MSeg: A Composite Dataset for Multi-domain Semantic Segmentation——论文翻译
| Title | MSeg: A Composite Dataset for Multi-domain Semantic Segmentation |
|---|---|
| 标题 | MSeg:用于多域语义分割的复合数据集 |
| http://vladlen.info/papers/MSeg.pdf | |
| 评价 | 没有提出新的模型或者损失函数什么的;工作量大,将几个语义分割数据集合并,需要合并或者拆分类,进而联合训练;可想而知,联合训练结果不会比单独训练效果好;奈何文中说你看我在这几个测试数据集上的平均值,要比你单独训练的模型在其他数据集上也测试一下得到的平均值要好。 |
摘要
我们介绍了MSeg,这是一个复合数据集,它统一了来自不同领域的语义分割数据集。由于不一致的分类和注释,对组成数据集的简单合并会导致性能低下。我们协调了分类,并通过重新标记超过80000个图像中的超过220,000个对象掩码,使像素级注释对齐。生成的复合数据集支持训练单个语义分割模型,该模型可以跨域有效地工作,并可泛化到训练期间没有看到的数据集。我们采用零镜头跨数据集传输作为基准,系统地评估了模型的鲁棒性,并表明MSeg训练产生的模型比单独的数据集训练或没有提供贡献的数据集的单纯混合训练的鲁棒性要高得多。在MSeg上训练的模型在WildDash排行榜上排名第一,用于鲁棒性语义分割,在训练期间不暴露WildDash数据。
1. 简介
每年都有数百篇论文发表,这些论文报道了语义分类基准越来越高的准确性,如Cityscapes[7]、Mapillary[25]、COCO[19]、ADE20K[46]等。然而,一项简单的行动就可以表明任务尚未完成。当你穿越一系列的环境时,带上相机并开始记录:例如,在你的房子周围打包一些用品,进入汽车,开车穿过你的城市去郊区的森林,然后徒步旅行。现在对录制的视频进行语义分割。是否有一个模型可以成功地执行这个任务?
计算机视觉专业人员可能会求助于多个模型,每个模型针对不同的数据集进行训练。也许一个模型在NYU的数据集上训练用于室内部分的[34],一个模型训练用于驾驶部分的Mapillary,一个模型训练用于远足的ADE20K。然而,这不是一种令人满意的事态。它给开发多个模型和实现一个决定在任何给定时间应该使用哪个模型的控制器的从业者带来了负担。这也表明我们还没有得到一个令人满意的视觉系统:毕竟,动物可以用一个单一的视觉器官来穿越相同的环境,而这个视觉器官在整个过程中继续执行它的感知任务。
一种自然的解决方案是在多个数据集上训练一个模型,希望其结果在任何给定的环境中都能像最佳专用模型一样执行。正如之前所观察到的,并在我们的实验中得到证实,结果远远不能令人满意。一个关键的潜在问题是,不同的数据集有不同的分类:也就是说,它们对构成可视实体的类别或类有不同的定义。跨来自不同领域的数据集的分类冲突和不一致的注释(例如,室内和室外、城市和自然、特定领域和未知领域)大大降低了在多个数据集上训练的模型的准确性。
