RT-Thread智能音箱音频应用实践
国内智能音箱的问世早于国外,但由于国内对智能化概念普及程度较低,初期智能音箱并没有受到很多关注。但近几年国内智能音箱行业经历了从百花齐放到三足鼎立的发展阶段,来自RT-Thread的黄天翔将从占据主流市场的三个厂商脱颖而出的秘诀开始,分享RT-Thread在智能音箱在音频方面的内容。
文 / 黄天翔
整理 / LiveVideoStack
智能音箱现状

2014年10月,Alexa一款名为 Echo 的智能音箱出现,智能音箱行业开始火爆并受到极大关注。2015年年底,全球智能音箱销量达到250万台。

国内智能音箱的问世早于国外,但由于国内对智能化概念普及程度较低,初期智能音箱并没有受到很多关注。2015年京东叮咚系列音箱问世,2016年国内的美的、酷狗等多家公司涉足智能音箱行业,到2017年智能音箱市场全面爆发,2018年各大厂商已完成智能音箱的全面布局。
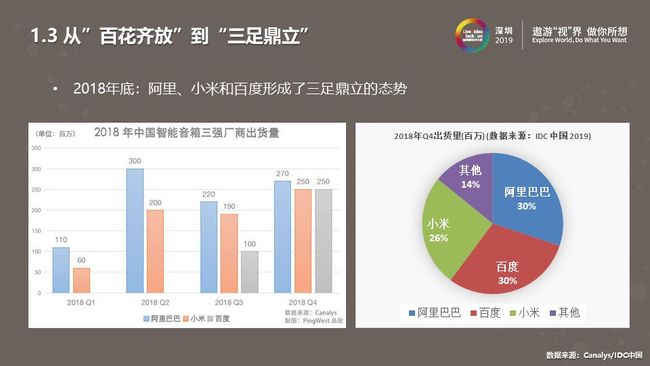
国内智能音箱行业经历了从百花齐放到三足鼎立的发展阶段,到2018年底,阿里、小米、百度三家独占鳌头,占据主流市场。

我们分析了三个厂商能脱颖而出的秘诀:首先百度用低价爆款的策略,以轻量化、小巧的产品迅速冲击市场。

其次,如上右侧图所示,在两年内国内厂商推出了多款智能音箱产品。从这些产品可以发现智能音箱大热还有一个重要因素:使用高性能芯片以及使用Linux系统方案。智能音箱涉及多方面难点技术,选用成本较高的方案快速迭代是市场得以推进的重要原因。

上图所示的是两种主流智能音箱的方案。百度小度智能音箱选用了Amlogic A113X1.5G 芯片配套 Linux 方案。小米音箱则是选用了全志 R16 A7四核心芯片。
基于现有方案可以预测,后续各厂商将会寻找低成本且同时也能满足快捷开发、稳定的方案替代,越来越多中端厂商在考虑能否使用RTOS方案代替Linux方案。
Linux向RTOS方案迁移分析

