配置开发者本地hadoop-3.0.0环境
1 配置开发者本地hadoop环境
参考网址:https://blog.csdn.net/songhaifengshuaige/article/details/79575308
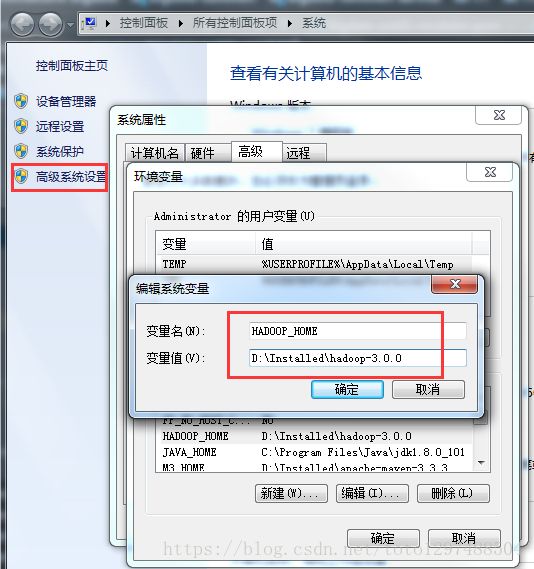
1.1.下载hadoop3.0.0并配置环境变量
1.2.集成支持windows下运行的hadoop的bin
关于winutils:除了Hadoop安装包和JDK外,还要下载的一个第三方工具是名为winutils的一套类库,下载地址:https://github.com/steveloughran/winutils
注意:如果使用是hadoop-3.0.0,也要将winutils中的所有的dll等文件都覆盖到hadoop目录的bin子目录中去。
解压后的winutils目录结构如下:
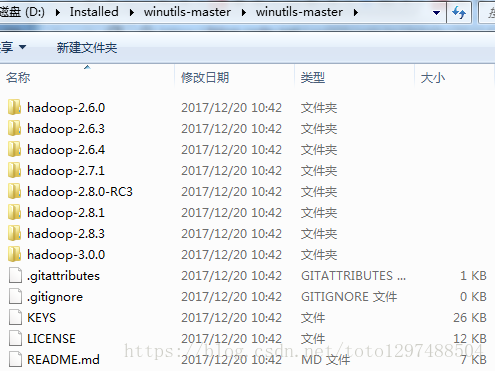

将上面的bin中的内容放到hadoop-3.0.0\bin中
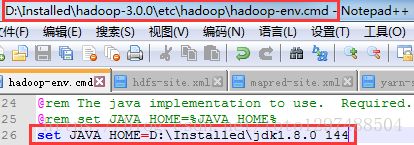
1.3.配置hadoop-env.cmd
关于hadoop的配置,在hadoop目录下的etc/hadoop下找到大量配置文件,文件后缀为sh的是Linux环境用的,cmd的就是windows的脚本,先要配置hadoop-env.cmd,这个文件(笔者电脑上的文件比如:D:\Installed\hadoop-3.0.0\etc\hadoop\hadoop-env.cmd)唯一要配置的地方是:
set JAVA_HOME=D:\Installed\jdk1.8.0_144注意:
1、 这里的JAVA_HOME地址中不能有空格。否则会报错。
1.4.配置core-site.xml
文件位置:D:\Installed\hadoop-3.0.0\etc\hadoop\core-site.xml,配置的文件内容是:
<configuration>
<property>
<name>fs.default.namename>
<value>hdfs://localhost:9000value>
property>
configuration>1.5.配置hdfs-site.xml
该文件是一些与hdfs有关的配置项,这里别忘了预先建立好datanode 和 namenode两个目录,本例中它们在hadoop所在盘符下的本例中他们在hadoop所在盘符下的hadoop/data/dfs/目录下。修改D:\Installed\hadoop-3.0.0\etc\hadoop\hdfs-site.xml。具体内容是:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/D:/Installed/hadoop-3.0.0/data/namenodevalue>