在本文中,我们将采取措施来解决这些问题。我们展示了MSeg,这是一个复合数据集,它统一了来自不同领域的语义分割数据集:COCO[19]、ADE20K[46]、Mapillary[25]、IDD[40]、BDD[43]、Cityscapes[7]和SUN RGB-D[36]。对7个数据集的分类进行一次简单的合并将产生300多个类,在定义和注释标准方面存在大量的内部不一致性。相反,我们协调分类、合并和拆分类,以得到一个包含194个类别的统一分类。为了使像素级的注释符合统一的分类法,我们通过Mechanical Turk平台进行了大规模的注释工作,并通过重新标记对象掩码在数据集中生成兼容的注释。
由此产生的复合数据集能够训练统一的语义分割模型,从而更接近于实现Papert的愿景。MSeg训练生成的模型能够更好地泛化训练期间没有看到的数据集。在实际的[27]模型中,我们采用zero-shot cross-dataset transfer作为模型期望性能的代理。在这种模式下,MSeg训练比在单个数据集上的训练或在没有分类协调的情况下在多个数据集上的训练要健壮得多。特别是,我们的mseg训练的模型为健壮的语义分割[44]设置了一个新的WildDash基准。我们的模型在WildDash排行榜上排名第一,在训练过程中没有看到任何WildDash数据。
2. 相关工作
2.1 跨域的语义分割。
混合分割数据集主要是在单一的领域和应用程序,如驾驶。Ros等人收集了6个驾驶数据集。bevet al.[1]将Mapillary、Cityscapes、WildDash validation set和ImageNet- 1k - bb (ImageNet[9]的子集,有边界框注释)混合用于WildDash[44]上的联合分割和离群点检测。在较小的尺度上,[16,22]混合了Mapillary、Cityscapes和German Traffic Sign Detection Benchmark。与这些工作相比,我们关注跨多个域的语义分割,并在更深的层次上解决数据集之间的不一致性,包括重新标记不兼容的注释。
Varma等人对用于驾驶的语义分割数据集的迁移性能进行了评估。它们只使用16个公共类,没有任何数据集混合。他们观察到跨数据集迁移明显不如自我训练。我们观察到,当模型在单独的数据集上训练时,或者当数据集被天真地混合时,都有相同的结果。
Liang等人通过混合Cityscapes、ADE20K、COCO Stuff和Mapillary来训练模型,但不评估跨数据集泛化。Kalluri等人的[14]混合数据集对(Cityscapes + CamVid, Cityscapes + IDD, Cityscapes + SUN RGB-D)进行半监督学习。
阻碍统一语义分割的一个根本问题是数据集分类的不兼容性。与前面提到的尝试相反,我们通过派生一致的分类法来直接解决这个问题,这种分类法连接来自多个域的数据集。
2.2 域适应和泛化
训练数据集是有偏见的,在现实世界中部署时,使用的数据与在训练[38]中看到的数据不同。
这被称为协变量移位[32]或选择偏差[13],可以在自适应或泛化设置中处理。在适应中,来自测试分布(部署环境)的样本在训练期间是可用的,尽管没有标签。一般来说,我们期望模型在对来自多个域的数据进行训练后,能够泛化到以前未见过的环境。
我们在泛化模式下进行操作,目的是训练在新环境中表现良好的鲁棒模型,在训练过程中没有来自目标领域的数据可用。许多域泛化方法都基于这样的假设,即对训练域不变的学习特征将促进到新域的泛化[21,23]。Volpi等人将区域差异作为数据分布空间中的噪声,采用分布鲁棒优化。Bilen和Vedaldi[2]建议学习一种统一的表示,并使用实例规范化消除领域特定的伸缩因子。Mancini等人的[21]修改批处理规范化统计数据,使特征和激活域不变。