如上图所示的两种方案,当前方案中使用的是高端芯片,未来则会选择一些中低端甚至ARM9芯片完成智能音箱系统的开发。我们可以看到,目前方案从外接WIFI、蓝牙芯片转为使用内置芯片,包括芯片、MCU、DSP等都发生了变化。从封装来看,它从BGA封装变为QFN封装,生产成本明显降低。RTOS主打实时系统,开机速度降低到一两秒,此外,它还有功耗低等特性。RTOS在智能音箱领域有一定优势,例如在ACE回采时,我们会做主动唤醒,有固定的时间窗口使回采算法更可靠,时间不固定时回采数据不及时,RTOS可对时间窗口做极大保证。
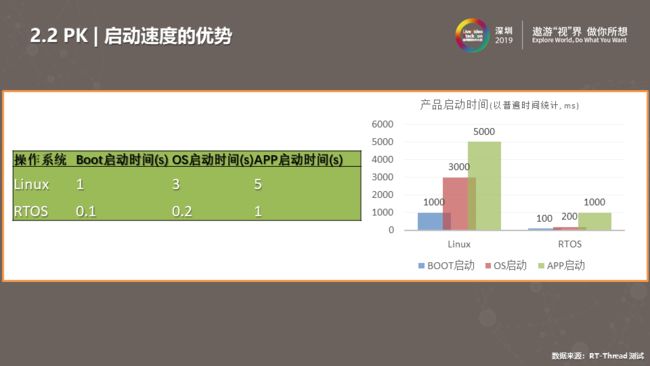
上图是通用方案启动速度对比。我们可以看出系统分为Boot、OS、APP启动三个层面。从三个层面整体来看,Linux系统启动需要10秒左右,而使用RTOS方案启动时间只有一两秒。
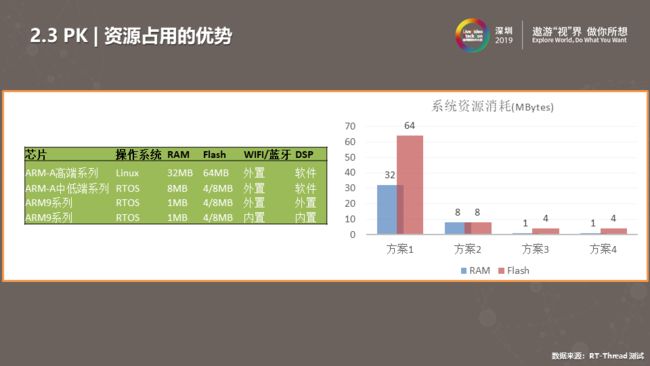
如上图,我们从四个方面做了对比。如大家所知,Linux所需的RAM、Flash是比较高的。ARM cortex-A方案是主流高端方案需要32MB RAM 和64MB Flash 的消耗。据我们统计,迁移 RTOS 方案 后可做到2MB RAM 和 4MB Flash 左右的消耗。由于 RTOS 系统比较轻巧,我们可以使用更小的RAM、Flash 芯片。

除了以上优势,RTOS也有生态劣势。智能音箱的操作系统更需要涉及到网络、音频相关的内容。Linux系统有成熟稳定的网络框架、音频子系统以及ffmpeg、Curl等开源软件。RTOS调度器则更多的使用了轻量级网络协议栈,在音频方面比较空缺,公司各有私有的方案,成本比较高。
我们使用RTOS研发音频播放系统鉴于成本趋势、系统资源问题和开发成本的综合考虑,希望能完成一套比较完整成熟的音频系统。
RT-Thread 网络音频播放器设计的迭代
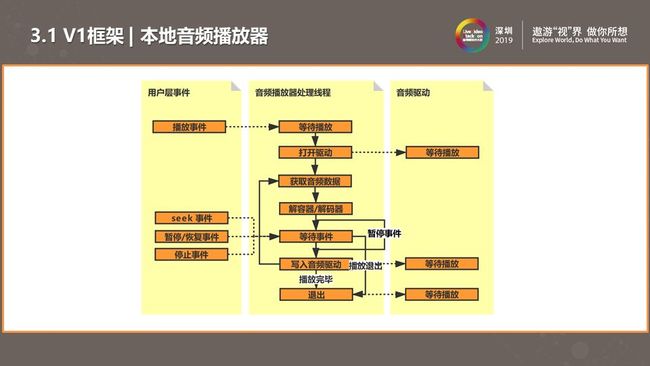
如上图是我们第一版音频播放器方案框架。早期设计这一款播放器,没有考虑网络播放的相关的功能。这版逻辑比较简单:获取音频数据后直接做解码,解码过程是一个循环逻辑,单线程等待外部响应事件,包括seek事件、暂停恢复事件、停止事件完成播放器逻辑,最后将解析出的数据写入底层音频驱动。
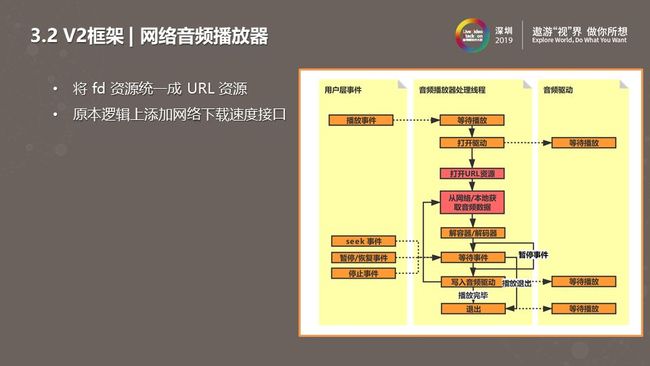
由于第一版不满足网络播放的市场需求,我们将网络组件、网络功能添加到了系统中。如上图中红色逻辑处理部分。在这部分我们对框架思路做了修改,将文件、网络资源放到同一层,选择本地或网络下载音频资源,整体呈单线程模式。无论打开的URL资源是本地资源还是网络资源,都是获得资源后做解码播放 。
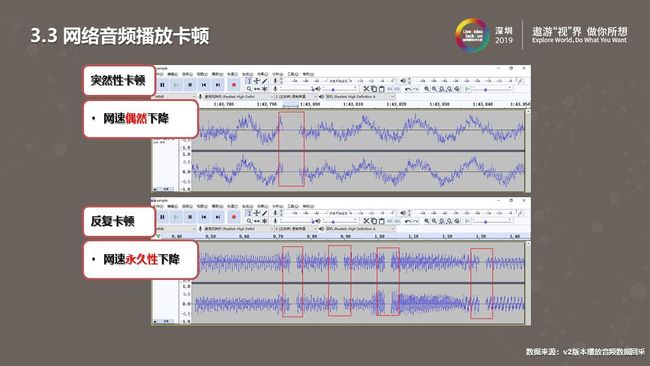
这版播放器随着在项目中越来越多的使用,逐渐的出现了很多噪音卡顿拖慢等问题。如上图是我们PCM项目回采得出的数据分析结果。我们在播放音频出现了短暂噪音之后继续播放的情况,后期多方面分析发现,这是由于网络情况不稳定,解码器短暂接收不到数据造成的。

