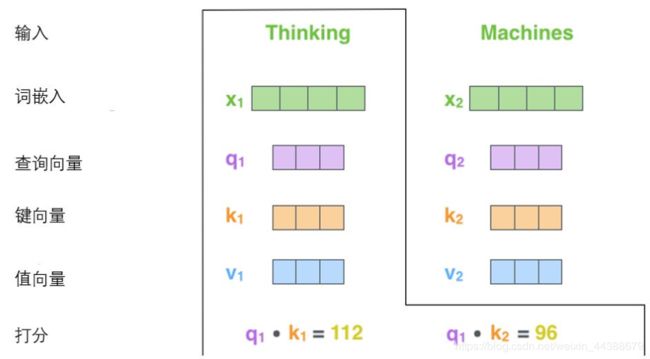
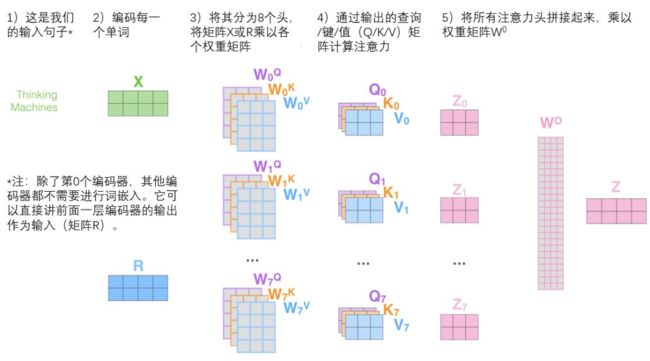
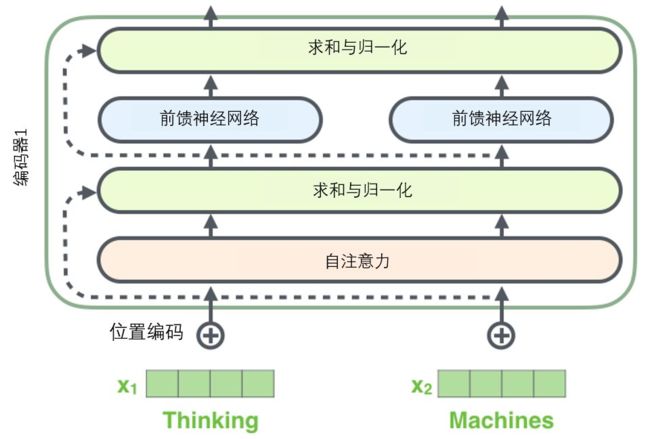
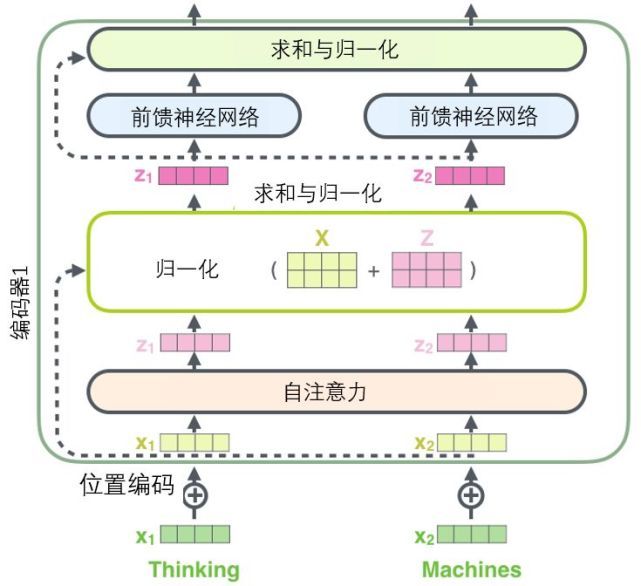
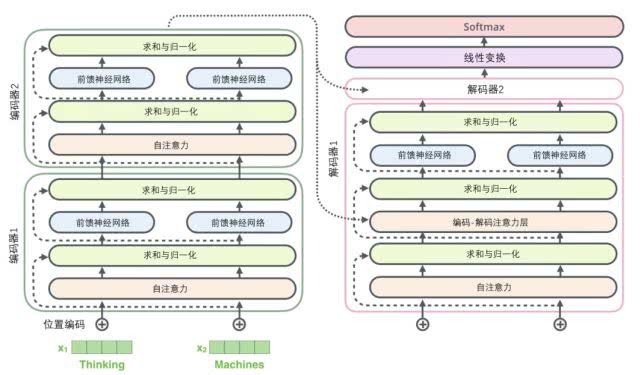
- 从API到Agent:万字洞悉LangChain工程化设计
bpluo42657
langchain
——构建下一代AI应用的核心范式迁移一、传统API范式的局限性:为什么需要Agent?接口式AI的痛点python#传统NLPAPI调用示例response=openai.Completion.create(model="text-davinci-003",prompt="请翻译:Helloworld",max_tokens=50)单次请求/响应模式缺乏状态管理与上下文延续硬编码逻辑难以应对复杂场
- 利用 Python 爬取小红书热门笔记并进行标签关键词分析
程序员威哥
最新爬虫实战项目python笔记开发语言
一、背景与目标小红书(RED)作为中国最活跃的内容社区之一,拥有大量关于美妆、穿搭、美食、旅游等领域的用户生成内容(UGC)。对于产品、品牌方或研究人员来说,提取热门笔记的标签关键词,可以有效捕捉用户关注点、消费趋势及内容热词。本项目目标:使用Python爬取小红书某个话题下的热门笔记;分析每篇笔记中的标题、正文、标签等字段;利用NLP技术提取高频关键词;对关键词进行可视化与聚类分析。二、技术难点
- 在NLP深层语义分析中,深度学习和机器学习的区别与联系
在自然语言处理(NLP)的深层语义分析任务中,深度学习与机器学习的区别和联系主要体现在以下方面:一、核心区别特征提取方式机器学习:依赖人工设计特征(如词频、句法规则、TF-IDF等),需要领域专家对文本进行结构化处理。例如,传统情感分析需人工定义“情感词库”或通过词性标注提取关键成分。深度学习:通过神经网络自动学习多层次特征。例如,BERT等模型可从原始文本中捕获词向量、句法关系甚至篇章级语义,无
- 敏捷开发中的自然语言处理集成
项目管理实战手册
项目管理最佳实践敏捷流程自然语言处理easyuiai
敏捷开发中的自然语言处理集成:让代码与需求“说人话”关键词:敏捷开发、自然语言处理(NLP)、用户故事分析、需求自动化、持续集成优化摘要:在敏捷开发中,“快速响应变化”的核心目标常被繁琐的文本处理拖慢——需求文档像“天书”、用户故事靠“脑补”、缺陷报告整理耗时……自然语言处理(NLP)就像一位“智能翻译官”,能让开发团队与需求文档“流畅对话”。本文将用“搭积木”“翻译机”等生活化比喻,带您理解如何