上述域泛化方法假设相同的分类器可以应用于所有环境。这依赖于可视类别的兼容定义。我们的工作是互补的,并可以通过提供一个兼容的分类和一致的注释跨不同领域的语义分割数据集,促进未来的研究领域泛化。
2.3 跨越不同域的视觉学习
Visual Domain Decathlon[28]引入了超过10个图像分类数据集的基准,但是允许对所有这些数据集进行训练。更重要的是,它的目的不是训练单个分类器。相反,他们希望各领域能够通过在多任务环境中传递归纳偏差来互相帮助。Triantafillou等人[39]提出了一种用于基准化few-shot分类算法的元数据集。
对于单目深度估计问题,Ranftl等人使用多个数据集,并通过多任务学习框架将其混合。我们受此启发,旨在促进数据集混合和跨数据集泛化在语义分割方面的进展。与Ranftl等人处理几何任务(深度估计)的工作不同,我们面临跨数据集的语义标记的不一致性,并为解决这些不一致性做出了贡献。
3. MSeg Dataset
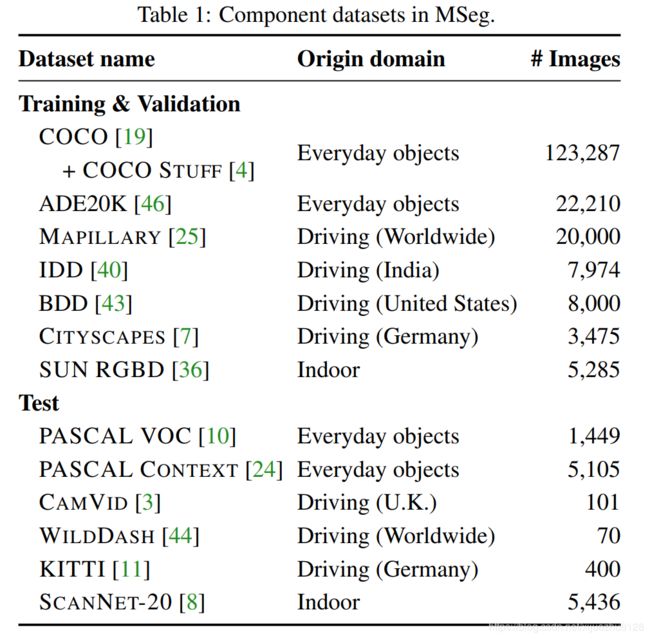
表1列出了MSeg中使用的语义分割数据集。这组数据集是一个选择后的结果,考虑了更多的候选人。未被使用的数据集,以及不包括这些数据集的原因,都在附录中列出。
我们选择训练/测试数据集分割的指导原则是,大的、现代的数据集对于训练是最有用的,而老的和小的数据集对于测试是很好的候选者。我们在这些数据集的验证子集上测试zero-shot跨数据集性能。请注意,来自测试数据集的数据(包括它们的训练分割)从来没有在MSeg中用于训练。对于验证,我们使用表1中列出的训练数据集的验证子集。
我们使用免费的,学术版的Mapillary Vistas[25]。在此,我们放弃对交通标志,交通信号灯和车道标志进行高度详细的分类,以支持更广泛地使用MSeg。
对于COCO[19],我们以COCO Panoptic的分类作为出发点,而不是COCO Stuff[4]。COCO Panoptic的分类法将一些基于材料的COCO类合并到与其他数据集更兼容的常见类别中。例:floormarble, floor-other, and floor-tile被合并到地板中。
将构成数据集简单地组合在一起可以生成大约200K个带有316个语义类的图像(在合并具有同义名称的类之后)。我们发现,在原始组合数据集上进行训练会导致较低的准确性和较差的泛化。我们认为,失败的主要原因是不同数据集中的分类和注释不一致。下面的小节将解释这些问题和我们的解决方案。
3.1 分类
为了训练一个跨域的语义模型,我们需要一个统一的分类。我们遵循一系列决策规则(如图3所示)来决定对构成数据集的分类进行拆分和合并操作。我们将通过构成数据集获得的316个类压缩为194个类的统一分类。完整的列表在图4中给出,并在附录中进一步描述和可视化。这些类中的每一个都是从构成数据集中的类派生出来的。
在设计MSeg分类时,我们有两个主要目标。首先,应该尽可能多地保留类。例如,护栏不应该仅仅因为COCO、BDD或IDD没有注释就被丢弃。合并类会降低结果模型的识别能力。其次,分类法应该是扁平的,而不是分层的,以最大限度地与标准的训练方法兼容。
