hashtable/hashmap/ConcurrentHashMap
一、HashTable
- 底层数组+链表实现,无论key还是value都不能为null,线程安全,实现线程安全的方式是在修改数据时synchronized锁住整个HashTable,效率低,ConcurrentHashMap做了相关优化
- 初始size为11,扩容:newsize = olesize*2+1
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length
二、HashMap
- 底层数组+链表实现,可以存储null键和null值,线程不安全
- 初始size为16,扩容:newsize = oldsize*2,size一定为2的n次幂
- 扩容针对整个Map,每次扩容时,原来数组中的元素依次重新计算存放位置,并重新插入
- 插入元素后才判断该不该扩容,有可能无效扩容(插入后如果扩容,如果没有再次插入,就会产生无效扩容)
- 当Map中元素总数超过Entry数组的75%,触发扩容操作,为了减少链表长度,元素分配更均匀
- 计算index方法:index = hash & (tab.length – 1)
HashMap的初始值还要考虑加载因子:
- 哈希冲突:若干Key的哈希值按数组大小取模后,如果落在同一个数组下标上,将组成一条Entry链,对Key的查找需要遍历Entry链上的每个元素执行equals()比较。
 注意:hash冲突的时候链表中的数据存放老的被放到链表的表尾部,新的放在链表的头部(靠近数组的地方。如上图的最上方)
注意:hash冲突的时候链表中的数据存放老的被放到链表的表尾部,新的放在链表的头部(靠近数组的地方。如上图的最上方)- 加载因子:为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。因此,如果预估容量是100,即需要设定100/0.75=134的数组大小。
- 空间换时间:如果希望加快Key查找的时间,还可以进一步降低加载因子,加大初始大小,以降低哈希冲突的概率。
- 补充:那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。
- hashMap高并发下的死循环,本质上SUN公司hashMap并不支持多线程,但是如果我们在多线程上使用了hashMap比较严重的情况会引发死循环,这个死循环是在数据插入的时候,多线程同时扩容,可能会出现循环链表,然后get的时候就会发生死循环。
HashMap和Hashtable都是用hash算法来决定其元素的存储,因此HashMap和Hashtable的hash表包含如下属性:
- 容量(capacity):hash表中桶的数量
- 初始化容量(initial capacity):创建hash表时桶的数量,HashMap允许在构造器中指定初始化容量
- 尺寸(size):当前hash表中记录的数量
- 负载因子(load factor):负载因子等于“size/capacity”。负载因子为0,表示空的hash表,0.5表示半满的散列表,依此类推。轻负载的散列表具有冲突少、适宜插入与查询的特点(但是使用Iterator迭代元素时比较慢)
除此之外,hash表里还有一个“负载极限”,“负载极限”是一个0~1的数值,“负载极限”决定了hash表的最大填满程度。当hash表中的负载因子达到指定的“负载极限”时,hash表会自动成倍地增加容量(桶的数量),并将原有的对象重新分配,放入新的桶内,这称为rehashing。
HashMap和Hashtable的构造器允许指定一个负载极限,HashMap和Hashtable默认的“负载极限”为0.75,这表明当该hash表的3/4已经被填满时,hash表会发生rehashing。
“负载极限”的默认值(0.75)是时间和空间成本上的一种折中:
- 较高的“负载极限”可以降低hash表所占用的内存空间,但会增加查询数据的时间开销,而查询是最频繁的操作(HashMap的get()与put()方法都要用到查询)
- 较低的“负载极限”会提高查询数据的性能,但会增加hash表所占用的内存开销
hashMap扩展:JDK 1.8
HashMap存储的是key-value的键值对,允许key为null,也允许value为null。HashMap内部为数组+链表的结构,会根据key的hashCode值来确定数组的索引(确认放在哪个桶里),如果遇到索引相同的key,桶的大小是2,如果一个key的hashCode是7,一个key的hashCode是3,那么他们就会被分到一个桶中(hash冲突),如果发生hash冲突,HashMap会将同一个桶中的数据以链表的形式存储,但是如果发生hash冲突的概率比较高,就会导致同一个桶中的链表长度过长,遍历效率降低,所以在JDK1.8中如果链表长度到达阀值(默认是8),就会将链表转换成红黑二叉树。
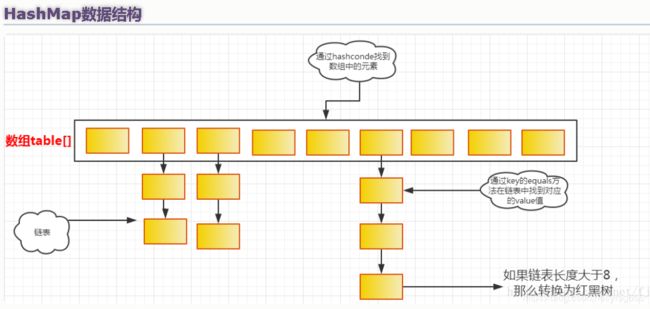
hashMap存储的时候首先是一个数组,然后每个数组的元素是一个Node类,Node本质是一个Map实现了Map.Entry接口,
三、ConcurrentHashMap
- 底层采用分段的数组+链表实现,线程安全
- 通过把整个Map分为N个Segment,可以提供相同的线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁
- 扩容:段内扩容(段内元素超过该段对应Entry数组长度的75%触发扩容,不会对整个Map进行扩容),插入前检测需不需要扩容,有效避免无效扩容