- 甘超波:NLP中EMBA状态管理
甘超波
哈喽,大家好我是甘超波,一名NLP爱好者,每天一篇文章,分享我的NLP实战经验和案例,希望给你些启发和帮助,这是第23篇原创文章什么是EMBAEMBA:是总裁班吗?在NLP中EMBA指的一种状态管理,我们NLP所有技巧都是在EMBA中展开的,像催眠,潜意识沟通......等都是在基于EMBA。如果把NLP比作一个楼房,EMBA就是楼房的地基如果把NLP比作一个汽车,EMBA就是汽车的发动机。其中E
- 打造智能资讯引擎:基于 Python 的新闻数据爬取与个性化推荐系统实战全流程解析
程序员威哥
最新爬虫实战项目python开发语言
前言:数据时代的信息洪流,如何做到“千人千面”?在信息爆炸的时代,每天都有成千上万条新闻资讯涌现。如何从海量内容中挖掘出用户感兴趣的资讯?这不仅仅是爬虫技术的问题,更是数据建模与智能推荐算法的落地挑战。本篇文章将带你从零出发,构建一个具有实际应用价值的“个性化新闻阅读推荐系统”,从数据采集(爬虫)、文本处理(NLP)、兴趣建模(TF-IDF/协同过滤/Embedding)到推荐展示,覆盖整个推荐系
- 题解 | #使用join查询找出没有分类的电影id以及名称#
愤怒的小青春
java
58同城java后端一面凉经主流的哈希算法有哪几种?帮闺蜜们找靠谱男票hc多多光彩积云是什么企业,查不到有用信息太抽象了!培训班装公司招聘阿里巴巴前端暑期实习——无语八面挂怎么写自我介绍|自我介绍保姆级教学灵犀互娱客户端一面面经(求过啊)24找运维实习,这简历可行吗拓竹科技测试开发面经(25届暑期实习)分享一波攒了整个秋招的NLP算法岗面经腾讯广告暑期实习面试1、JVM垃圾回收机制2、syncho
- 进阶向:基于Python的智能客服系统设计与实现
智能客服系统开发指南系统概述智能客服系统是人工智能领域的重要应用,它通过自然语言处理(NLP)和机器学习技术自动化处理用户查询,显著提升客户服务效率和响应速度。基于Python的实现方案因其丰富的生态系统(如NLTK、spaCy、Transformers等库)、跨平台兼容性以及易于集成的特点,成为开发智能客服系统的首选。系统架构系统核心包括两个主要功能模块:1.API集成模块负责连接各类外部服务,
- 计算机视觉产品推荐,个性化推荐:人工智能中的计算机视觉、NLP自然语言处理和个性化推荐系统哪个前景更好一些?...
这个问题直接回答的话可能还是有着很强的个人观点,所以不如先向你介绍一些这几个领域目前的研究现状和应用情况(不再具体介绍其中原理)你自己可以斟酌一下哪方面更适合自己个性化推荐。一.所谓计算机视觉,是指使用计算机及相关设备对生物视觉的一种模拟个性化推荐。它的主要任务就是通过对采集的图片或视频进行处理以获得相应场景的三维信息,就像人类和许多其他类生物每天所做的那样[1]。现在人工智能的计算机视觉主要研究
- 【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts) 视频教程 - 基于wordcloud库实现词云图
大家好,我是java1234_小锋老师,最近写了一套【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts)视频教程,持续更新中,计划月底更新完,感谢支持。今天讲解基于wordcloud库实现词云图视频在线地址:2026版【NLP舆情分析】基于python微博舆情分析可视化系统(flask+pandas+echarts+爬虫)视频教程(火爆连载更新中..
- 大模型算法工程师技术路线全解析:从基础到资深的能力跃迁
Mr.小海
大模型算法数据挖掘人工智能机器学习深度学习机器翻译web3
文章目录大模型算法工程师技术路线全解析:从基础到资深的能力跃迁一、基础阶段(0-2年经验):构建核心知识体系与工程入门数学与机器学习基础编程与深度学习框架NLP与Transformer入门二、进阶阶段(2-4年经验):深化模型技术与工程落地能力大模型预训练与微调技术预训练原理:数据与任务的协同设计微调工具:参数高效适配与工程优化对齐实践:价值观优化与实证效果分布式训练与框架工具并行策略:多维度协同
- 丰盛日记第三天
幸运星小燕子
第123期NLP执行师二阶4组章艳Day3分享《有效引导他人的能力》学到情绪管理的方法和体验练习中感动的一天,我很开心!1、复习大脑结构:由原始脑、情绪脑、皮质层三部分组成;三部分需要充分配合和相互制约,考虑三赢后,才能做出正确的决定。2、情绪体验小游戏:树和松鼠,让我们提醒不同的情绪感受。3、处理情绪的四个方法:思维、体能、环境、关系;导师建议可以使用呼吸放松法,使自己的情绪可以及时的醒觉→_→
- 【转】【译】How to Handle Very Long Sequences with LSTM(LSTM RNN 超长序列处理)
开始奋斗的胖子
机器学习RNNLSTM序列深度学习
原文地址http://machinelearningmastery.com/handle-long-sequences-long-short-term-memory-recurrent-neural-networks/一个长的输入序列却只对应一个或者一小段输出就是我们经常说的序列标注和序列分类。主要包括下面一些例子:包含上千个词的文件情感分类(NLP)包含上千个时间状态的脑电痕迹分类(Medici
- “闭门造车”之多模态思路浅谈:自回归学习与生成
PaperWeekly
回归学习数据挖掘人工智能机器学习
©PaperWeekly原创·作者|苏剑林单位|科学空间研究方向|NLP、神经网络这篇文章我们继续来闭门造车,分享一下笔者最近对多模态学习的一些新理解。在前文《“闭门造车”之多模态思路浅谈:无损》中,我们强调了无损输入对于理想的多模型模态的重要性。如果这个观点成立,那么当前基于VQ-VAE、VQ-GAN等将图像离散化的主流思路就存在能力瓶颈,因为只需要简单计算一下信息熵就可以表明离散化必然会有严重
- 自动字幕生成器:Auto-Subtitle — 技术解析与应用指南
房耿园Hartley
自动字幕生成器:Auto-Subtitle—技术解析与应用指南在视频内容日益丰富的今天,自动字幕生成工具变得越来越重要,尤其是对于听障人士、非母语者和在嘈杂环境下观看视频的人来说。Auto-Subtitle是一个开源项目,它利用先进的自然语言处理(NLP)技术为你的视频自动生成准确的字幕。本文将深入探讨这个项目的原理、功能、应用场景及特点,以期吸引更多开发者和用户关注并使用。项目简介Auto-Su
- 略说NLP引入公理模型的可行性
金井PRATHAMA
知识图谱与NLP自然语言处理人工智能知识图谱
在自然语言处理(NLP)的深层语义分析中,公理化体系的引入具有理论可行性,但其实际应用仍面临挑战。以下从公理模型的设计思路、关键技术要点及注意事项三个方面展开分析,结合搜索结果的多个相关技术点进行综合说明:一、公理模型在深层语义分析中的设计思路公理的定义与语义形式化公理模型需以形式化逻辑为基础,定义语义分析中的原始概念(如谓词、实体、关系)和推理规则。例如:原始概念:将语义角色(如施事者、受事者)
- NLP中情感分析如何结合知识图谱在跨文化领域提升观念分析和价值判断的准确性?
情感分析结合知识图谱,能够显著提升观念分析和价值判断的准确性。这一融合的核心在于利用知识图谱的结构化语义网络,为情感分析提供深层语境、实体关联和领域知识支撑。以下是具体机制和应用场景的分析:一、知识图谱如何提升情感分析的语义理解1.解决歧义与上下文依赖问题:情感词(如“冷”)在不同语境中含义不同(“服务态度冷”表负面,“冷静分析”表中性)。方案:知识图谱通过实体链接识别文本中的对象(如“服务态度”
- SBERT、CoSENT和BETR以及transformers的区别和联系
panshengnan
NLPnlptransformer
SBERT、CoSENT、BETR和Transformers的区别和联系这几个模型(SBERT、CoSENT、BETR)和框架(Transformers)都是围绕自然语言处理(NLP)的句子嵌入和语义理解任务展开的。它们的联系主要在于基于Transformer架构,并针对特定任务做了优化;区别则在于目标任务、优化策略、训练方法和适用场景等方面。1.联系基于Transformer架构:它们的核心编码
- 入门大模型神器:开源项目Happy LLM保姆级教程!
Happy-LLMHappy-LLM——从零开始的大语言模型原理与实践教程。本项目是一个系统性的LLM学习教程,将从NLP的基本研究方法出发,根据LLM的思路及原理逐层深入,依次为读者剖析LLM的架构基础和训练过程。同时,我们会结合目前LLM领域最主流的代码框架,演练如何亲手搭建、训练一个LLM,期以实现授之以鱼,更授之以渔。希望大家能从这本书开始走入LLM的浩瀚世界,探索LLM的无尽可能。特点•
- 【原创】下雨天要游泳
饶金霞家庭教育心理咨询
下午,我照着昨天与小儿的约定,在四点半,就来到幼儿园门口接孩子。老师打开大门,孩子从教室里走出来,一见到我就问:“老妈,泳衣准备好了吗?”我半蹲下来拥抱他说:“都放在车上啦!”儿子在我额头上亲一口说:“你真是世界上最讲信用的好妈妈!”我有点怀疑我这儿子有NLP的基因,总是能及时地给沟通者作出良好的回应,而且还会用米尔顿。其实看着这满天的乌云,我心里还在嘀咕,这场大雨可能不会等到我们去游泳场。果不其
- LLM系统性学习完全指南(初学者必看系列)
GA琥珀
LLM学习人工智能语言模型
前言这篇文章将系统性的讲解LLM(LargeLanguageModels,LLM)的知识和应用。我们将从支撑整个领域的数学与机器学习基石出发,逐步剖析自然语言处理(NLP)的经典范式,深入探究引发革命的Transformer架构,并按时间顺序追溯从BERT、GPT-2到GPT-4、Llama及Gemini等里程碑式模型的演进。随后,我们将探讨如何将这些强大的基础模型转化为实用、安全的应用,涵盖对齐
- AI数字人系统开发上线全攻略:从0到1全流程解析
v_qutudy
人工智能AI系统开发AI数字人开发
一、需求分析:定义数字人核心能力1.1功能规划矩阵模块基础功能进阶功能形象生成2D/3D建模实时表情捕捉与驱动语音交互TTS语音合成情感识别与应激反应动作系统预设动作库骨骼动画与物理引擎智能决策规则引擎强化学习驱动决策多模态交互文本/语音输入AR/VR空间交互1.2非功能性指标实时性:唇形同步延迟B[语音识别]A-->C[姿态检测]A-->D[文本理解]B-->E[NLP引擎]C-->F[动作解析
- Java NLP炼金术:从词袋到深度学习,构建AI时代的语言魔方
墨夶
Java学习资料人工智能java自然语言处理
一、JavaNLP的“三剑客”:框架与工具链1.1ApacheOpenNLP:传统NLP的“瑞士军刀”目标:用词袋模型实现文本分类与实体识别代码实战:文档分类器的“炼成术”//OpenNLP文档分类器(基于词袋模型)importopennlp.tools.doccat.*;importopennlp.tools.util.*;publicclassDocumentClassifier{//训练模型
- 深度学习模型表征提取全解析
ZhangJiQun&MXP
教学2024大模型以及算力2021AIpython深度学习人工智能pythonembedding语言模型
模型内部进行表征提取的方法在自然语言处理(NLP)中,“表征(Representation)”指将文本(词、短语、句子、文档等)转化为计算机可理解的数值形式(如向量、矩阵),核心目标是捕捉语言的语义、语法、上下文依赖等信息。自然语言表征技术可按“静态/动态”“有无上下文”“是否融入知识”等维度划分一、传统静态表征(无上下文,词级为主)这类方法为每个词分配固定向量,不考虑其在具体语境中的含义(无法解
- 【AI大模型】LLM模型架构深度解析:BERT vs. GPT vs. T5
我爱一条柴ya
学习AI记录ai人工智能AI编程python
引言Transformer架构的诞生(Vaswanietal.,2017)彻底改变了自然语言处理(NLP)。在其基础上,BERT、GPT和T5分别代表了三种不同的模型范式,主导了预训练语言模型的演进。理解它们的差异是LLM开发和学习的基石。一、核心架构对比特性BERT(BidirectionalEncoder)GPT(GenerativePre-trainedTransformer)T5(Text
- NLP_知识图谱_大模型——个人学习记录
macken9999
自然语言处理知识图谱大模型自然语言处理知识图谱学习
1.自然语言处理、知识图谱、对话系统三大技术研究与应用https://github.com/lihanghang/NLP-Knowledge-Graph深度学习-自然语言处理(NLP)-知识图谱:知识图谱构建流程【本体构建、知识抽取(实体抽取、关系抽取、属性抽取)、知识表示、知识融合、知识存储】-元気森林-博客园https://www.cnblogs.com/-402/p/16529422.htm
- 数据安全审计平台的三大关键技术:日志分析、行为监测与智能告警
KKKlucifer
安全算法
在数字化浪潮中,数据安全审计是企业守护核心资产的“瞭望塔”。通过日志分析、行为监测、智能告警三大技术,数据安全审计平台构建起“全流程监控-异常识别-快速响应”的闭环,为数据安全筑牢防线。以下从技术原理、实践价值与行业应用展开解析。日志分析:数据安全的“DNA图谱”1.多源日志融合技术实现:通过Agent采集操作系统、数据库、网络设备等200+日志源,利用正则表达式、NLP技术解析非结构化日志(如“
- 【论文阅读笔记】TimesURL: Self-supervised Contrastive Learning for Universal Time Series
少写代码少看论文多多睡觉
#论文阅读笔记论文阅读笔记
TimesURL:Self-supervisedContrastiveLearningforUniversalTimeSeriesRepresentationLearning摘要 学习适用于多种下游任务的通用时间序列表示,并指出这在实际应用中具有挑战性但也是有价值的。最近,研究人员尝试借鉴自监督对比学习(SSCL)在计算机视觉(CV)和自然语言处理(NLP)中的成功经验,以解决时间序列表示的问题。
- NLP-D7-李宏毅机器学习---X-Attention&&GAN&BERT&GPT
甄小胖
机器学习自然语言处理机器学习bert
—0521今天4:30就起床了!真的是迫不及待想看新的课程!!!昨天做人脸识别系统的demo查资料的时候,发现一个北理的大四做cv的同学,差距好大!!!我也要努力呀!!不是比较,只是别人可以做到这个程度,我也一定可以!!!要向他学习!!!开始看课程啦!-----0753看完了各种attention,由于attention自己计算的限制,当N很大的时候会产生计算速度问题,从各种不同角度(人工知识输入
- PyTorch 在 Python 自然语言处理中的运用
Python编程之道
Python编程之道pythonpytorch自然语言处理ai
PyTorch在Python自然语言处理中的运用关键词:PyTorch,Python,自然语言处理,深度学习,文本分类,情感分析摘要:本文全面探讨了PyTorch在Python自然语言处理(NLP)领域的运用。首先介绍了相关背景知识,包括目的范围、预期读者等内容。接着详细阐述了核心概念,如词嵌入、循环神经网络等,并给出了相应的原理示意图和流程图。深入讲解了核心算法原理,结合Python代码进行详细
- 遍历dom 并且存储(将每一层的DOM元素存在数组中)
换个号韩国红果果
JavaScripthtml
数组从0开始!!
var a=[],i=0;
for(var j=0;j<30;j++){
a[j]=[];//数组里套数组,且第i层存储在第a[i]中
}
function walkDOM(n){
do{
if(n.nodeType!==3)//筛选去除#text类型
a[i].push(n);
//con
- Android+Jquery Mobile学习系列(9)-总结和代码分享
白糖_
JQuery Mobile
目录导航
经过一个多月的边学习边练手,学会了Android基于Web开发的毛皮,其实开发过程中用Android原生API不是很多,更多的是HTML/Javascript/Css。
个人觉得基于WebView的Jquery Mobile开发有以下优点:
1、对于刚从Java Web转型过来的同学非常适合,只要懂得HTML开发就可以上手做事。
2、jquerym
- impala参考资料
dayutianfei
impala
记录一些有用的Impala资料
1. 入门资料
>>官网翻译:
http://my.oschina.net/weiqingbin/blog?catalog=423691
2. 实用进阶
>>代码&架构分析:
Impala/Hive现状分析与前景展望:http
- JAVA 静态变量与非静态变量初始化顺序之新解
周凡杨
java静态非静态顺序
今天和同事争论一问题,关于静态变量与非静态变量的初始化顺序,谁先谁后,最终想整理出来!测试代码:
import java.util.Map;
public class T {
public static T t = new T();
private Map map = new HashMap();
public T(){
System.out.println(&quo
- 跳出iframe返回外层页面
g21121
iframe
在web开发过程中难免要用到iframe,但当连接超时或跳转到公共页面时就会出现超时页面显示在iframe中,这时我们就需要跳出这个iframe到达一个公共页面去。
首先跳转到一个中间页,这个页面用于判断是否在iframe中,在页面加载的过程中调用如下代码:
<script type="text/javascript">
//<!--
function
- JAVA多线程监听JMS、MQ队列
510888780
java多线程
背景:消息队列中有非常多的消息需要处理,并且监听器onMessage()方法中的业务逻辑也相对比较复杂,为了加快队列消息的读取、处理速度。可以通过加快读取速度和加快处理速度来考虑。因此从这两个方面都使用多线程来处理。对于消息处理的业务处理逻辑用线程池来做。对于加快消息监听读取速度可以使用1.使用多个监听器监听一个队列;2.使用一个监听器开启多线程监听。
对于上面提到的方法2使用一个监听器开启多线
- 第一个SpringMvc例子
布衣凌宇
spring mvc
第一步:导入需要的包;
第二步:配置web.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<web-app version="2.5"
xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi=
- 我的spring学习笔记15-容器扩展点之PropertyOverrideConfigurer
aijuans
Spring3
PropertyOverrideConfigurer类似于PropertyPlaceholderConfigurer,但是与后者相比,前者对于bean属性可以有缺省值或者根本没有值。也就是说如果properties文件中没有某个bean属性的内容,那么将使用上下文(配置的xml文件)中相应定义的值。如果properties文件中有bean属性的内容,那么就用properties文件中的值来代替上下
- 通过XSD验证XML
antlove
xmlschemaxsdvalidationSchemaFactory
1. XmlValidation.java
package xml.validation;
import java.io.InputStream;
import javax.xml.XMLConstants;
import javax.xml.transform.stream.StreamSource;
import javax.xml.validation.Schem
- 文本流与字符集
百合不是茶
PrintWrite()的使用字符集名字 别名获取
文本数据的输入输出;
输入;数据流,缓冲流
输出;介绍向文本打印格式化的输出PrintWrite();
package 文本流;
import java.io.FileNotFound
- ibatis模糊查询sqlmap-mapping-**.xml配置
bijian1013
ibatis
正常我们写ibatis的sqlmap-mapping-*.xml文件时,传入的参数都用##标识,如下所示:
<resultMap id="personInfo" class="com.bijian.study.dto.PersonDTO">
<res
- java jvm常用命令工具——jdb命令(The Java Debugger)
bijian1013
javajvmjdb
用来对core文件和正在运行的Java进程进行实时地调试,里面包含了丰富的命令帮助您进行调试,它的功能和Sun studio里面所带的dbx非常相似,但 jdb是专门用来针对Java应用程序的。
现在应该说日常的开发中很少用到JDB了,因为现在的IDE已经帮我们封装好了,如使用ECLI
- 【Spring框架二】Spring常用注解之Component、Repository、Service和Controller注解
bit1129
controller
在Spring常用注解第一步部分【Spring框架一】Spring常用注解之Autowired和Resource注解(http://bit1129.iteye.com/blog/2114084)中介绍了Autowired和Resource两个注解的功能,它们用于将依赖根据名称或者类型进行自动的注入,这简化了在XML中,依赖注入部分的XML的编写,但是UserDao和UserService两个bea
- cxf wsdl2java生成代码super出错,构造函数不匹配
bitray
super
由于过去对于soap协议的cxf接触的不是很多,所以遇到了也是迷糊了一会.后来经过查找资料才得以解决. 初始原因一般是由于jaxws2.2规范和jdk6及以上不兼容导致的.所以要强制降为jaxws2.1进行编译生成.我们需要少量的修改:
我们原来的代码
wsdl2java com.test.xxx -client http://.....
修改后的代
- 动态页面正文部分中文乱码排障一例
ronin47
公司网站一部分动态页面,早先使用apache+resin的架构运行,考虑到高并发访问下的响应性能问题,在前不久逐步开始用nginx替换掉了apache。 不过随后发现了一个问题,随意进入某一有分页的网页,第一页是正常的(因为静态化过了);点“下一页”,出来的页面两边正常,中间部分的标题、关键字等也正常,唯独每个标题下的正文无法正常显示。 因为有做过系统调整,所以第一反应就是新上
- java-54- 调整数组顺序使奇数位于偶数前面
bylijinnan
java
import java.util.Arrays;
import java.util.Random;
import ljn.help.Helper;
public class OddBeforeEven {
/**
* Q 54 调整数组顺序使奇数位于偶数前面
* 输入一个整数数组,调整数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半
- 从100PV到1亿级PV网站架构演变
cfyme
网站架构
一个网站就像一个人,存在一个从小到大的过程。养一个网站和养一个人一样,不同时期需要不同的方法,不同的方法下有共同的原则。本文结合我自已14年网站人的经历记录一些架构演变中的体会。 1:积累是必不可少的
架构师不是一天练成的。
1999年,我作了一个个人主页,在学校内的虚拟空间,参加了一次主页大赛,几个DREAMWEAVER的页面,几个TABLE作布局,一个DB连接,几行PHP的代码嵌入在HTM
- [宇宙时代]宇宙时代的GIS是什么?
comsci
Gis
我们都知道一个事实,在行星内部的时候,因为地理信息的坐标都是相对固定的,所以我们获取一组GIS数据之后,就可以存储到硬盘中,长久使用。。。但是,请注意,这种经验在宇宙时代是不能够被继续使用的
宇宙是一个高维时空
- 详解create database命令
czmmiao
database
完整命令
CREATE DATABASE mynewdb USER SYS IDENTIFIED BY sys_password USER SYSTEM IDENTIFIED BY system_password LOGFILE GROUP 1 ('/u01/logs/my/redo01a.log','/u02/logs/m
- 几句不中听却不得不认可的话
datageek
1、人丑就该多读书。
2、你不快乐是因为:你可以像猪一样懒,却无法像只猪一样懒得心安理得。
3、如果你太在意别人的看法,那么你的生活将变成一件裤衩,别人放什么屁,你都得接着。
4、你的问题主要在于:读书不多而买书太多,读书太少又特爱思考,还他妈话痨。
5、与禽兽搏斗的三种结局:(1)、赢了,比禽兽还禽兽。(2)、输了,禽兽不如。(3)、平了,跟禽兽没两样。结论:选择正确的对手很重要。
6
- 1 14:00 PHP中的“syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM”错误
dcj3sjt126com
PHP
原文地址:http://www.kafka0102.com/2010/08/281.html
因为需要,今天晚些在本机使用PHP做些测试,PHP脚本依赖了一堆我也不清楚做什么用的库。结果一跑起来,就报出类似下面的错误:“Parse error: syntax error, unexpected T_PAAMAYIM_NEKUDOTAYIM in /home/kafka/test/
- xcode6 Auto layout and size classes
dcj3sjt126com
ios
官方GUI
https://developer.apple.com/library/ios/documentation/UserExperience/Conceptual/AutolayoutPG/Introduction/Introduction.html
iOS中使用自动布局(一)
http://www.cocoachina.com/ind
- 通过PreparedStatement批量执行sql语句【sql语句相同,值不同】
梦见x光
sql事务批量执行
比如说:我有一个List需要添加到数据库中,那么我该如何通过PreparedStatement来操作呢?