MSeg类别可以与组件数据集中的类具有以下关系之一:(a)它可以与组件分类法中的类直接对应,(b)可以是合并了一个类别中的多个类的结果组件分类法,(c)可能是在组件分类法中拆分一个类的结果(一对多映射),或者(d)可能是从组件分类法中的不同类中拆分出来的类的并集。
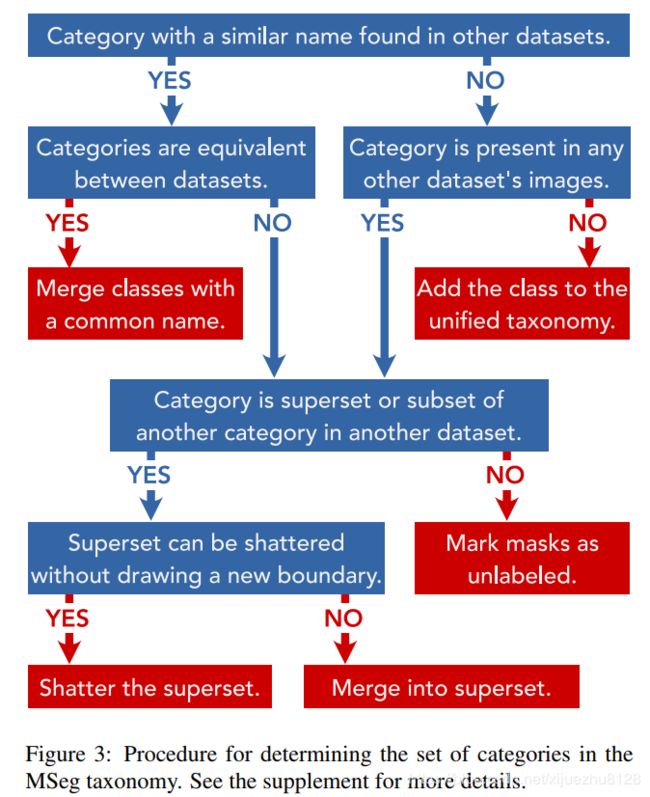
图2显示了40个类的这些关系。例如,COCO和ADE20K中的类person对应于Mapillary数据集中的四个类(person、rider-other、bicycle和motorbicycle)。因此,COCO和ADE20K中的person标签需要根据上下文分为上述四个map类别之一。(参见图2中的框COCO-E和ADE20K-D)。Mapillary比其他驾驶数据集更细粒度,并且将坑洞、停车、道路、自行车道、服务道、人行横道、车道标记、车道标记、人行横道分别进行分类。这些类被合并到一个统一的MSeg road类中。(参见图2中的方框Mapillary-C。)从组件数据集中合并和分离类有不同的缺点。合并很容易,并且可以通过编程方式执行,不需要额外的标记。缺点是,投入到原始数据集的标记工作被牺牲了,结果的分类具有更粗的粒度。另一方面,分裂是劳动密集型的。要从组件数据集中拆分类,需要重新标记该类的所有掩码。这为最终的分类提供了更细的粒度,但是需要花费时间和人力。图3中总结的过程是我们权衡这些成本的方法。、

3.2 重新标记拆分类的实例
我们利用Amazon Mechanical Turk (AMT)重新标记需要分割的类的掩码。我们只重新注释用于学习的数据集,而保留完整的评估数据集。我们没有重新计算边界,而是将问题表示为多路分类,并要求注释器根据MSeg分类法将每个掩码分类为更细粒度的类别。我们在附录中包括一个标签屏幕、工作流和标签验证过程的例子。我们一共划分了31个class,重新标记了221323个掩膜。我们在图2中可视化了一些拆分操作,并在附录中提供了更多的细节。
AMT工作人员有时会提交不准确的、随机的、甚至是对抗性的决策[35]。为了确保注释质量,我们将标记任务嵌入到每批工作中[6,12,29],至少占每批工作的10%。这些哨兵是任务的地面真相是明确的,是由我们手动注释。我们使用sentinels自动评估每个注释器的可靠性,这样我们就可以将工作引向更可靠的注释器。五个工人批注每一批,工作被重新提交,直到所有提交的批次达到100%的标记准确度。之后,以多数票决定类别;不满足这些标准的类别由专家注释器(作者之一)在内部手动标记。
4. 实验结果
4.1 实现细节
我们使用HRNet-W48[37]架构作为我们的模型。我们使用具有动量和多项式学习速率衰减的SGD,学习速率从0.01开始。**当从多个数据集中形成一个大小为m的minibatch时,我们按照训练数据集的数量n来平均分割这个minibatch,这意味着每个数据集将为每个minibatch贡献m/n个例子。**因此,在我们的训练过程中,对于统一数据集没有epoch的概念,而只是从每个数据集中看到的全部样本。例如,在一个有效的COCO epoch中,Mapillary将完成超过6个有效的epoch,因为它的数据集小于COCO的1 / 6。我们一直训练,直到每个数据集的图像都被看到了100万个裁剪图片。
