java读取银联账单
在本文中,我将展示如何使用HtmlUnit从网站下载账单(或其他文件)。
我建议您先阅读这些文章: Java和Autologin的 Web抓取简介
由于我在Digital Ocean上托管了此博客(如果您通过此链接注册,可节省10美元的信用),因此我将展示如何编写一个自动下载每张账单的机器人。
登录
要提交登录表单而不需要检查dom,我们将使用我在上一篇文章中编写的魔术方法。
然后,我们必须转到帐单页面: https://cloud.digitalocean.com/settings/billing : https://cloud.digitalocean.com/settings/billing
String baseUrl = "https://cloud.digitalocean.com" ;
String login = "email" ;
String password = "password" ;
try {
WebClient client = Authenticator . autoLogin ( baseUrl + "/login" , login , password );
HtmlPage page = client . getPage ( "https://cloud.digitalocean.com/settings/billing" );
if ( page . asText (). contains ( "You need to sign in for access to this page" )){
throw new Exception ( String . format ( "Error during login on %s , check your credentials" , baseUrl ));
}
} catch ( Exception e ) {
e . printStackTrace ();
}
取账单
让我们创建一个称为Bill或Invoice的新类来表示票据:
比尔
public class Bill {
private String label ;
private BigDecimal amount ;
private Date date ;
private String url ;
//... getters & setters
}
现在我们需要检查dom,以了解如何提取每个账单的描述,金额,日期和URL。 打开您喜欢的工具:
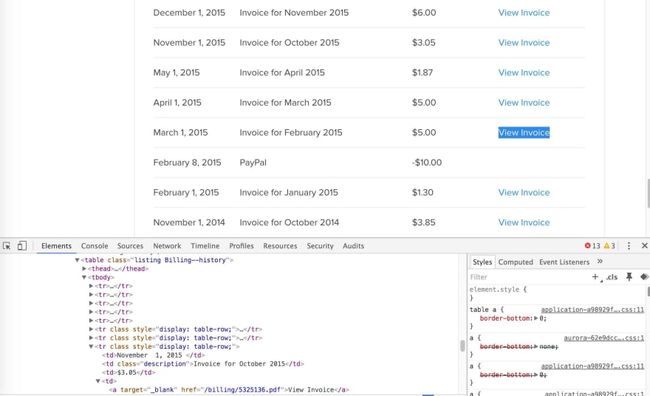
我们在这里很幸运,它是一个干净的DOM,具有漂亮且结构良好的表。 由于HtmlUnit有许多处理HTML表的方法,因此我们将使用以下方法:
HtmlTable存储表并在每行上进行迭代getCell选择单元格
然后,使用Jackson库将Bill对象导出到JSON并进行打印。
HtmlTable billsTable = ( HtmlTable ) page . getFirstByXPath ( "//table[@class='listing Billing--history']" );
for ( HtmlTableRow row : billsTable . getBodies (). get ( 0 ). getRows ()){
String label = row . getCell ( 1 ). asText ();
// We only want the invoice row, not the payment one
if (! label . contains ( "Invoice" )){
continue ;
}
Date date = new SimpleDateFormat ( "MMMM d, yyyy" , Locale . ENGLISH ). parse ( row . getCell ( 0 ). asText ());
BigDecimal amount = new BigDecimal ( row . getCell ( 2 ). asText (). replace ( "$" , "" ));
String url = (( HtmlAnchor ) row . getCell ( 3 ). getFirstChild ()). getHrefAttribute ();
Bill bill = new Bill ( label , amount , date , url );
bills . add ( bill );
ObjectMapper mapper = new ObjectMapper ();
String jsonString = mapper . writeValueAsString ( bill ) ;
System . out . println ( jsonString );
快要完成了,最后一件事是下载发票。 这很简单,我们将使用Page对象存储pdf,并在其上调用getContentAsStream 。 最好在执行此操作时检查文件是否具有正确的内容类型(本例中为application/pdf )
Page invoicePdf = client . getPage ( baseUrl + url );
if ( invoicePdf . getWebResponse (). getContentType (). equals ( "application/pdf" )){
IOUtils . copy ( invoicePdf . getWebResponse (). getContentAsStream (), new FileOutputStream ( "DigitalOcean" + label + ".pdf" ));
}
就是这样,这里是输出:
{ "label" : "Invoice for December 2015" , "amount" : 0.35 , "date" : 1451602800000 , "url" : "/billing/XXXXX.pdf" }
{ "label" : "Invoice for November 2015" , "amount" : 6.00 , "date" : 1448924400000 , "url" : "/billing/XXXX.pdf" }
{ "label" : "Invoice for October 2015" , "amount" : 3.05 , "date" : 1446332400000 , "url" : "/billing/XXXXX.pdf" }
{ "label" : "Invoice for April 2015" , "amount" : 1.87 , "date" : 1430431200000 , "url" : "/billing/XXXXX.pdf" }
{ "label" : "Invoice for March 2015" , "amount" : 5.00 , "date" : 1427839200000 , "url" : "/billing/XXXXX.pdf" }
{ "label" : "Invoice for February 2015" , "amount" : 5.00 , "date" : 1425164400000 , "url" : "/billing/XXXXX.pdf" }
{ "label" : "Invoice for January 2015" , "amount" : 1.30 , "date" : 1422745200000 , "url" : "/billing/XXXXXX.pdf" }
{ "label" : "Invoice for October 2014" , "amount" : 3.85 , "date" : 1414796400000 , "url" : "/billing/XXXXXX.pdf" }
和往常一样,您可以在此Github Repo上找到完整的代码
如果您喜欢网页抓取,并且厌倦了代理,JS渲染和验证码的处理,则可以查看我们新的网页抓取API ,其中有前1000个API调用。
翻译自: https://dev.to/scrapingbee/an-automatic-bill-downloader-in-java-4277
java读取银联账单