冲击SuperGLUE:基于多任务与对抗训练的Finetune方案解析

©PaperWeekly 原创 · 作者|Frank Luo
单位|追一科技AI Lab研究员
研究方向|自然语言处理

前言
英文通用语言理解评测基准 GLUE [1] 自提出以来,吸引了一大批预训练语言模型 (BERT [2],XLNET [3],RoBERTa [4],ALBERT [5],ERNIE [6],T5 [7]) 以及基于预训练模型进行迁移学习的工作 (MT-DNN [8],FreeLB [9],SMART [10])。
目前,通过对预训练模型进行下游任务 Finetune 是普遍的做法,而要在下游任务上得到好的效果,除了使用更好的预训练模型以外,如何针对不同的任务来设计 Finetune 的流程也是关键所在。
针对这个问题,我们以 RoBERTa 为 baseline 模型,在 SuperGLUE [11] 榜单上进行了一系列的尝试,通过多任务学习 (multitask learning),对抗训练 (adversarial training) 等方法,取得了第二的成绩。


数据介绍
数据集选取 选取 SuperGLUE 作为标的数据集主要是考虑到它的多样性以及整体难度两个方面。原 GLUE 数据集由 8 个句子/句子对分类任务组成,目前模型仅在 RTE,WNLI 两个任务上还未超过人类表现。
鉴于模型在 GLUE 上已经基本超过人类的表现,GLUE 的原作者保留了 RTE 和 WNLI 这两个任务 (其中 WNLI 仅改变了任务形式,更名为 WSC),并引入形式多样且更具挑战的 6 个任务,组成了新的语义理解基准 SuperGLUE,它共包含 8 个数据集,每个数据集针都是对语言的不同侧面设计了不同的任务,以求尽量从多个角度来考察模型的能力。
下面将简单介绍每个数据集的任务形式及特点,对数据集的分析能让我们对模型需要完成的事情有所了解,因此也会对模型与训练流程的设计提供思路。

RTE 与 CB 从任务形式来说,同为句子对分类任务,因此我们放到一起来介绍,但实际上两者背后考察的内容非常不同。
RTE 考察的是模型对文本蕴含的判断能力。RTE 数据集是继承自 GLUE 的一个数据集,目前还没有模型能够超过人类的分数。文本蕴含(自然语言推断)是语言理解的一项基本能力,而文本蕴含类型的任务其实涵盖了多个维度,从逻辑推理到常识知识都会覆盖。
而 CB 则是另一项非常有难度的任务,其任务设计是针对一个语言学现象(补语的语义投射),用此来考察模型是否像人一样具有语义投射的能力。
COPA 为多项选择,给定 premise,选择合适的选项作为它的 effect or cause。它的目标是考察模型对于常识的因果推断能力。
BoolQ 是一个判断是否的阅读理解任务。作者从搜索引擎的日志中筛选问句,再将问句与 Wiki page 中相应的段落对应,经过规则和人工筛选之后构建最终的数据集 [12]。尽管只需要回答是或否,但问题形式和种类多样。
MultiRC 是一个多项选择阅读理解任务。它的每个问题对应的答案是不唯一的,即存在一个或多个选项为正确答案。对于单个问题,答案可能分布在文章的不同句子中,模型需要从不同的地方验证每个答案是否正确。
ReCoRD 是一个完形填空式的多项选择阅读理解任务。作者从 CNN/DailyMail 中选取新闻的摘要部分作为任务的文章部分(context)。其任务的方式是在选取摘要中某一实体,然后从新闻的后续细节描述中选取包含该实体的句子,并人为从该句子中去掉该实体,用来作为任务的问题(query)[13]。
最终的 120k 个样本经过模型和人工筛从 770k 个样本中筛选出。这个任务的一大难点在于用做问题(query)的细节描述并不一定在摘要(context)中出现,因此为了完成任务,模型需要具备一定的常识或进行一定的推理。
WiC (word in context) 是一个词义消歧(Word Sense Disambiguity)任务。模型需要鉴别同一个词在两个不同句子中的含义是否相同。任务的难点在于,在两个完全不同含义的句子中,相同的词也可能有一样的含义。因此在特征处理上,除了两个句子的 interaction,还要考虑词在句子中的表征。
WSC 是一个指代消解的任务,与 GLUE 中的 WNLI 是同一个任务,只是更换了任务形式。它主要考察语意连续的一段文本中某对实体与代词是的指代是否一致。