跨组件数据集的图像分辨率不一致。例如,Mapillary包含许多分辨率为20004000的图像,而大多数ADE20K图像的分辨率为300400。在训练之前,我们使用2或3倍超分辨率[17]来首先向上采样低分辨率的训练数据集到一个高分辨率的训练数据集(至少1000p)。在训练时,我们将来自不同数据集的图像调整到一致的分辨率。具体来说,在我们的实验中,我们调整了所有图片的大小,使它们的短边为1080像素(同时保留长宽比),并使用裁剪大小为713*713像素。在测试时,我们将图像大小调整为三种不同分辨率之一(图像较短的一侧为360/720/1080),执行推断,然后将预测映射插值回原始分辨率进行评估。分辨率级别(360/720/1080)是为每个数据集设置的。更多的细节在附录中提供。
4.2 在留存数据集上使用MSeg分类
在推理时,我们在每个像素上得到统一分类类别的概率向量。必须将这些统一的分类概率转换成测试数据集分类体系。例如,在摩托车手、自行车手和骑车人的统一分类中,我们有三个独立的概率。我们把这三个加在一起来计算一个cityscapes骑车人的概率。
4.3 Zero-shot迁移性能
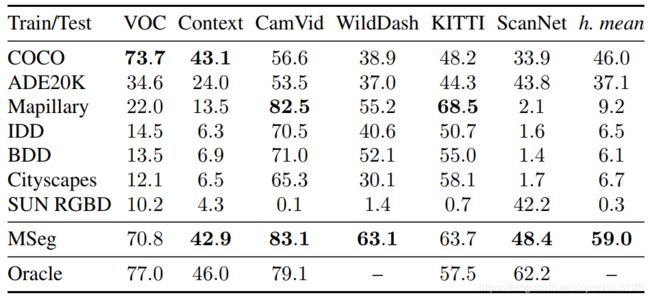
我们使用MSeg训练集来训练一个统一的语义分割模型。表2列出了模型向MSeg测试数据集的Zero-shot迁移的结果。注意,模型在训练期间没有看到这些数据集。为了进行比较,我们列出了在组成MSeg的单个训练数据集上训练的相应模型的性能。作为参考,我们还列出了在测试数据集的训练分割上进行训练的oracle模型的性能。注意,WildDash没有一个训练集,因此没有为它提供oracle性能。
表2中的结果表明,有时可以通过对具有兼容先验的特定训练数据集进行训练来获得在特定测试数据集上的良好性能。例如,COCO的训练在VOC上有很好的表现,Mapillary下的训练在KITTI上有很好的表现。但是没有一个单独的训练数据集在测试数据集中产生良好的性能。相反,在MSeg上训练的模型在所有数据集上执行一致。这在总体性能上是很明显的,通过跨数据集的调和平均值进行了总结。通过mseg训练模型得到的调和平均mIoU比最佳单独训练基线(COCO)的精度高28%。
表2:MSeg测试数据集上的语义分割精度(mIoU)。(Zero-shot cross-dataset泛化)。顶部:在单个训练数据集上训练的模型的性能。中间:同样的模型在MSeg(我们的结果)上训练。底部:供参考,oracle模型在测试数据集上的性能训练。最右边的一列是一个汇总度量:跨数据集的调和平均值。
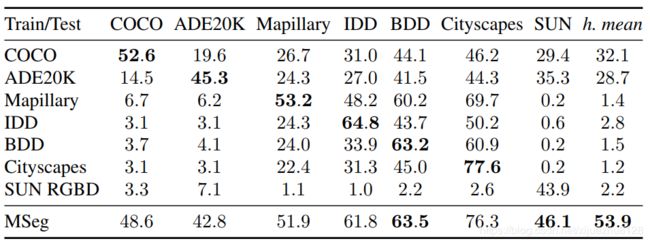
4.4 在训练数据集上的性能
表3列出了MSeg训练数据集上训练模型的准确性。我们在验证集上进行测试,并在数据集和MSeg分类中共同出现的类子集上计算IoU。除了Cityscapes和BDD100K之外,所有训练数据集的验证集的结果都不能直接与文献进行比较,因为MSeg分类涉及合并多个类。正如预期的那样,经过单独训练的模型在相同的数据集上测试时通常表现出良好的准确性:经过COCO训练的模型在COCO上表现良好,等等。MSeg模型的总体性能是通过数据集间的调和平均值来总结的。它比最好的个人训练基线(COCO)高出68%。
