Java集合框架常用类源码分析与总结
Java集合工具包位于Java.util包下,包含了很多常用的数据结构,如数组、链表、栈、队列、集合、哈希表等。学习Java集合框架下大致可以分为如下五个部分:List列表、Set集合、Map映射、迭代器(Iterator、Enumeration)、工具类(Arrays、Collections)。
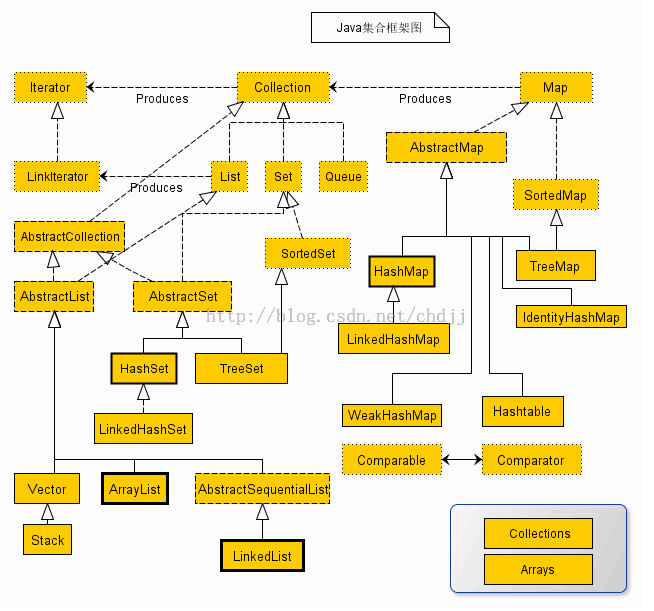
Java集合类的整体框架如下:
ArrayList
ArrayList是基于数组实现的,是一个动态数组,其容量能自动增长,类似于C语言中的动态申请内存,动态增长内存。
ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用Collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
ArrayList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问,实现了Cloneable接口,能被克隆。
1、注意其三个不同的构造方法。无参构造方法构造的ArrayList的容量默认为10,带有Collection参数的构造方法,将Collection转化为数组赋给ArrayList的实现数组elementData。
2、注意扩充容量的方法ensureCapacity。ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就设置新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量),而后用Arrays.copyof()方法将元素拷贝到新的数组(详见下面的第3点)。从中可以看出,当容量不够时,每次增加元素,都要将原来的元素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用LinkedList。
3、ArrayList的实现中大量地调用了Arrays.copyof()和System.arraycopy()方法。我们有必要对这两个方法的实现做下深入的了解。
首先来看Arrays.copyof()方法。它有很多个重载的方法,但实现思路都是一样的,我们来看泛型版本的源码:
public static T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
} 很明显调用了另一个copyof方法,该方法有三个参数,最后一个参数指明要转换的数据的类型,其源码如下:
public static T[] copyOf(U[] original, int newLength, Classextends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
} 这里可以很明显地看出,该方法实际上是在其内部又创建了一个长度为newlength的数组,调用System.arraycopy()方法,将原来数组中的元素复制到了新的数组中。
下面来看System.arraycopy()方法。该方法被标记了native,调用了系统的C/C++代码,在JDK中是看不到的,但在openJDK中可以看到其源码。该函数实际上最终调用了C语言的memmove()函数,因此它可以保证同一个数组内元素的正确复制和移动,比一般的复制方法的实现效率要高很多,很适合用来批量处理数组。Java强烈推荐在复制大量数组元素时用该方法,以取得更高的效率。
4、注意ArrayList的两个转化为静态数组的toArray方法。
第一个,Object[] toArray()方法。该方法有可能会抛出java.lang.ClassCastException异常,如果直接用向下转型的方法,将整个ArrayList集合转变为指定类型的Array数组,便会抛出该异常,而如果转化为Array数组时不向下转型,而是将每个元素向下转型,则不会抛出该异常,显然对数组中的元素一个个进行向下转型,效率不高,且不太方便。
第二个, T[] toArray(T[] a)方法。该方法可以直接将ArrayList转换得到的Array进行整体向下转型(转型其实是在该方法的源码中实现的),且从该方法的源码中可以看出,参数a的大小不足时,内部会调用Arrays.copyOf方法,该方法内部创建一个新的数组返回。
5、ArrayList基于数组实现,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
6、在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,ArrayList中允许元素为null。
LinkedList
LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当做链表来操作外,它还可以当做栈、队列和双端队列来使用。
LinkedList同样是非线程安全的,只在单线程下适合使用。
LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了Cloneable接口,能被克隆。
1、从源码中很明显可以看出,LinkedList的实现是基于双向循环链表的,且头结点中不存放数据。
2、注意两个不同的构造方法。无参构造方法直接建立一个仅包含head节点的空链表,包含Collection的构造方法,先调用无参构造方法建立一个空链表,而后将Collection中的数据加入到链表的尾部后面。
3、在查找和删除某元素时,源码中都划分为该元素为null和不为null两种情况来处理,LinkedList中允许元素为null。
4、LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
5、注意源码中的Entry entry(int index)方法。该方法返回双向链表中指定位置处的节点,而链表中是没有下标索引的,要指定位置出的元素,就要遍历该链表,从源码的实现中,我们看到这里有一个加速动作。源码中先将index与长度size的一半比较,如果index小于size/2,就只从位置0往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历,从而提高一定的效率(实际上效率还是很低)。
6、LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)。
7、要注意源码中还实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用。
Vector
Vector也是基于数组实现的,是一个动态数组,其容量能自动增长。
Vector是JDK1.0引入了,它的很多实现方法都加入了同步语句,因此是线程安全的(其实也只是相对安全,有些时候还是要加入同步语句来保证线程的安全),可以用于多线程环境。
Vector没有丝线Serializable接口,因此它不支持序列化,实现了Cloneable接口,能被克隆,实现了RandomAccess接口,支持快速随机访问。
1、Vector有四个不同的构造方法。无参构造方法的容量为默认值10,仅包含容量的构造方法则将容量增长量(从源码中可以看出容量增长量的作用,第二点也会对容量增长量详细说)明置为0。
2、注意扩充容量的方法ensureCapacityHelper。与ArrayList相同,Vector在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当容量不足以容纳当前的元素个数时,就先看构造方法中传入的容量增长量参数CapacityIncrement是否为0,如果不为0,就设置新的容量为就容量加上容量增长量,如果为0,就设置新的容量为旧的容量的2倍,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容量),而后同样用Arrays.copyof()方法将元素拷贝到新的数组。
3、很多方法都加入了synchronized同步语句,来保证线程安全。
4、同样在查找给定元素索引值等的方法中,源码都将该元素的值分为null和不为null两种情况处理,Vector中也允许元素为null。
5、其他很多地方都与ArrayList实现大同小异,Vector现在已经基本不再使用。
待更。。。。