模型改进
1. 基线模型
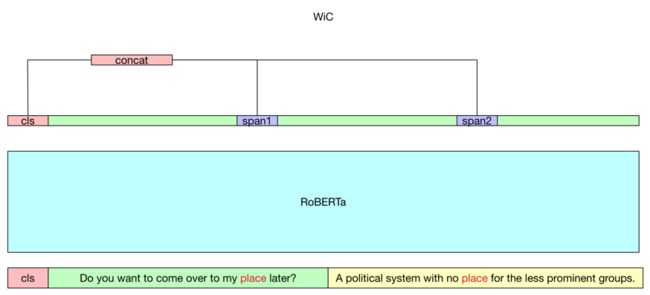
我们选用 RoBERTa 作为基线模型,并在 RoBERTa 的基础上根据下游任务形式进行不同的 adaptation。如下图所示,我们将任务归为分类、抽取,以及 WiC 和 WSC 两个比较独立的任务。
分类任务:我们采取拼接的方式将句子对或文章问题(答案)组拼接成一个序列,用特殊字符分隔,取序列的第一个 token 的编码向量进行分类。对于多项选择的 COPA 数据集,我们将两个选项进行拼接,然后取得到的两个序列的第一个 token 的编码向量进行分类。
WiC:因为考虑到句意不同,但词意相同的情况,我们需要拿到 word in context 的信息。这里我们取出两个句子中相同词的第一个 token 的编码向量 s1 和 s2,计算 ![]() ,最终与序列的第一个 token 拿到的向量做拼接,得到向量
,最终与序列的第一个 token 拿到的向量做拼接,得到向量 ![]() 再做分类。
再做分类。

WSC:基于 [14] 的做法,我们取训练样本中的正例,得到一段文本中正确的代词和实体对,随后用工具包 spacy 提取出文本中所有其他的实体与该代词构造负例。
如下图中 Fred watched TV while George went out to buy groceries. After an hour he got back.,我们可能会抽取到 Fred,George,TV,groceries,只有 George 和 he 是正确的代词和实体对。
训练时,我们取一对正确和错误的,将实体填入代词的位置之后输入模型,优化他们的 ranking loss。此外还使用正确的实体替换对应的代词后,mask 掉替换的实体,然后以 Masked LM 的方式来训练模型预测该实体。最终预测时,抽取出句子中所有的实体,通过 ranking 和 Masked LM 进行打分,选择分数最高的实体为代词正确的指代。

ReCoRD 是一个 cloze-style 的阅读理解任务,候选是篇章中出现的所有实体。在初期实验阶段,一个简单的想法是将每一个候选实体填入问题中,然后与篇章拼接,作为一个多项选择任务。但这样将会使得计算量变大,且可能减弱候选答案之间的相互关联。
因此这里我们尝试按抽取式阅读理解的方法处理,可以分为两种形式。一种是从篇章中抽取,我们将问题:
With bright lights illuminating his efforts from below, Mr **X** appears to be on the set of a sci-fi movie
改写为 What is X? question: With bright lights illuminating his efforts from below, Mr **X** appears to be on the set of a sci-fi movie,然后与篇章拼接。
我们在 RoBERTa 的基础上训练两个 head 表征用来预测实体的起始和终止,每个 head 表征对篇章序列的每个位置做一个三分类:1)正确候选实体起始/终止 ;2)错误候选实体起始/终止;3)其他。
另一个方案相对简单一些,是将所有的候选实体拼接成一个序列,置于问题后面,从拼接得到的候选中预测答案所在的位置。在我们的试验中,这两种方式都能比简单的多项选择得到更好的结果,并且减少训练和预测时间。