4.5 WildDash基准
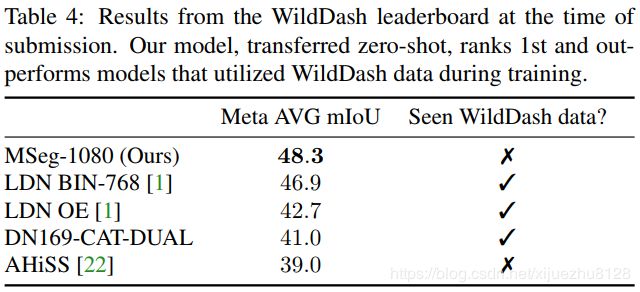
WildDash基准[44]专门评估语义分割模型的鲁棒性。图像主要包含不寻常和危险的道路场景(例如,恶劣的天气、噪音、失真)。基准测试的目的是测试在其他数据集上训练的模型的健壮性,而不提供自己的训练集。为验证提供了一小组70个带注释的图像。评估的主要模式是一个排行榜,带有一个测试服务器和一个带有隐藏注释的测试集。主要的评估指标是元平均mIoU,它结合了与不同危害和每帧IoU相关的性能指标。
我们将在MSeg上训练的模型的结果提交到WildDash测试服务器,并使用多尺度推理。请注意,WildDash不在MSeg训练集中,提交的模型在训练期间从未见过WildDash图像。结果见表4。我们的模型在排行榜上排名第一。值得注意的是,我们的模型比在多个数据集上训练并在训练中使用WildDash验证集的方法表现更好。与(像我们的)在训练中没有利用WildDash数据的最佳先验模型相比,我们的模型的准确率提高了9.3个百分点:相对提高了24%。
4.6 定性的结果
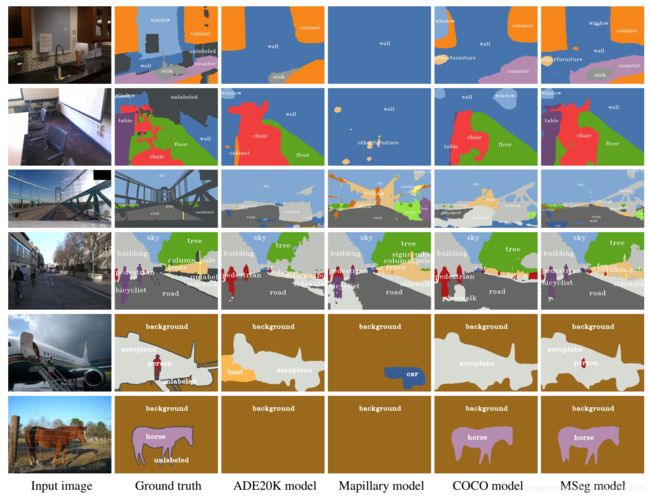
图5提供了来自不同测试数据集的图像的定性结果。与基线不同,MSeg模型在所有领域都是成功的。在ScanNet上,我们的模型甚至比提供的地面事实提供了更准确的椅子预测。相比之下,ADE20K模型对表格是盲目的,而地图训练的模型在ScanNet的室内环境中完全失败。在CamVid上,map-和coco -训练的模型错误地预测了路面上的人行道;ADE20K和coco培训的模型没有骑手的概念,并将骑自行车的人误认为行人。在Pascal VOC上,我们的模型是唯一能正确识别一个人站在飞机的移动楼梯上的模型;一个经过20年训练的模型错误地预测了一艘船,而一个地图模型看到了一辆车。在另一个Pascal图像上,ADE20K没有horse类,相应的模型无法识别它。
4.7 消融研究
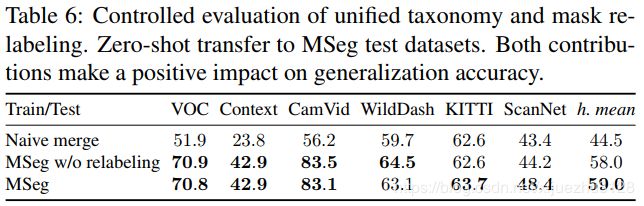
表6报告了对我们的两个贡献的评估:统一分类(第3.1节)和兼容的重新标记(第3.2节)。简单的合并基线是在组合数据集上训练的模型,该数据集使用一种简单的合并分类,其中类是所有训练类的联合,并且每个测试类只有在它们具有相同的名称时才映射到一个通用类。MSeg (w/o重新标记)基线使用统一的MSeg分类,但不为拆分类使用手工重新标记的数据(第3.2节)。在给出的复合数据集(MSeg)上训练的模型比基线具有更好的性能。
5. 结论
我们提出了一个用于多域语义分割的复合数据集。为了构造复合数据集,我们协调了七个语义分割数据集的分类。在需要划分类别的情况下,我们通过Mechanical Turk平台进行了大规模的mask重新打标签。我们展示了生成的复合数据集可以训练一个统一的语义分割模型,该模型可以跨域提供一致的高性能。经过训练的模型可以推广到以前未见过的数据集,并且目前在WildDash的语义细分排行榜上排名第一,在训练过程中没有暴露WildDash数据。我们认为,目前的工作是迈向更广泛部署稳健的计算机视觉系统的一步,并希望它将支持未来在零镜头泛化方面的工作。代码、数据和经过训练的模型可以在https://github.com/mseg -dataset上获得。