概述
原型模式是为了解决一些不必要的对象创建过程。当Java JDK中提供了Cloneable接口之后,原型模式就变得异常的简单了。虽然由于Cloneable的引入使用程序变得更简单了,不过还是有一些需要说明和注意的东西在里面的。文本就详细讲解一下这些注意事项吧。
版权说明
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
本文作者:Coding-Naga
发表日期: 2016年3月3日
本文链接:http://blog.csdn.net/lemon_tree12138/article/details/50787390
来源:CSDN
更多内容:分类 >> 设计模式
拷贝技术详解
1.对象赋值
如果现在有一个Student对象s1,当我们使用s2=s1的方式对s2进行赋值时,实则是将s1对象的引用复制给了s2。过程如下:
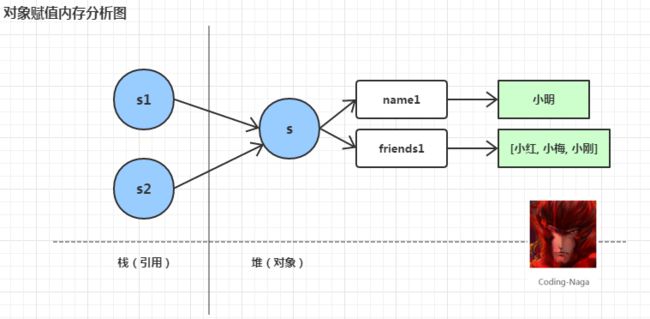
图-1 对象赋值内存分析图
所以,对于s1与s2它们所指内存应该为同一块区域。下面为此两个“对象”所占用的内存地址:
org.design.pattern.prototype.model.Student@659e0bfd
org.design.pattern.prototype.model.Student@659e0bfd2.浅拷贝
什么是浅拷贝?浅拷贝后的结果是对象的内存地址变化了(对象的引用发生了变化),可对象中包含的对象内存则没有变化。
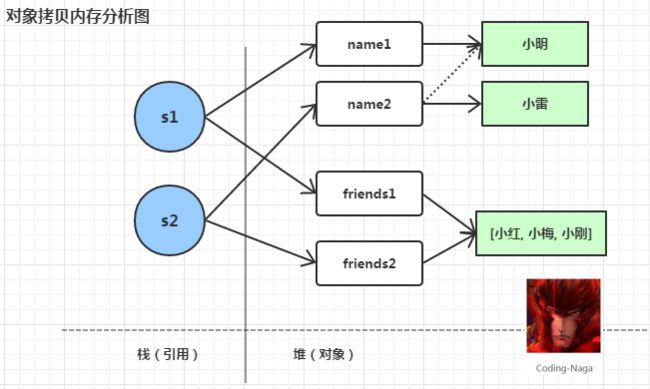
图-2 对象拷贝内存分析图
大家看到上面的分析图是不是有一些疑惑?为什么name发生了变化,而friends却没有变化呢?
这里先不用说其他的数据类型(int, double, char, short, long, float, byte),我们知道String类型的对象是不可变对象,当我们对不可变对象进行赋值时,它会另外开辟一个新对象。因为这个特性可能会影响到我们对Cloneable的正确判断,所以这里需要使用一个可变对象来进行实验。我选择的是:List。
假使初始状态是:s1有两个朋友,小红和小梅。当我们使用List的可变性向s2的朋友List中添加了一个新朋友时,理论上只是s2的朋友被修改了,可是实事上并非如此,以下为实验结果:
初始的List对象:
s1.friends: [小红, 小梅]
s2.friends: [小红, 小梅]
不改变List对象:
s1.friends: [小红, 小梅, 小刚]
s2.friends: [小红, 小梅, 小刚]
重新对List对象赋值:
s1.friends: [小红, 小梅, 小刚]
s2.friends: null3.深拷贝
上面说到对象的浅拷贝,在拷贝中我们对可变对象的操作有一些棘手。而深拷贝则可以解决这个问题。深拷贝的实现要依赖与对象的持久化操作。更多关于对象持久化的内容可参见本人另一篇博客:《网络爬虫:基于对象持久化实现爬虫现场快速还原》。
对象持久化是说把一个对象写到文件中(或是向网络,或是向进程之间进行传输),当我们需要拷贝一个对象时,先把此对象固化到文件,再从文件中读取对象。这样一个过程就完成了对象的深拷贝,在博客《网络爬虫:基于对象持久化实现爬虫现场快速还原》中我也有详细地说明,这里就不再赘述了。
原型模式实现
终于可以说本文的主题(原型模式)了。
原型模式是基于对象的拷贝的,可以是浅拷贝也可以是深拷贝操作。也就是说当我们需要批量生成某一对象,就可以事先创建一个对象的原型,再通过对象的拷贝操作批量生成对象。原型模式的实现类图如下:
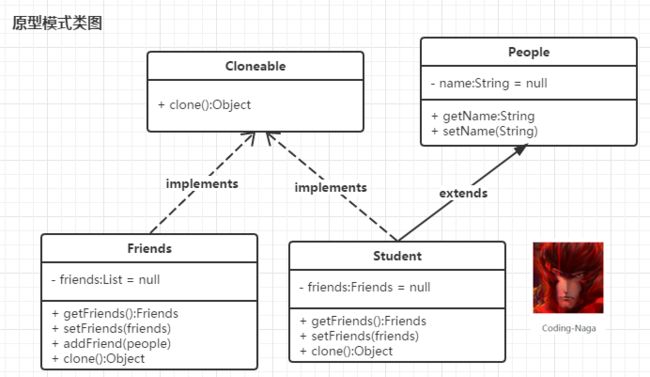
图-3 原型模式类图
性能测试
这里我们测试一下原型模式的性能。public static void pressureTesting() throws CloneNotSupportedException {
int times = 100000000;
Student student = new Student("小明");
student.addFriend(new People("Friend-A"));
student.addFriend(new People("Friend-B"));
student.addFriend(new People("Friend-C"));
student.addFriend(new People("Friend-D"));
student.addFriend(new People("Friend-E"));
long startStamp = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
student.clone();
}
long currentStamp = System.currentTimeMillis();
System.out.println("TIME USED: " + (currentStamp - startStamp) + " ms");
startStamp = System.currentTimeMillis();
for (int i = 0; i < times; i++) {
Student student2 = new Student("小红");
student2.addFriend(new People("Friend-A"));
student2.addFriend(new People("Friend-B"));
student2.addFriend(new People("Friend-C"));
student2.addFriend(new People("Friend-D"));
student2.addFriend(new People("Friend-E"));
}
currentStamp = System.currentTimeMillis();
System.out.println("TIME USED: " + (currentStamp - startStamp) + " ms");
}TIME USED: 1752 ms
TIME USED: 4352 msRef
- 《23种Java设计模式》
- 《编写高质量代码 : 改善Java程序的151个建议》
Github源码下载
https://github.com/William-Hai/DesignPatternCollections