▲ 注:为了便于展示,图中的 cls 实际为 RoBERTa 中的 s,句子对拼接时的 /s 这里已经省略。
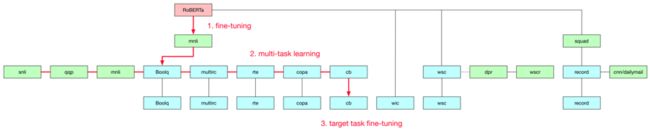
2. 多任务和迁移学习
多任务学习 (multitask learning) 能够借助多个相关任务互相提供监督信号,并且因为共享参数,因此可能可以为模型提供更好的泛化能力 [8] [15]。我们基于 SuperGLUE 各个数据集任务形式之间的关联性以及数据源的相关性,采取如图的多任务训练方式。
例如 CB 数据集,我们采用在 MNLI 上精调的 RoBERTa 模型为起始,联合 BoolQ,MultiRC 等进行多任务训练,取多任务训练中得到的一个 checkpoint,再在 CB 任务上进行精调。下表为部分数据集的对比结果(5 个不同的随机种子下的平均值)。第二行的结果 CB 和 BoolQ 是基于 RoBERTa-mnli 的模型,而 ReCoRD 则基于 RoBERTa-squad。
从结果中可以观察到,迁移学习和多任务学习都能带来提升,尤其是当迁移或多任务中一起训练的任务与目标任务有强相关的时候。这种强相关可以是任务形式相同,如 CB 和 MNLI 都属于判断 premise 和 hypothesis 之间的蕴含关系;或者是数据同源,如 ReCoRD、Squad 以及 CNN/Daily Mail 都当作抽取式任务处理。
同时也观察到引入 CNN/Daily Mail 带来的提升高于引入 Squad 带来的提升(Squad 和 ReCoRD 做多任务时效果更差),我们猜测原因是 ReCoRD 和 CNN/Daily Mail 数据集都是从 CNN 和 Daily 新闻网站的新闻构建的。

3. 对抗训练(adversarial training)
NLP 任务中,对抗训练能够有效的提升模型的泛化能力,以提高最终表现 [16] [17]。简单的一次对抗训练(Adversarial training)做法是计算在词向量处的梯度,得到一个最优的扰动,经过裁剪后加在词向量上得到对抗样本,再用该样本进行训练。
如果进一步,可以用虚拟对抗训练(virtual adversarial training),给词向量加一个小的随机扰动后,再计算词向量处的梯度,经过裁剪之后加在扰动前的词向量上,得到新的对抗样本,我们去优化对抗样本和正常样本在标签分布的 KL-divergence。对抗训练和虚拟对抗训练可以使 loss surface 更加光滑,从而增加模型的鲁棒性,AT 需要标签,而 VAT 不需要标签。
另一个符合直觉的理解是,对抗训练能够提升阅读理解任务的原因在于使长尾词得到了充分的训练 [18]。我们尝试在多任务训练和精调的时候使用对抗训练(Adversarial Training)。
由于虚拟对抗训练(Virtual adversarial training)带来的提升有限,但会使得训练量翻倍因此最终没有采用,结果如下表(5 个不同的随机种子下的平均值)。比较原设置和去掉对抗训练之后的设置,可以看到对抗训练在多任务和精调时都能提升模型的表现。

4. EMA + Knowledge Distilling (Mean-Teacher)
大型的预训练语言模型会遇到的一个问题是参数过多,导致精调下游任务时候训练不稳定,训练波动大。滑动平均(Exponential Moving Average)能够有效的缓解这一点。
Mean-teacher [19] 通过 EMA 在训练时维持一个 teacher 模型,然后用 teacher 模型去指导当前模型的训练,再由当前模型以 EMA 的方式更新 teacher 模型。这样能在 EMA 的基础上更进一步提高模型的鲁棒性。
通常认为 mean-teacher 训练时,通过 EMA 维持的 teacher 模型和 student 模型存在正反馈机制,即更好的 teacher 模型能够指导得到更好的 student 模型,反过来通过 EMA 更新得到更好的 teacher 模型。
式 (1) (2) 为原 mean-teacher 论文的 consistency cost J,其中 θ' 为 teacher 模型的权重,η 和 η' 为加在模型输入的随机噪声。我们尝试使用 KL-divergence 替换 ![]() 中的
中的 ![]() loss (式(3)),去掉了输入噪声 η 和 η'。最终的目标函数为式 (4),其中
loss (式(3)),去掉了输入噪声 η 和 η'。最终的目标函数为式 (4),其中  为原有监督任务。
为原有监督任务。
由于模型在训练初期权重有较大变化,且 EMA 得到的模型效果较差,我们在训练初期使用较大的 EMA decay (α=0.99) ,随后调整使用较小的 decay (α=0.999) ,同时我们线性地增大权重 w,最终结果如下表(5个不同的随机种子下的平均值)。可以看到 EMA 能提升模型的表现,引入 mean-teacher 后模型有进一步提升。