如上图所示网络不可靠的原因有多种,很多网络不稳定是网络硬件造成的波动,软件层面是无法完全避免的,我们只能通过软件算法和思路减少这些问题造成的影响。
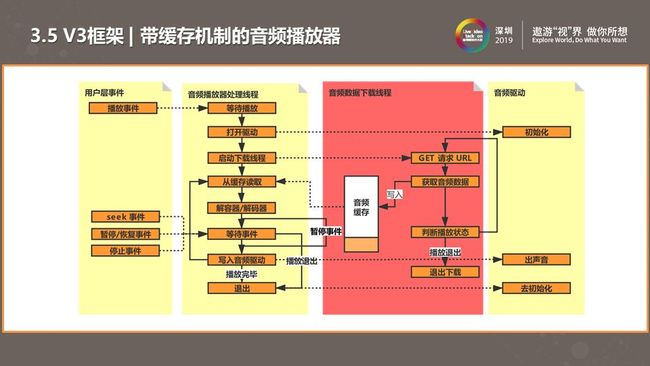
如上图是我们第三版改进后的播放器框架图。左侧是一样的,依然是获取数据进行解码,唯一不同的是我会从网络缓存区获取数据。启动播放后,我们会启动一个新线程将本地数据或网络音频写入缓存区,将下载与解码器分离。只要缓存区有数据,解码播放便不会出现卡顿。
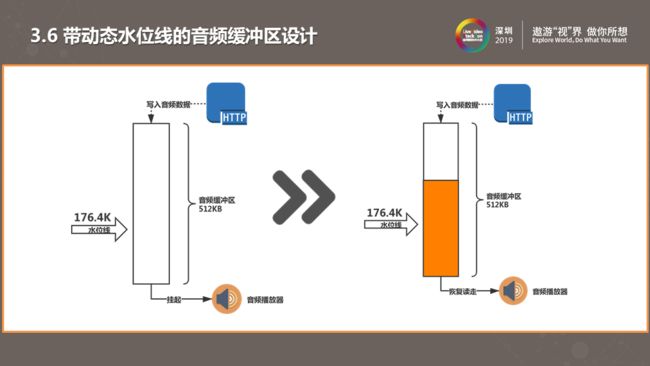
我们采用了带RTOS 唤醒调度机制且具有水位线管理的 pipe 作为第三版的音频缓冲区 。例如我们设置了一个512KB的缓存区,通过HTTP连接下载数据。如果缓存区中没有数据,我们可以简单认为下载与解码同时进行的。解码时缓存区没有数据时会等待直到音频数据高于水位线。水位线即可开始解码的最低缓存数据量。我们做了一个可动态调节的水位线机制。

