基于caffe和casiaHWDB手写体汉字库的网络和参数设置(上)
网络和参数配置看论文:Convolution Neural Networks for Chinese Handwriting Recognition
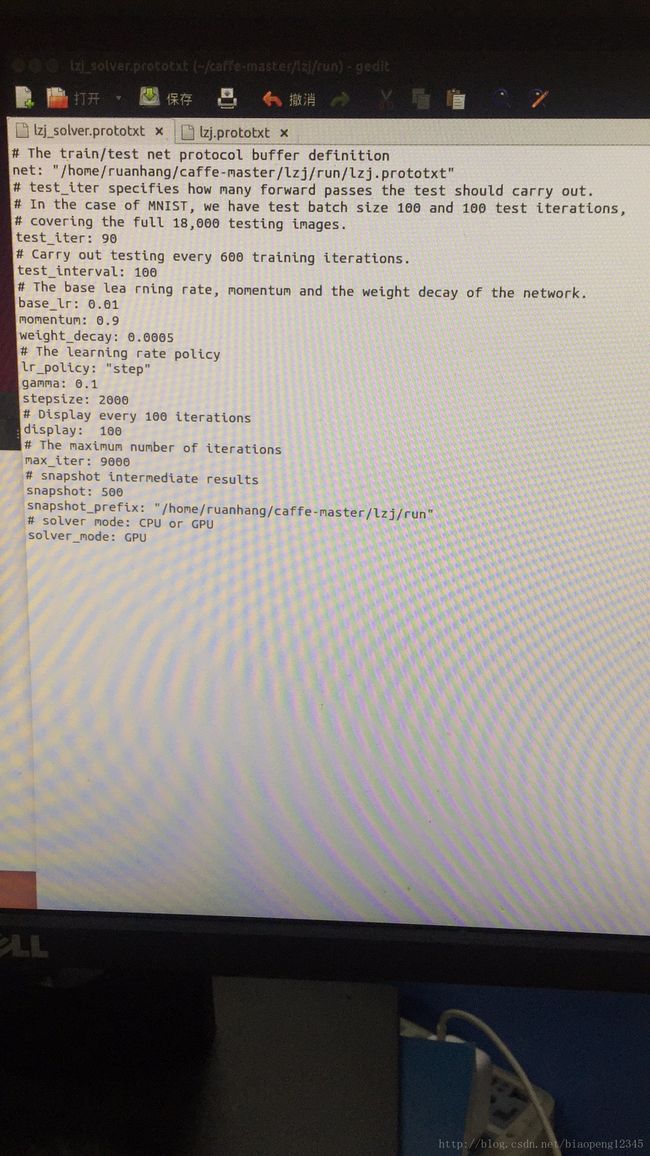
lzj_solver.prototxt里面
(1)test_iter:测试样本总数/;
这个要与test layer中的batch_size结合起来理解。mnist数据中测试样本总数为10000,一次性执行全部数据效率很低,因此我们将测试数据分成几个批次来执行,每个批次的数量就是batch_size。假设我们设置batch_size为100,则需要迭代100次才能将10000个数据全部执行完。因此test_iter设置为100。执行完一次全部数据,称之为一个epoch
注意:之前用convert_imageset生成LMDB格式时,参数resize_height和resize_width一定要设置,不然会出现data_transformer.cpp里的错误
错误:Check failed: error == cudaSuccess (2 vs. 0) out of memory
解决办法:GPU查内存命令:nvidia-smi
杀死进程命令:kill -9 PID PID为上面查出的进程号
(2)test_interval
test_interval: 500
测试间隔。也就是每训练500次,才进行一次测试。
mnist是一个手写数字数据库,由Google实验室的Corinna Cortes和纽约大学柯朗研究院的Yann LeCun等人建立,它有60,000个训练样本集和10,000个测试样本集,对应test_interval是500,我们是在此基础上作改动
在300个训练集和测试集中,样本分别有72,000和18,000,对应test_interval是600
在3755个训练集和测试集中,样本分别有901,200和225,300,对应test_interval是6260
(4)weight_decay:权重衰减,主要是为了防止过拟合
(5)
max_iter: 20000
最大迭代次数。这个数设置太小,会导致没有收敛,精确度很低。设置太大,会导致震荡,浪费时间。
(6)
snapshot用于设置训练多少次后进行保存,默认为0,不保存。snapshot_prefix设置保存路径。
(7)display
没有影响,多少次迭代显示
(8)snapshot保存.caffemodel和.solverstate
注意:
stride<=kernel
卷积层设置:3*3 filter pad=1 stride=1
池化层设置:2*2 pixel window
选择论文里的I方法,而不是Accuracy最高的H
——————————————————————————————————————————————-———
模型1:
caffe在solverstate的基础上继续训练模型:https://www.cnblogs.com/k7k8k91/p/7798278.html
迭代1000:loss=3.9 lr=0.01
迭代1200:loss=3.55
lr=0.001 loss不太好
打印log,画accuracy和loss图
------------------------------------------------------------------------------------------------------------
模型2:在模型1基础上,将gamma设为0.2,然后在solverstate1000基础上,进行训练,很简单:命令行后加参数--snapshot=【solverstate位置】即可
run_iter_1500 Loss=3.7
-------------------------------------------------------------------------------------------------------------------
模型3:lr<0.001时基本对参数改变没影响
stepsize=3000改变没影响
————————————————————————————————————————————————————
模型4:base_lr=0.1
loss增大太多
————————————————————————————————————————————————————
模型5:base_lr=0.03
影响不大
————————————————————————————————————————————————————
模型6:base_lr=0.008
影响不大
_____________________________________________________________________________________________________________________________
模型7:在标签正确的前提下,如果倒数第一个全连接层num_output > 实际的类别数,Caffe的训练是否会报错?
不会报错且无影响
将最后一层num_outout变成301没影响
将最后一层num_outout变成1000没影响
————————————————————————————————————————————————————————————————
模型8:在FC1024,FC1024,FC300之间加入dropout层 dropout rate=0.5,论文里的decay by0.1意味着gamma=0.9
