Python爬取视频之爱情电影及解密TS文件结合多线程
俗话说,兴趣所在,方能大展拳脚。so结合兴趣的学习才能事半功倍,更加努力专心,apparently本次任务是在视频网站爬取一些好看的小电影,地址不放(狗头保命)只记录过程。
环境 &依赖
- Win10 64bit
- IDE:Pycharm
- Python 3.8
- Python-site-package:requests + BeautifulSoup + lxml + m3u8 + AES
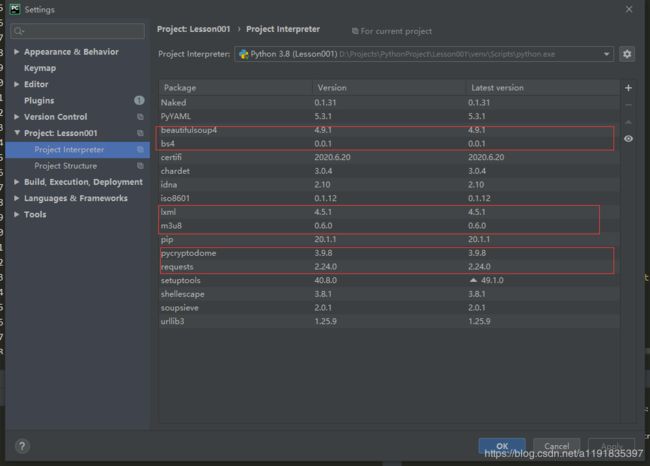
在PyCharm中创建一个项目会创建一个临时目录存放环境和所需要的package包,所以要在PyCharm 中项目解释器(Project Interpreter)中添加所有需要的包,这张截图是本项目的包列表,红框中是所必须的包,其他有的包我也不知道做什么用的。
下面开始我们的正餐,爬取数据第一步我们需要解析目标网站,找到我们需要爬取视频的地址,F12打开开发者工具
![]()

很不幸,这个网站视频是经过包装采用m3u8视频分段方式加载
科普一下:m3u8 文件实质是一个播放列表(playlist),其可能是一个媒体播放列表(Media Playlist),或者是一个主列表(Master Playlist)。但无论是哪种播放列表,其内部文字使用的都是 utf-8 编码。
当 m3u8 文件作为媒体播放列表(Meida Playlist)时,其内部信息记录的是一系列媒体片段资源,顺序播放该片段资源,即可完整展示多媒体资源。
OK,本着“没有解决不了的困难“的原则我们继续,依旧在开发者模式,从Elements模式切换到NetWork模式,去掉不需要的数据,我们发现了两个m3u8文件一个key文件和一个ts文件
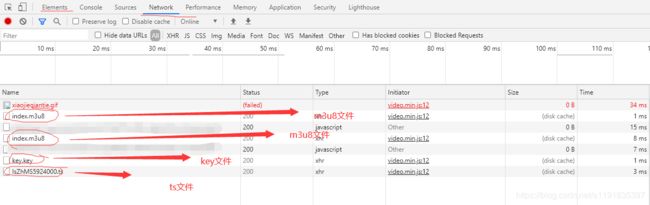
分别点击之后我们可以 看到对应的地址

OK,现在地址已经拿到了,我们可以开始我们的数据下载之路了。
首先进行初始化,包括路径设置,请求头的伪装等,之后我们通过循环去下载所有ts文件,至于如何定义循环的次数我们可以通过将m3u8文件下载之后分析得到所有ts的列表,之后拼接地址然后循环就可以得到所有ts文件了。
第一层
#EXTM3U
#EXT-X-STREAM-INF:PROGRAM-ID=1,BANDWIDTH=500000,RESOLUTION=720x406
500kb/hls/index.m3u8观察数据,不是真正路径,第二层路径在第三行可以看到,结合我们对网站源码分析再次拼接字符串请求:
第二层
#EXT-X-VERSION:3
#EXT-X-TARGETDURATION:2
#EXT-X-MEDIA-SEQUENCE:0
#EXT-X-KEY:METHOD=AES-128,URI="key.key"
#EXTINF:2.000000,
IsZhMS5924000.ts
#EXTINF:2.000000,
IsZhMS5924001.ts
#EXT-X-ENDLIST但是问题远远没有这么简单,下载的ts文件无法播放,通过AES方法加密了,所以我们需要去解密,其中m3u8加密方式我们可以在第二层地址下载到的文件中找到:#EXT-X-KEY:METHOD=AES-128,URI="key.key"。采用ASE-128方式。
我们应该庆幸Python强大的模块功能,其中解密我们可以通过下载AES模块实现。
完成之后我们需要将所有ts合并为一个MP4文件,最简单的在CMD命令下我们进入到视频所在路径然后执行:
copy /b *.ts fileName.mp4需要注意所有TS文件需要按顺序排好。但是在本项目中我们使用os模块直接进行合并和删除临时ts文件操作
最后简单的结合一下多线程加快爬取速度
完整代码:
import re
import requests
import m3u8
import time
import os
from bs4 import BeautifulSoup
import json
from Crypto.Cipher import AES
class VideoCrawler():
def __init__(self,url):
super(VideoCrawler, self).__init__()
self.url=url
self.down_path=r"F:\Media\Film\Temp"
self.final_path=r"F:\Media\Film\Final"
self.headers={
'Connection':'Keep-Alive',
'Accept':'text/html,application/xhtml+xml,*/*',
