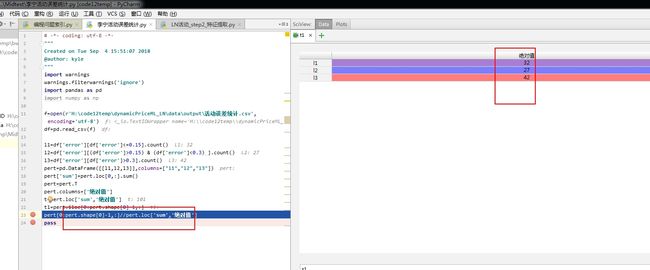
从一列里面取部分来做加减乘除不行?

两个// 是取整
Python dataframe dtype
Int,float32,float64,int64
Pip 源 包源 库源 非 anaconda 自己更新自身的源
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/

删除格式

造成程序读入之后列乱序很有可能就是这样隐藏了 格式混乱 excel
ValueError: day is out of range for month 问题
这个情况for循环 一个一个值的处理居然能通过
项目,虚拟环境的处理
项目是在虚拟环境中运行,但是二者的文件夹却是分开的,没有关系的 但是每个项目要选对应的python 所在地,真实的python 安装所在地,而不是环境所在地???????
项目和虚拟环境需要在同一个目的
虚拟环境就是为了要求干净的环境,就不要用conda装了
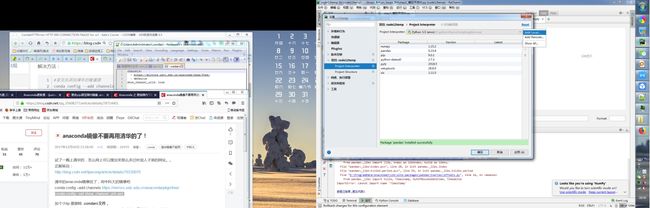
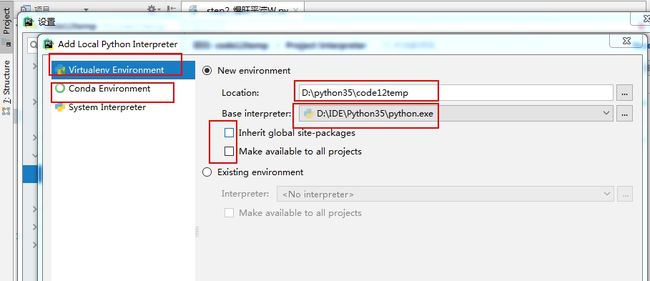
可以选第一个 VE,但是只能一个一个安装包
第二个conda 可以一起把所有的包都装上,但是 貌似国内源不能用了
Location,虚拟环境的location 随便选
编辑器,下载安装的 python 版本 根据自己要求来选
https://blog.csdn.net/qq_36015370/article/details/79484455
Anaconda 安装
Anaconda 命令
conda config –-show 注意是双横线
conda info 查看当前配置信息
Conda --help
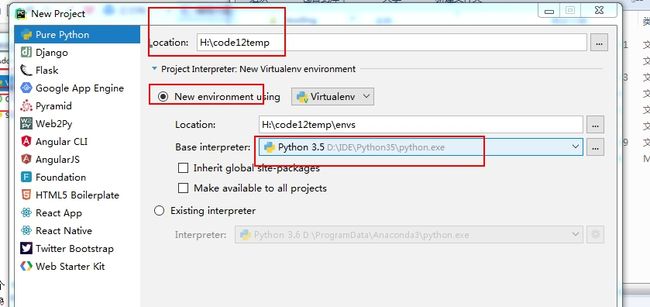
Pycharm确实是一个非常不错的Python开发IDE,尤其对于初学者而言。
https://www.cnblogs.com/loyung/p/8554836.html
打开新建项目
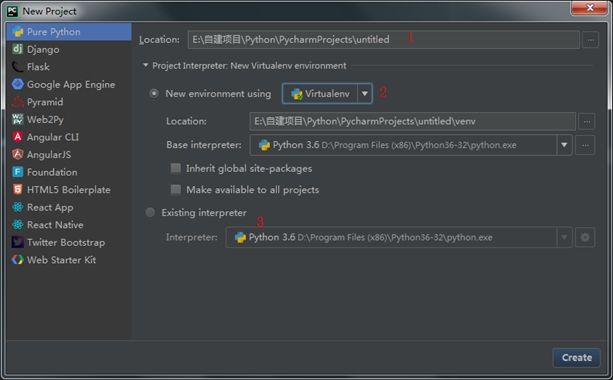
1.选择新建一个Pure Python项目,新建项目路径可以在Location处选择。
2.Project Interpreter部分是选择新建项目所依赖的python库,第一个选项会在项目中简历一个venv(virtualenv)目录,这里存放一个虚拟的python环境。这里所有的类库依赖都可以直接脱离系统安装的python独立运行。
3.Existing Interpreter关联已经存在的python解释器,如果不想在项目中出现venv这个虚拟解释器就可以选择本地安装的python环境。
那么到底这两个该怎么去选择呢,这里建议选择New Environment 可以在Base Interpreter选择系统中安装的Python解释器,这样做的好处有很多。
· python项目可以独立部署
· 防止一台服务器部署多个项目之间存在类库的版本依赖问题发生
· 也可以充分发挥项目的灵活性
项目开发过程中我们会用到很多的第三方类库:
打开项目文件——设置——项目——project Interpreter——选择项目环境,并且在项目环境中查看项目已引用的第三方库列表
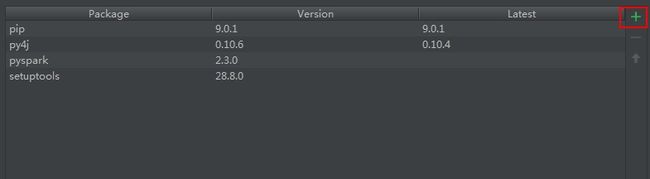
点击搜索添加需要的第三方库
默认地址是https://pypi.python.org/simple国外地址下载会非常慢,这里可以选择 Manage Repositories添加国内pip镜像