---------------------------------------------------------------------------------------------------------------------------------------------
模型8用minist 10类手写体数字识别率达到99%
说明:网络无问题
--------------------------------------------------------------------------------------------------------------------------
模型8用casiaHWDB前10类数据 转数据时加gray=true 存储量小
loss=2.3
-------------------------------------------------------------------------------------------------------------------------------
模型8用casiaHWDB前10类数据 转数据时不加gray=true 存储量大 ,为加gray时两倍
loss=2.3
--------------------------------------------------------------------------------------------------------------------------------
模型8用casiaHWDB 测试集3755类别 训练集3755类别
效果不好
-------------------------------------------------------------------------------------------------------------------------------
用AlexNet跑自己的5类数据:
http://blog.csdn.net/gybheroin/article/details/54095399改了crop_size=64、路径、 num_output=5
loss为0.00
用Mnist改进的11层网络达不到这样效果
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
用AlexNet跑自己的300类数据:
数据层,卷积层5层,全连接3层,accuracy和loss
改num_output=300
loss=6
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
用AlexNet跑自己的100类数据:
数据层,卷积层5层,全连接3层,accuracy和loss
改num_output=100
loss=4.6
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
用AlexNet跑自己的50类数据:
数据层,卷积层5层,全连接3层,accuracy和loss
改num_output=50
loss=3.96
--------------------------------------------------------
用AlexNet跑自己的20类数据:
数据层,卷积层5层,全连接3层,accuracy和loss
改num_output=20
loss=3.01
迭代5000次
—--------------------------------------------------------------------------------------------------------
用AlexNet跑自己的10类数据:
数据层,卷积层5层,全连接3层,accuracy和loss
改num_output=10
从loss=2.30迭代3500次到loss=0 accuracy=0.9556
———————————————————————————————————————————————————从20类开始改网络:
改了test_interval=100
test_iter=30
train:batch_size=200
test:batch_size=40
没影响loss=3.03
原网络架构:
训练数据层
测试数据层
卷积、激活、池化1
卷积、激活、池化2
卷积、激活3
卷积、激活4
卷积、激活、池化5
全连接、激活、丢弃6
全连接、激活、丢弃7
全连接8
Accuracy
Loss
先加卷积层
————————————————————————————————————————————————————
Windows caffe VGG人脸识别:https://www.cnblogs.com/chenzhefan/p/7624811.html
200个类 train 47633项
200个类 val 11731项
深度学习之图像分类模型VGG解读:http://blog.csdn.net/sunbaigui/article/details/46713483
【caffe跑试验遇到错误:Check failed: error == cudaSuccess (2 vs. 0) out of memory】:
http://blog.csdn.net/u013634684/article/details/50290909
base_lr是适用于所有层的学习率,而针对单个层,可以通过增加两个blobs_lr,用来调整该层的学习率.