Spark2.2源码分析:Spark-Submit提交任务
Spark2.2源码阅读顺序
1. Spark2.2源码分析:Spark-Submit提交任务
2. Spark2.2源码分析:Driver的注册与启动
客户端通过spark-submit命令提交作业后,会在spark-submit进程里做一系列操作(对应图中0部分)
spark集群启动后会干的事情大概画图如下:
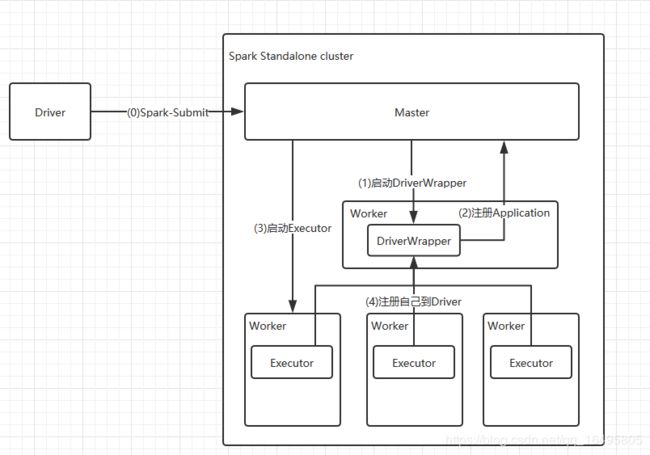
概述整体步骤
1.先执行spark-submit脚本,准备参数,选择集群管理器
2.启动driver,注册application,启动executor,划分任务,分发任务
3.返回(或则落地)计算结果,spark任务计算完成
1.用户提交Spark命令如下
./bin/spark-submit \
--class cn.face.cdp.run.WordCount \
--master spark://192.168.1.11:7077 \
--deploy-mode cluster \
--executor-memory 4G \
--total-executor-cores 20 \
--supervise \
./face.jar \
city
这个sh内部会执行一个javal类的main方法
export PYTHONHASHSEED=0
exec "${SPARK_HOME}"/bin/spark-class org.apache.spark.deploy.SparkSubmit "$@"
显而易见,我们找到这个类的main方法就能一窥究竟
org.apache.spark.deploy.SparkSubmit
override def main(args: Array[String]): Unit = {
//检查参数封装后返回
val appArgs = new SparkSubmitArguments(args)
...
//匹配传过来的类型,这里走submit case
appArgs.action match {
case SparkSubmitAction.SUBMIT => submit(appArgs)
case SparkSubmitAction.KILL => kill(appArgs)
case SparkSubmitAction.REQUEST_STATUS => requestStatus(appArgs)
}
}
private def submit(args: SparkSubmitArguments): Unit = {
//这里的prepareSubmitEnvironment非常复杂,主要负责设置环境变量,系统参数,选择集群管理器等等
//返回的childMainClass默认选择了"org.apache.spark.deploy.Client",由这个类来当作入口提交Driver
val (childArgs, childClasspath, sysProps, childMainClass) = prepareSubmitEnvironment(args)
def doRunMain(): Unit = {
if (args.proxyUser != null) {
val proxyUser = UserGroupInformation.createProxyUser(args.proxyUser,
UserGroupInformation.getCurrentUser())
try {
proxyUser.doAs(new PrivilegedExceptionAction[Unit]() {
override def run(): Unit = {
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
})
} catch {
...
}
} else {
. //runMain方法就直接用反射调用了Client类的main方法
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)
}
}
org.apache.spark.deploy.Client
def main(args: Array[String]) {
...
val conf = new SparkConf()
val driverArgs = new ClientArguments(args)
if (!conf.contains("spark.rpc.askTimeout")) {
conf.set("spark.rpc.askTimeout", "10s")
}
val rpcEnv =
RpcEnv.create("driverClient", Utils.localHostName(), 0, conf, new SecurityManager(conf))
//实例化自身RPC通信终端,实例化master引用端
val masterEndpoints = driverArgs.masters.map(RpcAddress.fromSparkURL).
map(rpcEnv.setupEndpointRef(_, Master.ENDPOINT_NAME))
rpcEnv.setupEndpoint("client", new ClientEndpoint(rpcEnv, driverArgs, masterEndpoints, conf))
rpcEnv.awaitTermination()
}
ClientEndpoint这个类继承了ThreadSafeRpcEndpoint,所以会重写onStart,并自动调用
override def onStart(): Unit = {
driverArgs.cmd match {
case "launch" =>
//如果用的Standalone cluster模式,就会启动这个进程
val mainClass = "org.apache.spark.deploy.worker.DriverWrapper"
...
val command = new Command(mainClass,
Seq("{{WORKER_URL}}", "{{USER_JAR}}", driverArgs.mainClass) ++ driverArgs.driverOptions,
sys.env, classPathEntries, libraryPathEntries, javaOpts)
//创建driver信息对象,并且发送消息到master进行注册
val driverDescription = new DriverDescription(
driverArgs.jarUrl,
driverArgs.memory,
driverArgs.cores,
driverArgs.supervise,
command)
ayncSendToMasterAndForwardReply[SubmitDriverResponse](
//这里发送的caseClass是RequestSubmitDriver,所以去master找到这个case接受逻辑就行
RequestSubmitDriver(driverDescription))
case "kill" =>
val driverId = driverArgs.driverId
ayncSendToMasterAndForwardReply[KillDriverResponse](RequestKillDriver(driverId))
}
}
org.apache.spark.deploy.master.Master
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
//此case处理提交Driver请求
case RequestSubmitDriver(description) =>
//如果此master不处于存活状态,返回client false状态
if (state != RecoveryState.ALIVE) {
val msg = s"${Utils.BACKUP_STANDALONE_MASTER_PREFIX}: $state. " +
"Can only accept driver submissions in ALIVE state."
context.reply(SubmitDriverResponse(self, false, None, msg))
} else {
logInfo("Driver submitted " + description.command.mainClass)
//创建Driver信息,由此master进程维护
val driver = createDriver(description)
//持久化driver信息,以用于之后的主备切换或者重启能重读driver信息
persistenceEngine.addDriver(driver)
//加入“等待调度的driver列表”
waitingDrivers += driver
//加入master内存中所管理的driver列表
drivers.add(driver)
//由于有新的driver需要运行,所以开始调度资源
schedule()
//返回消息给Client,Client结束进程
context.reply(SubmitDriverResponse(self, true, Some(driver.id),
s"Driver successfully submitted as ${driver.id}"))
}
case ...
}
org.apache.spark.deploy.Client
override def receive: PartialFunction[Any, Unit] = {
case SubmitDriverResponse(master, success, driverId, message) =>
logInfo(message)
if (success) {
activeMasterEndpoint = master
//这个方法主要是,等5秒后再次去master查询当前driver的状态,然后打印日志,最后结束当前进程
pollAndReportStatus(driverId.get)
//这个分支是如果请求的master不为live,则直接退出进程
} else if (!Utils.responseFromBackup(message)) {
System.exit(-1)
}
case ...
}
至此,spark-submit所执行的流程结束(Client进程结束,客户端与集群断开连接),接下来就是driver注册与启动
2. Spark2.2源码分析:Driver的注册与启动