'User-Agent':'Mozilla/5.0 (Linux; U; Android 6.0; zh-CN; MZ-m2 note Build/MRA58K) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/40.0.2214.89 MZBrowser/6.5.506 UWS/2.10.1.22 Mobile Safari/537.36'
}
def get_url_from_m3u8(self,readAdr):
print("正在解析真实下载地址...")
with open('temp.m3u8','wb') as file:
file.write(requests.get(readAdr).content)
m3u8Obj=m3u8.load('temp.m3u8')
print("解析完成")
return m3u8Obj.segments
def run(self):
print("Start!")
start_time=time.time()
os.chdir(self.down_path)
html=requests.get(self.url).text
bsObj=BeautifulSoup(html,'lxml')
tempStr = bsObj.find(class_="iplays").contents[3].string#通过class查找存放m3u8地址的组件
firstM3u8Adr=json.loads(tempStr.strip('var player_data='))["url"]#得到第一层m3u8地址
tempArr=firstM3u8Adr.rpartition('/')
realAdr="%s/500kb/hls/%s"%(tempArr[0],tempArr[2])#一定规律下对字符串拼接得到第二层地址, 得到真实m3u8下载地址,
key_url="%s/500kb/hls/key.key"%tempArr[0]#分析规律对字符串拼接得到key的地址
key=requests.get(key_url).content
fileName=bsObj.find(class_="video-title w100").contents[0].contents[0]#从源码中找到视频名称的规律
cryptor=AES.new(key,AES.MODE_CBC,key)#通过AES对ts进行解密
urlList=self.get_url_from_m3u8(realAdr)
urlRoot=tempArr[0]
i=1
for url in urlList:
resp=requests.get("%s/500kb/hls/%s"%(urlRoot,url.uri),headers=crawler.headers)
if len(key):
with open('clip%s.ts' % i, 'wb') as f:
f.write(cryptor.decrypt(resp.content))
print("正在下载clip%d" % i)
else:
with open('clip%s.ts'%i,'wb') as f:
f.write(resp.content)
print("正在下载clip%d"%i)
i+=1
print("下载完成!总共耗时%d s"%(time.time()-start_time))
print("接下来进行合并......")
os.system('copy/b %s\\*.ts %s\\%s.ts'%(self.down_path,self.final_path,fileName))
print("删除碎片源文件......")
files=os.listdir(self.down_path)
for filena in files:
del_file=self.down_path+'\\'+filena
os.remove(del_file)
print("碎片文件删除完成")
if __name__=='__main__':
crawler=VideoCrawler("地址大家自己找哦")
crawler.start()
crawler2=VideoCrawler("地址大家自己找哦")
crawler2.start()碰到的问题:
一、一开始以为电脑中Python环境中有模块就OK了,最后发现在Pycharm中自己虚拟的环境中还需要添加对应模块,
二、No module named Crypto.Cipher ,网上看了很多最后通过添加pycryptodome模块解决,电脑环境Win10
参考链接:
python m3u8视频ts解密合成完整mp4
Python爬取视频之爱情电影