改进过后,我们做了一个测试。如上图左侧是我们的测试环境数据。V2版本中,理论上音乐码率大于1411kbps时才支持播放。而V3版本中,当下载速度大于播放速度时会导致水位上涨,一定会出现高于水位线情况。当网络出现卡顿时,缓存数据是高于水位线的,解码器依然可以拿到数据。
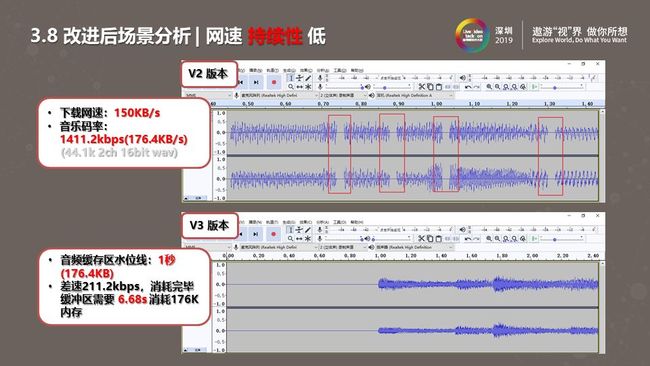
在另一种测试环境时,当下载速度一直低于播放速度。这是一种极端情况,下载达不到规定码率,无论如何播放都绝对不会流畅。V2版本中音频会一直间隔卡顿导致用户无法听清内容。在水位线机制中,当码率较低,缓存不够时是不会发出声音的,会有一秒的缓存时间,缓存过后播放的声音是较长时间连续的。,这样我们能够提升一定会卡顿情况下的用户体验,让在非常卡顿的网络情况下音频不再发出刺耳的噪音。
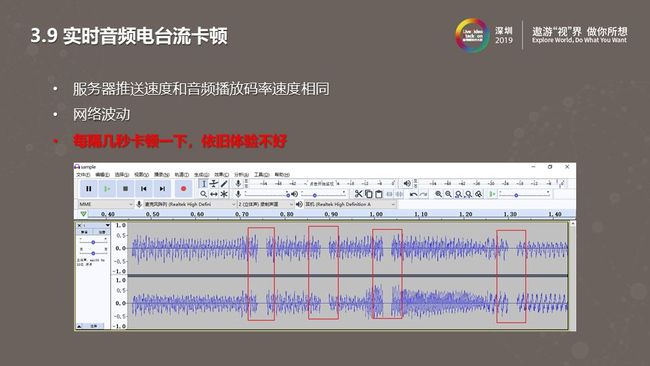
有时我们会播放一些相声、新闻等实时音频电台流内容。和音乐文件有一些不同,这时会出现推送流码率和播放流码率相同的情况。
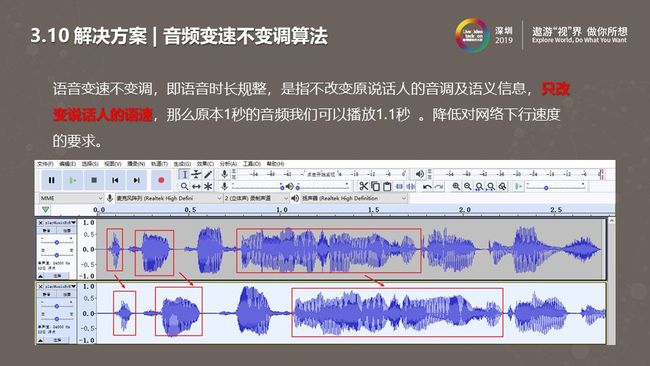
这种情况的解决涉及到变速不变调算法的使用,即我们会改变语音播放速度而不改变语义语调,改变较小时人耳不会听到差别。如上图我们做了测试。当下载码率与播放码率相同时,我们通过变速不变调算法降低音频的播放码率,下载速度会始终大于播放速度。如图中所示,虽然我们会进行缓存,但是由于下载速度较小,水位线涨不上去,依然会出现一定卡顿。经处理后,下载速度大于播放速度后,水位线会持续上涨,开始播放后便可以降低出现卡顿的情况。
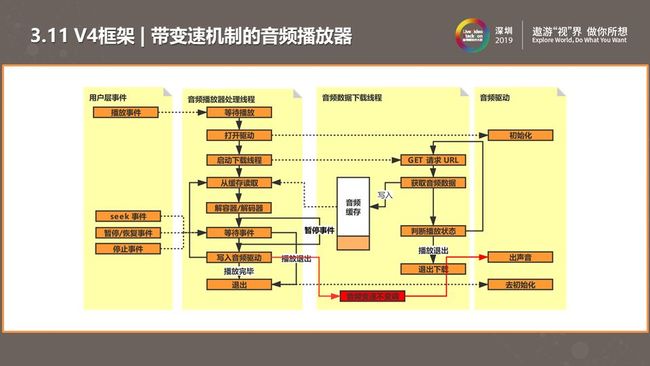
基于以上,我们完成了第四版的改进。我们在写入底层播放驱动前做对每一帧做变速不变调算法处理,当然这是可以选择开启的功能。

