简单爬取评论
刚刚开始学习python网络爬虫,利用requests库及BeautifulSoup对某网上某酒店的评论进行了简单的抓取。网页情况如下所示:
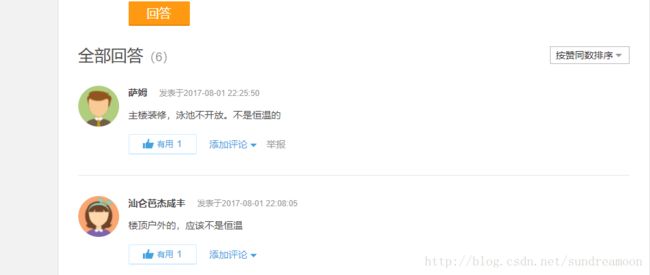
通过查看网页源代码,发现评论者的名称及评论内容分别在a标签及p标签下,因此对a标签及p标签进行遍历。
 遍历代码如下:
遍历代码如下:

整个代码的逻辑参考中国大学排名爬虫实例(北京理工大学教程),程序代码如下所示:
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillList(ulist1, ulist2, html):
soup = BeautifulSoup(html,"html.parser")
a = soup.find_all('a')
p = soup.find_all('p')
for i in a:
try:
if i.attrs['class']==['answer_id']:
name = i.text
ulist1.append(name)
except:
continue
for j in p:
try:
if j.attrs['class']==['answer_text']:
remark = j.text
ulist2.append(remark)
except:
continue
def printList(ulist1, ulist2, num):
print("{:^10}\t{:^10}".format("评论者","评论内容"))
for i in range(num):
print("{:^10}\t{:^10}".format(ulist1[i],ulist2[i]))
def main():
uname = []
uremark = []
url = 'http://you.ctrip.com/asks/zhuhai27/4597548.html'
html = getHTMLText(url)
fillList(uname, uremark, html)
printList(uname, uremark, 5)
main()
程序运行结果如图所示:
