英语写作错误笔记一
- of EFP, of the ACT :
of using the EFP, of using ACT;
- The STFT of a signal:
The STFT;
- added the Table. I of the revised manuscript:
added Table. I in the revised manuscript
- the convolutional layers:
convolutional layers
- number of overlapped samples:
the number of overlapped samples
- To achieve our goal of the separation of anisotropic Gaussian window
To achieve our goal of separation of the anisotropic Gaussian window
- revised the Fig. 10
revised Fig. 10
- RBF kernal
the RBF kernal
- in the each image
in each image
- achieves the higher classification accuracy than
achieves higher classification accuracy than
- of the specific stage
of a specific stage
- MobileNet extracts features from the named "conv2d 11" layer whose the size of output feature maps
MobileNet extracts features from the "conv2d 11" layer whose size of output feature maps
- but number of rows is given:
but the number of rows is defined as follows.
- An architecture of TFFNet.
when you use "An", it means that it is not necessarily architecture that you are using.
The architecture of TFFNet.
- use the same time range to [0,0.75] s :
use the same time range [0,0.75] s
- The observed signal has a length of 150000 samples in 0.75 seconds
The observed signal has a length of 150000 samples within a time interval of 0.75 seconds
- traditional FPN of construction a multi-resolution
traditional FPN for construction of a multi-resolution
- classier' mAP on the UWA communication signals dataset :
classier' mAP for the UWA communication signals dataset
- we revised the manuscript the following text:
we revised the manuscript as follows
We have revised the text as follows.
We have revised the following text.
- We have revised classifier to classifier.
This has been corrected.
- The classication performance of the TFFNet is compared with two machine learning methods, random forest (RF)
The classication performance of the TFFNet is compared with that of two machine learning methods, random forest (RF)
- image with 299 * 299 input size is
image of a size 299 *299 is
- is lower than RF and SVM-RBF
is lower than that of RF and SVM-RBF
- The RBF classification is less accurate compared SVM-RBF.
The RBF classification is less accurate compared to SVM-RBF.
- In the work/ Using the way
In this work/ Using this way
- get the data
extract the data
- TFFNet with STFT get a lower mAP
TFFNet with STFT results in a lower mAP
- references [21][22][23] of the revised manuscript
references [21][22][23] in the revised manuscript
- traditional FPN of construction a multi-resolution
traditional FPN for construction of a multi-resolution
- section II-A and section II-B
section II
- sparse ACT is exible in adjustment between complexity and energy concentration
allows adjustment of the trade-off between complexity and energy concentration
- a Beluga whale and a sperm whale sounds
Beluga whale and sperm whale sounds
a list![]() of
of ,
,![]() values with
values with ![]()
- is equal to
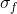 in the range from 0.2 to 2.6 with an interval of 0.3
in the range from 0.2 to 2.6 with an interval of 0.3
Parameters and ![]() each is a list of values [0.2, 0.5, 0.8, 1.1, 1.4, 1.7, 2.0,2.3].
each is a list of values [0.2, 0.5, 0.8, 1.1, 1.4, 1.7, 2.0,2.3].
- The factor
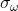 don't contain
don't contain
The factor ![]() does not contain
does not contain
- Consider the high efficiency of sparse ACT
For the high efficiency of sparse ACT
- should be big values
should be large values
- second one more impulses (spermwhales's clicks)
second one with impulses (spermwhales's clicks)
- Using the same hardware configuration, we did not compare with FSST
We could not do this for FSST
- experiment can't be executed
experiment cannot be executed
- a key factor in influence of the classification
a key factor influencing the classification
- we change the coordinate system [31].
we change the coordinate system as in [31]
- are learnt from some UWA signals.
are learnt from UWA signals.
- [12] has ...
The work [12] has ...
- An anisotropic operator
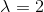 is selected.
is selected.
The parameter ![]() is selected (
is selected ( is a parameter, not an operator)
is a parameter, not an operator)
- the total samples is 1797
total number of samples
- sample number of each class is about 180.
the number of samples within each class
- RBF kernel in an example where the number
- There are several manners in
There are several ways in
- The drawback of these methods is that the addition of more training data
The drawback of these methods is their low capacity so that the addition of more training data
- a parameter you can tune.
a parameter one can tune.
- MobileNet, VGG-16 and Inception V3 extract features
MobileNet, VGG-16 and Inception V3 backbone networks extract features
- The number of samples of ve modulation types is equivalent, 500 training, 110 validation, and 70 test sets.
There are 680 signals with each type of modulation, of which 500, 110, and 70 are used for training, validation and testing, respectively.
- Comparison performance for di erent classification tasks.
Performance comparison for di erent classification tasks.
- three trained classiers of RF, SVM-RBF and TFFNet
three trained classiers, namely RF, SVM-RBF and TFFNet