这里推荐三个非常不错的国内镜像
https://pypi.tuna.tsinghua.edu.cn/simple/ 清华大学镜像
http://pypi.douban.com/simple/ 豆瓣镜像
http://mirrors.aliyun.com/pypi/simple/ 阿里镜像
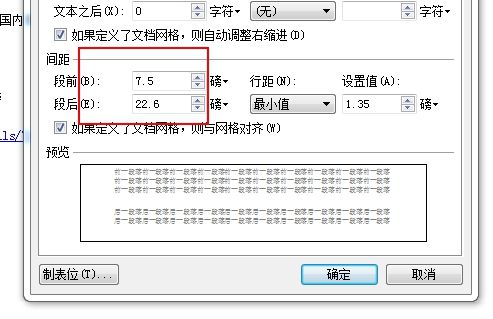
Word 要更改行与行的距离
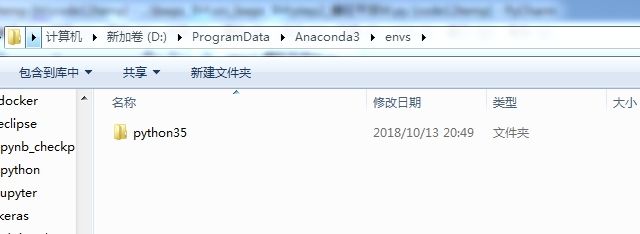
Anaconda 默认虚拟环境是创建在envs 这个目录下的
conda create -n envspython35 python=3.5
Conda 创建虚拟环境命令
换回conda 默认源
conda config --remove-key channels
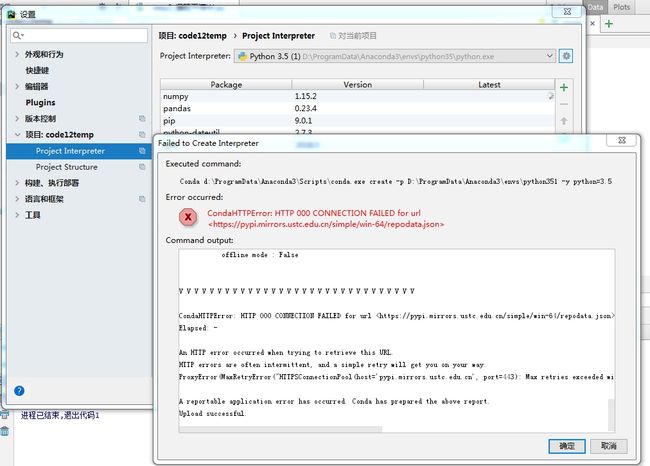
通过这里是安装不上 的
Pip 更新自身
python -m pip install --upgrade pip
Conda 命令
anaconda用法:
查看已经安装的包:
pip list 或者 conda list
安装和更新:
pip install requests
pip install requests --upgrade
或者
conda install requests
conda update requests
更新所有库
conda update --all
更新 conda 自身
conda update conda