除了可以做变速不变调处理,我们还可以在相同位置EQ算法均衡器等其它处理,实现流行音乐音效、超低音音效等效果。
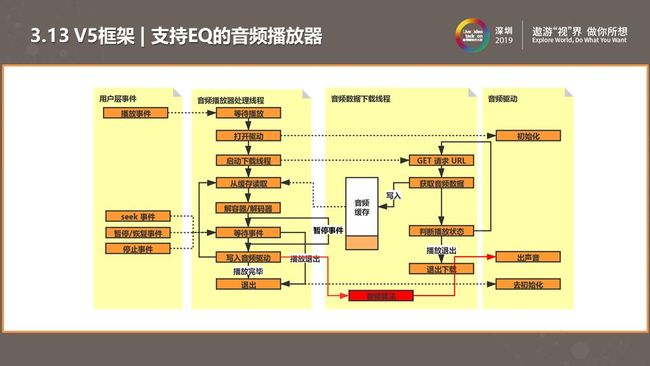
于是我们又做了一次改进。我们将变速不变调做了剥离,以插件的形式动态选择不同音效。

在智能音箱领域,客户会使用多种容器、协议以及编码格式。我们需要支持多种组合。
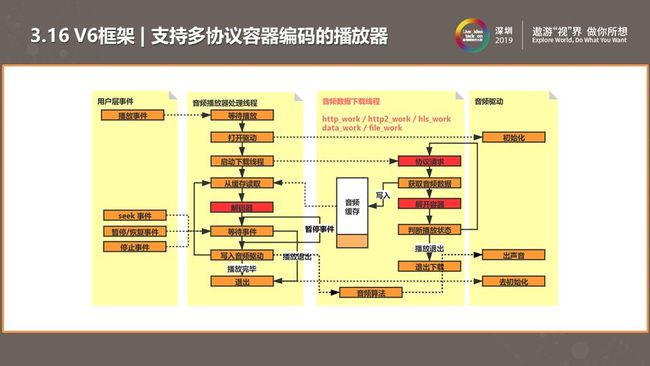
我们在原基础上做了改进,改进点如上图红色部分所示。在之前版本中,我们会将数据直接下载缓存到缓存区进行解码。改进后,我们将解码和解容器进行分离,在下载中加入了解容器,播放过程中解码。解容器以插件形式接入系统,在播放过程中探测它的格式,选用合适的容器解码格式。在这个过程中,不仅可以实现了多格式容器解码,也实现了多协议解码。我们将下载线程进行分类,针对不同协议做下载逻辑。将容器、协议、解码器剥离后,播放器框架可实现多种组合应用场景。
混音框架设计

