Web 反爬虫实践与反爬虫破解

写在前面
前不久公司的产品信息被竞品给爬了,之前竞品内没有这些信息,是我们独有的。后来发现突然就有了,而且和我们的产品信息一致,后来我们也找到了一些证据,证明是被爬了。
因为当时也有一些反爬机制,但都是比较容易被绕过的。所以这次做了下升级,采用自定义字体的方式来反爬。
本文就简单分享下如何用自定义字体来实现反爬虫。
font-face 反爬虫 实现原理
网页内的文字,如中文、英文、数字等,这些内容的显示都是按照具体的字体来进行显示(绘制)的。如果你在css内显示设置了这段内容的字体,那么就会在系统内查找该字体文件或者使用font-face (指定得网络字体文件),再按照文字的unicode码在字体文件内查找对应的字形,最终将该字形绘制到页面上。
另外字体图标相信大家都用过,像iconfont、 font-awesome,其实原理是一样的。
下面便是一个字形,是从字体里提取的一个汉子的字形,然后转换为了svg

而我们实现的反爬虫就是基于上面的原理。
我们通过修改字体文件,对文件内字体的unicode码进行加密,然后将该字体作为自定义字体进行加载到网页。
举个例子:
“前端技术江湖”这几个字使用unicode编码显示为
前端技术江湖

我们现在能识别上面的汉子,是因为可以通过unicode码直接转换为汉子。
如果将“前端技术江湖”的unicode进行加密后呢?
通过程序我们将无法得知这几个编码对应的汉子是什么,但是在浏览器上能正常显示,即便是爬虫能抓取到该内容,但是无法根据具体的编码得知这是什么内容。
下面为一个参考,具体的编码规则可以自定义,比如将1变为2,将2变为3,将a变为b等
Ԕq;端抐眯屟㹖
然后通过font-face指定具体的字体文件
@font-face
{
font-family: myfont;
src: url('xxx.ttf'),
url('xxx.eot'); /* IE9 */
}
目前谁在用
看下目前谁在用这种反爬方案,使用者较多,只列2个大家比较熟悉的吧
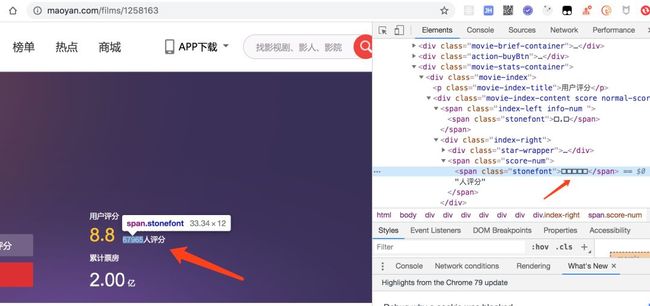
大众点评
对详情页面的敏感的数字和评论内容做了反爬

猫眼
如何实现自定义字体库
原理我们分析完了,那么如何生成这个加密后的字体文件呢。
比如我想对“前端技术江湖”这几个字加密。
首先我们需要一个字体源文件
比如“微软雅黑.ttf”
然后将
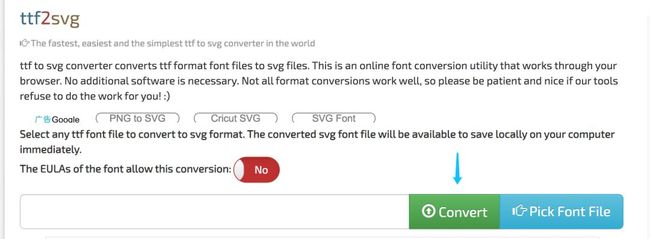
.ttf文件转换为.svg文件
使用在线工具 https://everythingfonts.com/ttf-to-svg
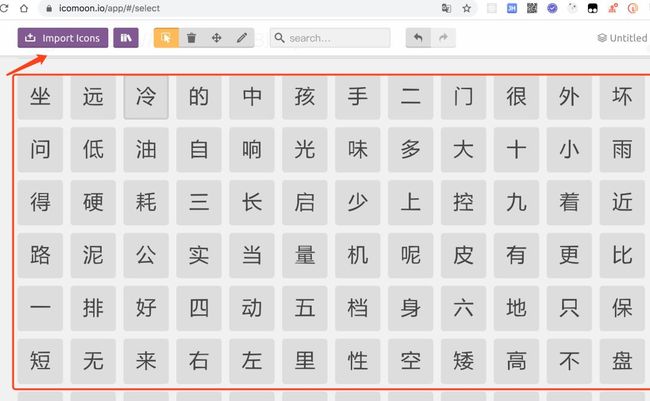
使用该svg文件,生成目标字体库
使用在线工具进行转换 https://icomoon.io/app/#/select
第一步导入svg文件,第二步选择你要加密的字体
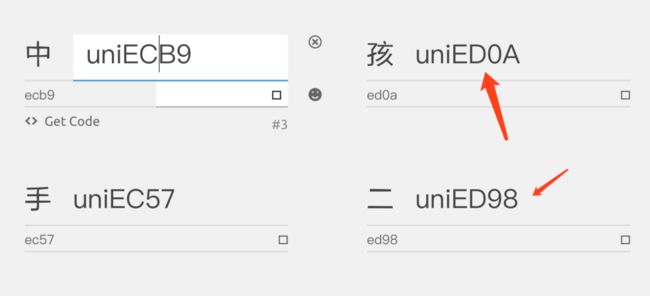
第三步 编辑并下载生成的字体

在这里对上一步选择的内容进行编码设置,应用我们的编码规则,然后下载编码后的字体文件。

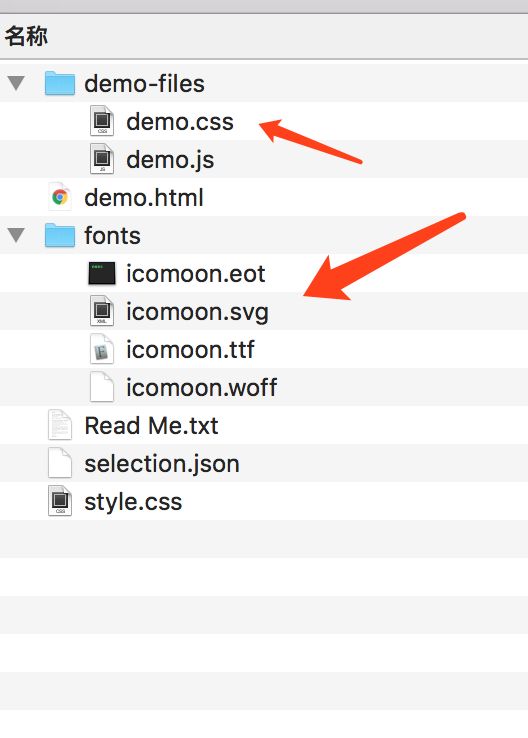
然后定义font-face和 font-family
@font-face {
font-family: 'icomoon';
src: url('fonts/icomoon.eot?ygu6lu');
src: url('fonts/icomoon.eot?ygu6lu#iefix') format('embedded-opentype'),
url('fonts/icomoon.ttf?ygu6lu') format('truetype'),
url('fonts/icomoon.woff?ygu6lu') format('woff'),
url('fonts/icomoon.svg?ygu6lu#icomoon') format('svg');
font-weight: normal;
font-style: normal;
font-display: block;
}
[class^="icon-"], [class*=" icon-"] {
/* use !important to prevent issues with browser extensions that change fonts */
font-family: 'icomoon' !important;
speak: none;
font-style: normal;
font-weight: normal;
font-variant: normal;
text-transform: none;
line-height: 1;
/* Better Font Rendering =========== */
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
自动生成字体库
上面我生成的字体库完全是手动的,这完全不符合程序员的做事风格。
所以我们需要通过程序来完成。
使用工具 fontmin
http://ecomfe.github.io/fontmin/en#source
该工具可以方便的实现字体压缩,从字体源文件内提取目标字体作为一个新的字体文件。
var Fontmin = require('fontmin');
var fontmin = new Fontmin()
.use(Fontmin.glyph({
text: '天地玄黄 宇宙洪荒',
hinting: false // keep ttf hint info (fpgm, prep, cvt). default = true
}));
并可以将不同类型的字体文件进行互转

说下整体实现思路
确定你的词库(要进行加密的内容)
确定字体源文件 如微软雅黑
使用
fontmin生成目标字体文件将目标字体文件转换为
svg格式确定加密规则
对
svg文件内的unicode进行加密算法处理使用
fontmin将svg转换为目标格式eot、woff、ttf字体
最后便是定义font-face,定义font-family class。
具体代码就不写了,比较简单。
反爬虫破解
上面介绍的反爬虫方案也不能100%防止页面内容不被爬,而是提高了爬虫爬取的难度。
说说如何破解?
爬虫抓到页面的内容是一些特殊的编码,浏览器使用字体文件来进行渲染绘制,从程序角度无法得知对应的内容是什么,除非知道加密算法。这样就能得到真实的unicode编码,能反推出中文是什么。
难道这就不能破解了吗?
肯定能的,只要你不怕麻烦(提高了爬虫的难度),因为我们的肉眼是可以分辨的。
所以这是个最笨的办法,也是最有效的方法。
人肉收集这些编码和对应的汉子的关系,有了这个关系,就可以轻松的匹配出最终的内容。
比如:
编码 111 对应 前
编码 222 对应 端
编码 333 对应 技
编码 444 对应 术
编码 555 对应 江
编码 666 对应 湖
整理成对象:
{
"111":"前",
"222":"端",
"333":"技",
"444":"术",
"555":"江",
"666":"湖"
}
其实最麻烦的部分也就是这部分,我们要想办法得到这个映射表就可以了。
另外这种方式还可以升级,准备多个字体库(不同的加密方式),每次刷新页面都会使用不同的字体库,这种方式相对于使用单独字体库来说难度又提升了一步。
总结
本文主要是介绍下自己实际中如何进行反爬虫以及反爬虫的实施方案。
目前Headless Browser这货这么牛逼,一般的反扒基本上都是纸老虎。
通过自定义字体font-face来渲染页面内容,相对于其他方案更有效,但并不彻底,最终也只能提高抓取内容的难度,不过能做到这一步已经能阻止大部分爬虫了吧。