property>
<property>
<name>fs.checkpoint.dirname>
<value>/D:/Installed/hadoop-3.0.0/data/snnvalue>
property>
<property>
<name>fs.checkpoint.edits.dirname>
<value>/D:/Installed/hadoop-3.0.0/data/snnvalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/D:/Installed/hadoop-3.0.0/data/datanodevalue>
property>
configuration>1.6.配置mapred-site.xml
配置的文件是:D:\Installed\hadoop-3.0.0\etc\hadoop\mapred-site.xml,具体内容是:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>1.7.配置yarn-site.xml
配置的文件是:D:\Installed\hadoop-3.0.0\etc\hadoop\yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>1.8.运行hadoop
以管理员方式打开cmd,运行hadoop:
cd D:\Installed\hadoop-3.0.0\bin (或者:进入hadoop的这个bin目录,然后按着shift + 右键,点击在此处打开命令,然后弹出cmd窗口)
hadoop namenode –format #一定要先格式化hdfs执行之后的效果是:
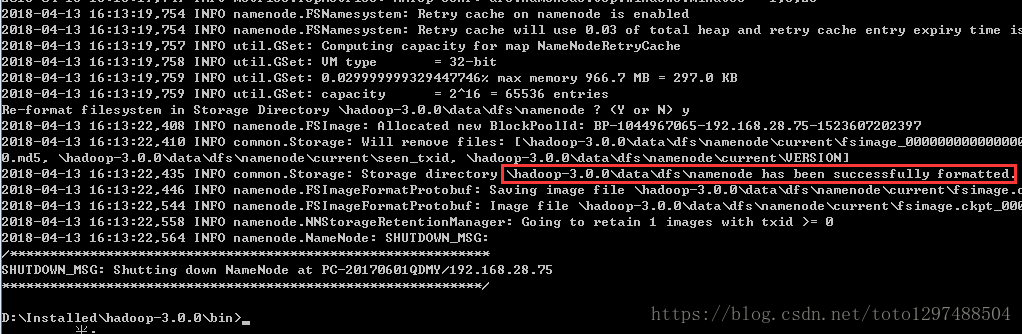
执行完成之后,在D盘下出现:
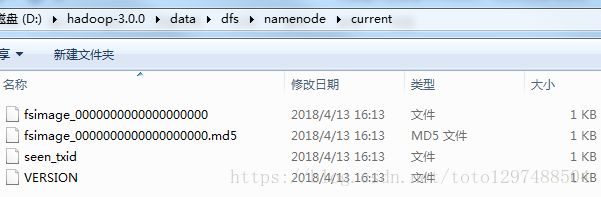
说明已经初始化完成了
启动dfs和yarn,命令:
cd D:\Installed\hadoop-3.0.0\sbin
start-dfs.cmd #先启动dfs
start-yarn.cmd #再启动yarn
start-all.cmd #等于上面两条命令的组合
stop-dfs.cmd
stop-yarn.cmd运行完成之后,访问地址:http://localhost:8088/

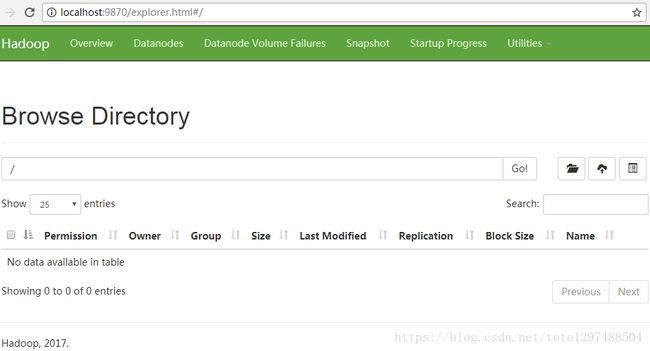
访问:http://localhost:9870/dfshealth.html#tab-overview