接下来我将介绍智能音箱设计过程中遇到的另一个重要问题。如上图左侧部分,音箱服务器推送了一个音频,在播放过程中突然需要播放提示音,通常我们需要将音频暂停播放,插入提示音,播放完成后音频恢复播放。在这种情况下,设备需要维护播放状态的。如图中原始音频是44K,采样率是16K,中间有采样率切换的过程。切换采样率的过程中,需要注意它的实时性,因为我们控制内部芯片会产生一定时延。另一个就是pop音问题,当还有音频在播放时,切换采样率会有噪音出现。对此,我们做出了部分改进,采用混音的思路:将原音频音量降低,再采用混音的方式将提示音混入,提示音播放完成后恢复音频音量。这种思路不需要考虑播放器播放状态的维护,而且两路音频完全独立,开发者逻辑代码编写也清晰简单。
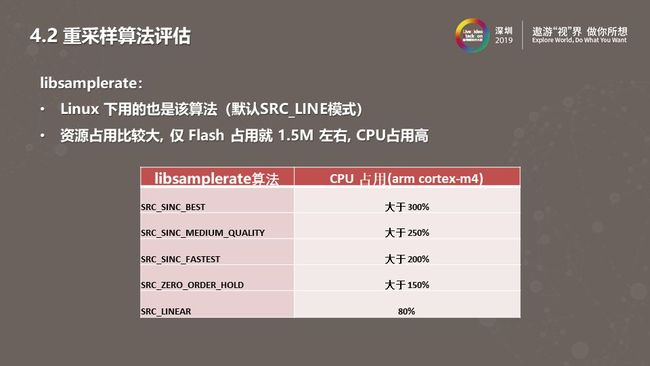
我们在做这个方案时评估了Linux下的一个成熟算法。算法采用了线性重采样算法。如上图,它的库里有五种模式,默认使用最低模式。我们使用ARM-CotexM4芯片做了测试,发现最多模式会占用百分之八十CPU。

libsamplerate算法输入的数据是浮点类型,使用此算法先将数据切为单精度浮点数,内部使用双精度浮点数做计算采样以确保采样效果。如图中48K音频采样耗费了115%CPU,重采样过程花费三百多秒。我们对此做了改进。我们对输入参数使用整形定点算法,这时占用CPU降到了79%。我们又将内部双精度浮点数强制降为单精度后,CPU占用率降到了49.5%。最终,我们做成了全整形数,这时CPU占用只有3.8%。另外,由于重采样算法由C语言写成,我们从汇编层面对它做了优化,之前的操作造成了采样效果变差,通过汇编优化将32位整型数改为了64位,整体效果虽不及浮点数,但整体效果提升了很多。

市面上主流混音算法模型有几种,第一种是两个声道数据直接加和,当某一通道的数据幅度较大时混音后任意出现音频数据溢出,从而音频失真。第二种是加和后再除以音道数防止溢出,这样会造成音道内音量衰减,并且音轨越多衰减越多。还有一种是加和箝位,即相加超过最大值时进行限幅,这样音频也会失真。另外还有饱和处理、归一化处理等。考虑到RTOS 方案应用场景是一个音轨音量高一个音量稍低,我们并需要两个声音同时听清,我们只需要保证一个音轨的质量。最终我们选择了图中第二种算法。虽然会产生一些衰减,但是在这个场景下只保证两个音道中一个声音清晰,衰减是可以忽略的。但是其它算法可能会出现失真,这是不能接受的。这种方案在实际应用中效果很好的。
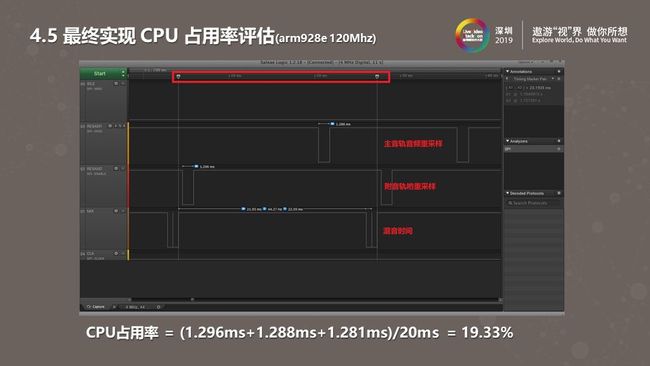
上图是我们测试结果。图中是一帧数据、20毫秒的窗口,我们做了重采样混音算法。优化过后,主音轨重采样耗了大概1.288毫秒,副音轨耗了1.296毫秒,混音用时1.281毫秒,在ARM9 120MHZ的系统中耗费了大概20%的CPU消耗。
LiveVideoStackCon 2020
上海/北京/旧金山 讲师招募
2020年LiveVideoStackCon将持续迭代,LiveVideoStackCon将分别在上海(6月13-14日),北京(9月11-12日)和旧金山(11月)举行。欢迎将你的技术实践、踩坑与填坑经历、技术与商业创业的思考分享出来,独乐不如众乐。请将个人资料和话题信息邮件到 [email protected] 或点击【阅读原文】了解成为LiveVideoStackCon讲师的权益与义务,我们会在48小时内回复。
