MYSQL中更新数据超简单方法 replace into的用法 以及常规增删查改
今天在编程的时候,学习了replace into的用法,真的很好用,是insert into的增强版。在向表中插入数据时,我们经常会遇到这样的情况:1、首先判断数据是否存在;2、如果不存在,则插入;3、如果存在,则更新。
在SQL Server中可以这样处理:
if not exists (select 1 from t where id = 1)?
insert into t(id, update_time) values(1, getdate())
else
update t set update_time = getdate() where id = 1
那么 MySQL 中如何实现这样的逻辑呢?MySQL 中有更简单的方法: replace into
replace into t(id, update_time) values(1, now());
或
replace into t(id, update_time) select 1, now();
replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中, 1. 如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则,直接插入新数据。
要注意的是:插入数据的表必须有主键或者是唯一索引!否则的话,replace into 会直接插入数据,这将导致表中出现重复的数据。

MySQL replace into 有三种形式:
1. replace into tbl_name(col_name, ...) values(...)
2. replace into tbl_name(col_name, ...) select ...
3. replace into tbl_name set col_name=value, ...
第一种形式类似于insert into的用法,
第二种replace select的用法也类似于insert select,这种用法并不一定要求列名匹配,事实上,MYSQL甚至不关心select返回的列名,它需要的是列的位置。例如,replace into tb1( name, title, mood) select rname, rtitle, rmood from tb2;?这个例子使用replace into从?tb2中将所有数据导入tb1中。
第三种replace set用法类似于update set用法,使用一个例如“SET col_name = col_name + 1”的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
前两种形式用的多些。其中 “into” 关键字可以省略,不过最好加上 “into”,这样意思更加直观。另外,对于那些没有给予值的列,MySQL 将自动为这些列赋上默认值。
以下是我代码的简单案例:
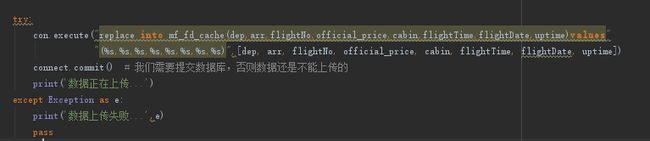
#找出ceshi表中id大于1030的
select * from ceshi where id>1030;
#找到ceshi表中flightDate列的日期为2017-12-28并且arr列为beijing的数据
SELECT * FROM ceshi where UNIX_TIMESTAMP(flightDate)=UNIX_TIMESTAMP('2017-12-28') and arr='beijing';
#ceshi表中id大于1044的official_price的值更改为10;
update ceshi set official_price='10' where id>1044;
#删除ceshi表中id=3的那一行
DELETE FROM ceshi WHERE id=3;
#将 ceshi表中获取 author 字段中以 COM 为结尾的的所有记录
SELECT * from ceshi WHERE author LIKE '%COM';
#删除ceshi表中id字段
ALTER TABLE ceshi DROP id;
#增加ceshi表中age字段,并定义数据类型
ALTER TABLE ceshi ADD age INT;
#查找name字段中以'st'为开头的所有数据:
SELECT name FROM ceshi WHERE name REGEXP '^st';
#查找name字段中以'ok'为结尾的所有数据:
SELECT name FROM ceshi WHERE name REGEXP 'ok$';
#查找name字段中包含'mar'字符串的所有数据:
SELECT name FROM ceshi WHERE name REGEXP 'mar';
#查找name字段中以元音字符开头或以'ok'字符串结尾的所有数据:
SELECT name FROM ceshi WHERE name REGEXP '^[aeiou]|ok$';
#将 ceshi 表中获取 runoob_author 字段中以 COM 为结尾的的所有记录取出
SELECT * from ceshi WHERE runoob_author LIKE '%COM';