字体反爬之猫眼电影
暑假如约而至,暑期档电影究竟是谁能脱颖而出呢?
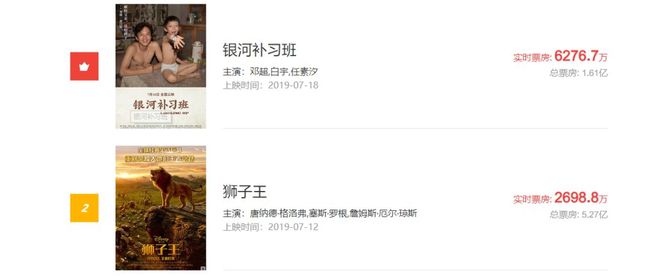
目前看来是刚上映的银河补习班热度最高。但最后鹿死谁手还尚未可知,我们可以通过爬取猫眼的实时票房数据来一看究竟。

通过观察网页源代码,我们发现,票房的数字变成了.而不是我们在网页上看到的6276.7。这个网站采取了字体反爬,这也是一种常见的反爬技术。网站采用了自定义的字体文件,内容能够在浏览器上正常显示,但是爬取的数据就变成了乱码,如同下图的小方框。
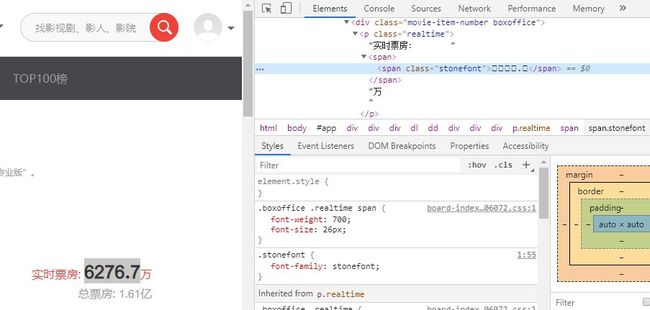
采用自定义字体文件是CSS3的新特性,CSS3 @font-face中定义了字体,这个自定义字体文件存放到 web 服务器上,它会在需要时被自动下载到用户的计算机上,以便我们在访问网页时渲染出字体。
我们可以利用fontTools这个第三方库,来对这些字体文件进行操作。
from fontTools.ttLib import TTFont
font_1 = TTFont('a.woff')
font_1.saveXML('font_1.xml')
我们可以在xml中查看这个字体文件。也可以利用百度字体编辑器,导入相应woff文档,便能够查看对应字体。

既然如此,那我们只要建立相应的映射关系,不就能解密字体了吗?easy~

经过观察发现,该字体文件每刷新一次页面都会发生更新,其name随着字体文件的变化而变化,这就令人有些头大了。

别着急,我们来看看这个xml页面吧。借助百度字体编辑器,发现这个F496代表的是4,而另外一个字体文件中的E603代表的是4。

我们在第一个xml中找到4,也就是F496,在第二个xml中也找4,即E603。


我们惊喜的发现这两个不同字体文件中对4的描述是完全一致的,仅仅是不同的字体文件它对4的命名不同,同时观察其他数字也能得到相同的结论。这样我们就找到了问题的关键,只要TTGlyph对象相同,它所表示的就是相同的数字。
我们可以先在本地存放一个base字体文件,这个字体文件中我们通过百度字体编辑器得到了一一对应关系。
font1=TTFont('./fonts/base.woff')
base_dict={'uniE18E': '3', 'uniE585': '2', 'uniE194': '9', 'uniF439': '4', 'uniE7DB': '7','uniF115': '0',
'uniF0A4': '5', 'uniE311': '1', 'uniF7EF': '8', 'uniEACB': '6'}
再利用正则表达式从网页中下载到新的字体文件,并通过相同的字体对象构造新的映射关系,即新字体文件中定义的对象名与真实代表数字之间的对应关系。
response=requests.get(url,headers).text
# 正则匹配字体woff文件
font_file=re.findall(r'vfile\.meituan\.net\/colorstone\/(\w+\.woff)', response)[0]
url2='http://vfile.meituan.net/colorstone/' + font_file
new_file=requests.get(url2,headers)
with open('./fonts/'+font_file,'wb') as f:
f.write(new_file.content)
font2=TTFont('./fonts/'+font_file)
# font2.saveXML('font_2.xml')
# 获取字符的name列表
name_list2=font2.getGlyphNames()[1:-1]
new_dict={}
for name2 in name_list2:
obj2=font2['glyf'][name2]
for name1 in name_list1:
obj1=font1['glyf'][name1]
# 对象相等则说明对应的数字相同
if obj1==obj2:
new_dict[name2]=base_dict[name1]
在解决了字体反爬的问题之后,我们能利用requests库和各种解析的库在页面源代码中提取我们想要的信息了。
def get_info(response):
'''
输入:页面源码
输出:包含电影票房等信息的字典列表
'''
# Mongo配置
conn=MongoClient('127.0.0.1', 27017)
db=conn.maoyan #连接maoyan数据库,没有则自动创建
mongo_my=db.film #使用film集合,没有则自动创建
items=[]
tree=etree.HTML(response)
film_name=tree.xpath('//div[@class="movie-item-info"]/p/a/text()')
booking_office_today=tree.xpath('//div[@class="movie-item-number boxoffice"]/p[@class="realtime"]/span/span/text()')
booking_office_total=tree.xpath('//div[@class="movie-item-number boxoffice"]/p[@class="total-boxoffice"]/span/span/text()')
a=tree.xpath('//div[@class="movie-item-number boxoffice"]/p[@class="realtime"]/text()')[1::2]
b=tree.xpath('//div[@class="movie-item-number boxoffice"]/p[@class="total-boxoffice"]/text()')[1::2]
for i in range(len(film_name)):
item={'film_name':film_name[i],
'booking_office_today':booking_office_today[i]+a[i].replace('\n',''),
'booking_office_total':booking_office_total[i]+b[i].replace('\n',''),
}
items.append(item)
mongo_my.insert_one(item)
return items
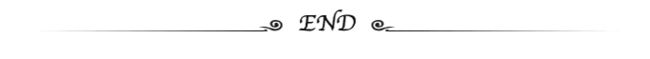
本文全部代码已上传至后台,详情请回复“猫眼”
喜欢就点个赞吧❤