经验总结
我们基于 Facebook 开源的 RoBERTa 预训练模型在 SuperGLUE 上探索了不同的 finetune 方式。通过调整任务、多任务学习、对抗训练等在 SuperGLUE 的 6 个数据上都得到了提升,最终对比原始 RoBERTa 提升了 1 个百分点,目前处于榜单第二的位置。但相比于 T5,还有很大的差距。
从评测基准的榜单来看,预训练语言模型本身的提升对下游任务来说目前还是最为显著的,尤其是在任务形式多样的评测基准上。而在给定预训练模型的情况下进行下游任务时,在调整模型结构适应任务的同时,增强模型泛化能力和鲁棒性的手段可以得到较为一致的效果提升。我们在这次尝试中用了多任务训练,对抗训练,mean-teacher 以及一些正则来达到这一目的。
我们接下来希望能显式地将常识知识融入模型中,而这部分也是 SuperGLUE 任务比较关心的一点。可以看到 WSC 和 COPA 上人类都是满分,而 RTE 上人类仍然领先,目前的预训练,多任务学习离真正的常识推理还有很大的进步空间。

Reference
[1] GLUE https://gluebenchmark.com
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/pdf/1810.04805.pdf
[3] XLNet: Generalized Autoregressive Pretraining for Language Understanding https://arxiv.org/pdf/1906.08237
[4] RoBERTa: A Robustly Optimized BERT Pretraining Approach https://arxiv.org/pdf/1907.11692
[5] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations https://arxiv.org/pdf/1909.11942
[6] ERNIE 2.0: A Continual Pre-training Framework for Language Understanding https://arxiv.org/pdf/1907.12412v1
[7] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer https://arxiv.org/pdf/1910.10683.pdf
[8] Multi-Task Deep Neural Networks for Natural Language Understanding https://arxiv.org/abs/1901.11504
[9] FreeLB: Enhanced Adversarial Training for Language Understanding https://arxiv.org/abs/1909.11764
[10] SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization https://arxiv.org/pdf/1911.03437
[11] SuperGLUE https://super.gluebenchmark.com
[12] BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions https://arxiv.org/pdf/1905.10044.pdf
[13] ReCoRD: Bridging the Gap between Human and Machine Commonsense Reading Comprehension https://arxiv.org/pdf/1810.12885.pdf
[14] A Surprisingly Robust Trick for Winograd Schema Challenge https://arxiv.org/pdf/1905.06290.pdf
[15] Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval https://www.aclweb.org/anthology/N15-1092.pdf
[16] Revisiting LSTM Networks for Semi-Supervised Text Classification via Mixed Objective Function https://www.aaai.org/ojs/index.php/AAAI/article/view/4672
[17] Adversarial Training Methods for Semi-Supervised Text Classification https://arxiv.org/pdf/1605.07725
[18] Improving Machine Reading Comprehension via Adversarial Training https://arxiv.org/pdf/1911.03614.pdf
[19] Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results https://arxiv.org/pdf/1703.01780.pdf

点击以下标题查看更多往期内容:
刷新SQuAD2.0 | 上海交通大学回顾式阅读器解析
浅谈 Knowledge-Injected BERTs
细粒度情感分析任务(ABSA)的最新进展
自然语言处理中的语言模型预训练方法
BERT+知识图谱:知识赋能的K-BERT模型
从三大顶会论文看百变Self-Attention
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 获取最新论文推荐