Logstash:运用 Elasticsearch 过滤器来丰富数据
针对 Logstash 的数据丰富,除了我们之前介绍的 GeoIP 过滤器外,我之前也介绍了 “运用jdbc_streaming来丰富我们的数据”。在今天的文章中,我们介绍如何使用 Elastcsearch 过滤器来丰富我们的数据。
在Elasticsearch中搜索上一个日志事件,并将其中的某些字段复制到当前事件中。 以下是有关如何使用此过滤器的两个完整示例。
第一个示例使用传统查询参数,其中用户仅限于Elasticsearch query_string。 每当logstash收到 “end” 事件时,它就会使用此Elasticsearch 过滤器根据某些操作标识符找到匹配的 “start” 事件。 然后,它将@timestamp字段从 “start” 事件复制到 “end” 事件的新字段。 最后,结合使用 “date” 过滤器和 “ruby” 过滤器,我们可以计算两个事件之间的持续时间(以小时为单位)。
动手实践
打开 Kibana,然后,我们使用如下的命令来创建一个叫做 enrich_index 的索引:
PUT enrich_index
{
"mappings": {
"properties": {
"@timestamp": {
"type": "date"
},
"operation": {
"type": "keyword"
},
"type": {
"type": "keyword"
},
"status": {
"type": "text"
}
}
}
}在上面,我们创建 enrich_index 的 mapping。使用如下的命令来创建一个文档:
PUT enrich_index/_doc/1
{
"@timestamp": "2020-06-16T09:23:40.423707Z",
"type": "start",
"operation": "1",
"status": "OK"
}
PUT enrich_index/_doc/2
{
"@timestamp": "2020-06-16T10:23:40.423707Z",
"type": "start",
"operation": "1",
"status": "Bad"
}在这个文档中,我们看到 type 为 "start",同时它的 operation 为 "1"。上面的 @timestamp 及 status 的数据是我们想在 Logstash 中想丰富的数据。在这里,我有意识地输入了两个文档,而且他们的 type 及 operation 都是一样的。
我们创建如下的 Logstash 的配置文件:
logstash_enrich.conf
input {
generator {
message => "type=end&opid=1"
count => 1
}
}
filter {
kv {
source => "message"
field_split => "&?"
}
# remove message field
mutate {
remove_field => ["message"]
}
if [type] == "end" {
elasticsearch {
hosts => ["localhost:9200"]
index => "enrich_index"
query_template => "template.json"
fields => {
"@timestamp" => "started"
"status" => "status"
}
}
}
date {
match => ["[started]", "ISO8601"]
target => "[started]"
}
ruby {
code => "event.set('duration_hrs', (event.get('@timestamp') - event.get('started')) / 3600)"
}
}
output {
stdout {
codec => rubydebug
}
}在上面的 input 部分,我们使用一个 generator 来生产一个 message。紧接着在 filter 部分,使用 kv 过滤器,把 key 及 value 对提取出来。然后,我们通过一个条件判断,如果 type 为 end,那么我们通过 elasticsearch 过滤器来丰富数据。为了能够使它正常工作,我们必须定义如下的文件:
template.json
{
"size": 1,
"sort" : [ { "@timestamp" : "desc" } ],
"query": {
"query_string": {
"query": "type:start AND operation:%{[opid]}"
}
},
"_source": ["@timestamp", "status"]
}在上面,我们通过 query_string 来进行查询。在上面,我们只希望有一个返回 (size = 1),同时是按照 @timestamp 降序排列的。也就是说如果有多个文档满足要求,那么只有 @timestamp 时间最近的才返回。
我们按照如下的命令来启动 Logstash:
sudo ./bin/logstash -f logstash_enrich.conf 运行的结果如下:
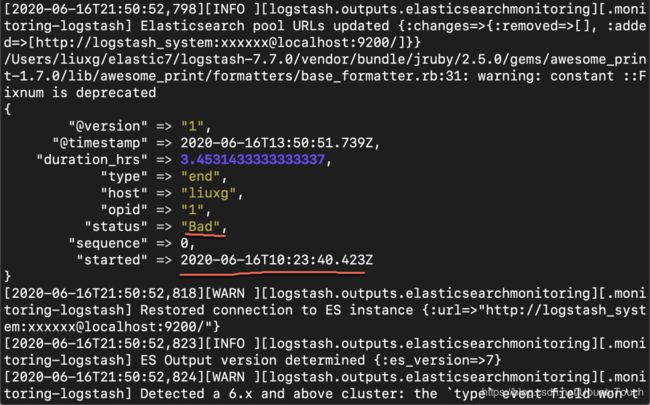
从上面的结果,我们可以看出来:status 为 bad 的文档的 type 及 status 被复制过来了。这个原因是因为这个文档的 @timestamp 时间较近,而且我们在 template.json 中只定义一个文档。
总结
在 Logstash 中,如果我们想要使用数据库来进行丰富数据的话,除了使用 jdbc_steaming 之外,我们也可以使用 Elasticsearch 过滤器来对数据进行丰富。
参考:
【1】https://www.elastic.co/guide/en/logstash/current/plugins-filters-elasticsearch.html#plugins-filters-elasticsearch-index