HashTable在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁。HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环,一旦成环,Entry的next节点永远不为空,产生死循环. ConcurrentHashMap所使用的锁分段技术, 首先将数据分成一段一段地存储 ,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。ConcurrentHashMap是由Segment数组和HashEntry数组组成. Segment是一种可重入锁,在ConcurrentHashMap里扮演锁的角色; HashEntry则用于存储键值对数据. 一个ConcurrentHashMap里包含一个Segment数组. Segment的结构和HashMap类似,是一种数组和链表结构. 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时, 必须首先获得与它对应的Segment锁。
在多线程并发访问一个共享变量时,为了保证逻辑的正确,可以采用以下方法:
- 加锁,性能最低,能保证原子性、可见性,防止指令重排;
- volatile修饰,性能中等,能保证可见性,防止指令重排;
- 使用getObjectVolatile,性能最好,可防止指令重排;currenthashmap的get()方法,ConcurrentHashMap选择了使用Unsafe的getObjectVolatile来读取segments中的元素
源码解析:segments是Segment的原生数组,其默认值为DEFAULT_CONCURRENCY_LEVEL=16 ,使用segment来锁定不同数据,那么我么读取数据时候又是怎么读取的呢额?
Segment的get操作实现非常简单和高效. - 先经过一次再散列
- 然后使用这个散列值通过散列运算定位到Segment - 再通过散列算法定位到元素.整个get方法不需要加锁,只需要计算两次hash值,然后遍历一个单向链表(此链表长度平均小于2),因此get性能很高。 高效之处在于整个过程不需要加锁,除非读到的值是空才会加锁重读. HashTable容器的get方法是需要加锁的,那ConcurrentHashMap的get操作是如何做到不加锁的呢?
原因是它的get方法将要使用的共享变量都定义成了volatile类型, 如用于统计当前Segement大小的count字段和用于存储值的HashEntry的value.定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值), 在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁. 之所以不会读到过期的值,是因为根据Java内存模型的happen before原则,对volatile字段的写操作先于读操作,即使两个线程同时修改和获取 volatile变量,get操作也能拿到最新的值, 这是用volatile替换锁的经典应用场景.
Segment的put操作,由于需要对共享变量进行写操作,所以为了线程安全,在操作共享变量时必须加锁.
put方法首先定位到Segment,然后在Segment里进行插入操作.
插入操作需要经历两个步骤
判断是否需要对Segment里的HashEntry数组进行扩容
定位添加元素的位置,然后将其放在HashEntry数组里
是否需要扩容
在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阈值,则对数组进行扩容.
值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容.
如何扩容
在扩容的时候,首先会创建一个容量是原来两倍的数组,然后将原数组里的元素进行再散列后插入到新的数组里.
为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment扩容.
Segment的size操作,要统计整个ConcurrentHashMap里元素的数量,就必须统计所有Segment里元素的数量后计总.
Segment里的全局变量count是一个volatile,在并发场景下,是不是直接把所有Segment的count相加就可以得到整个ConcurrentHashMap大小了呢?不是的,虽然相加时可以获取每个Segment的count的最新值,但是可能累加前使用的count发生了变化,那么统计结果就不准了. 所以,最安全的做法是在统计size的时候把所有Segment的put、remove和clean方法全部锁住,但是这种做法显然非常低效.因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以
ConcurrentHashMap的做法是先尝试2次通过不锁Segment的方式来统计各个Segment大小,如果统计的过程中,count发生了变化,则再采用加锁的方式来统计所有Segment的大小.那么ConcurrentHashMap又是如何判断在统计的时候容器是否发生了变化呢? 使用modCount变量,在put、remove和clean方法里操作元素前都会将变量modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化.
参考博客:
https://www.cnblogs.com/heyonggang/p/9112731.html
hashmap原理:https://blog.csdn.net/qq_37149569/article/details/82842365
hashMap原理讲解:https://www.cnblogs.com/williamjie/p/9358291.html
currentHashMap:https://blog.csdn.net/qq_33589510/article/details/79962152