public void addCustomerByCommit(Connection conn , List<Customer> customerList)
{
String sql = "inseret into customer(id
- 程序员必知必会----linux常用命令之十【系统相关】
hanqunfeng
Linux常用命令
一.linux快捷键
Ctrl+C : 终止当前命令
Ctrl+S : 暂停屏幕输出
Ctrl+Q : 恢复屏幕输出
Ctrl+U : 删除当前行光标前的所有字符
Ctrl+Z : 挂起当前正在执行的进程
Ctrl+L : 清除终端屏幕,相当于clear
二.终端命令
clear : 清除终端屏幕
reset : 重置视窗,当屏幕编码混乱时使用
time com
- NGINX
IXHONG
nginx
pcre 编译安装 nginx
conf/vhost/test.conf
upstream admin {
server 127.0.0.1:8080;
}
server {
listen 80;
&
- 设计模式--工厂模式
kerryg
设计模式
工厂方式模式分为三种:
1、普通工厂模式:建立一个工厂类,对实现了同一个接口的一些类进行实例的创建。
2、多个工厂方法的模式:就是对普通工厂方法模式的改进,在普通工厂方法模式中,如果传递的字符串出错,则不能正确创建对象,而多个工厂方法模式就是提供多个工厂方法,分别创建对象。
3、静态工厂方法模式:就是将上面的多个工厂方法模式里的方法置为静态,
- Spring InitializingBean/init-method和DisposableBean/destroy-method
mx_xiehd
javaspringbeanxml
1.initializingBean/init-method
实现org.springframework.beans.factory.InitializingBean接口允许一个bean在它的所有必须属性被BeanFactory设置后,来执行初始化的工作,InitialzingBean仅仅指定了一个方法。
通常InitializingBean接口的使用是能够被避免的,(不鼓励使用,因为没有必要
- 解决Centos下vim粘贴内容格式混乱问题
qindongliang1922
centosvim
有时候,我们在向vim打开的一个xml,或者任意文件中,拷贝粘贴的代码时,格式莫名其毛的就混乱了,然后自己一个个再重新,把格式排列好,非常耗时,而且很不爽,那么有没有办法避免呢? 答案是肯定的,设置下缩进格式就可以了,非常简单: 在用户的根目录下 直接vi ~/.vimrc文件 然后将set pastetoggle=<F9> 写入这个文件中,保存退出,重新登录,
- netty大并发请求问题
tianzhihehe
netty
多线程并发使用同一个channel
java.nio.BufferOverflowException: null
at java.nio.HeapByteBuffer.put(HeapByteBuffer.java:183) ~[na:1.7.0_60-ea]
at java.nio.ByteBuffer.put(ByteBuffer.java:832) ~[na:1.7.0_60-ea]
- Hadoop NameNode单点问题解决方案之一 AvatarNode
wyz2009107220
NameNode
我们遇到的情况
Hadoop NameNode存在单点问题。这个问题会影响分布式平台24*7运行。先说说我们的情况吧。
我们的团队负责管理一个1200节点的集群(总大小12PB),目前是运行版本为Hadoop 0.20,transaction logs写入一个共享的NFS filer(注:NetApp NFS Filer)。
经常遇到需要中断服务的问题是给hadoop打补丁。 DataNod






 3、多个编码器结构
3、多个编码器结构