基于表征(Representation)形式的文本匹配、信息检索、向量召回的方法总结(用于召回、或者粗排)
文章目录
- 总结
- 文本匹配的两种做法
- Representation-Based类模型
- Interaction-Based 模型
- Representation-Based改进方法
- 从信息交互方面思考
- BERT类模型Pre-train任务
- 论文细节
- ColBERT
- 模型结构
- Query Encoder
- Document Encoder
- Late Interaction
- 训练方式
- Poly-encoder
- 模型结构
- Context Encoder
- Candidate Encoder
- Context的隐层表示计算(控制模型大小)
- Context和Candidate交互
- Score计算
- 计算时间比较
- PRE-TRAINING TASKS FOR EMBEDDING-BASED LARGE-SCALE RETRIEVAL
- 模型结构
- 训练方式
- 关于Sampled Softmax
- 三个Pre-train task设计
- Inverse Cloze Task(ICT)
- Body First Selection (BFS)
- Wiki Link Prediction (WLP)
- Masked LM (MLM)
- 后记
最近系统性的看了一些有关于信息检索、文本匹配方向的论文,先贴下三篇主角论文:
(ColBERT) Khattab, O., & Zaharia, M. (2020). ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. ArXiv, abs/2004.12832. [PDF]
(Poly-encoders) Humeau, S., Shuster, K., Lachaux, M., & Weston, J. (2020). Poly-encoders: Architectures and Pre-training Strategies for Fast and Accurate Multi-sentence Scoring. ICLR.[PDF]
Chang, W., Yu, F.X., Chang, Y., Yang, Y., & Kumar, S. (2020). Pre-training Tasks for Embedding-based Large-scale Retrieval. ArXiv, abs/2002.03932.[PDF]
总结
上面三篇论文针对的基础NLP任务都是文本匹配,文本匹配可以用于许多下游具体任务,例如:
- 信息检索(information retrieve) (召回和排序)
- 释义识别(Paraphrase Identification)
- 自然语言推理(NLI)
- 问答匹配(QA)
- …
上面三篇论文主要是针对信息检索中的召回和排序,并且使用均为Representation-based方法,ColBERT、Poly-encoders中使用了弱交互来增强模型的表达能力,一定程度上解决了类似于word2Vec中学习出来的是静态向量的问题。Pre-training Tasks for Embedding-based Large-scale Retrieval 论文中则是针对信息检索设计了Inverse Cloze Task(ICT)、Body First Selection (BFS)、Wiki Link
Prediction (WLP) 三个Pre-train任务来提高模型的效果。
文本匹配的两种做法
Representation-Based类模型

传统的Representation-Based模型如上图所示,Query端和Doc端分别计算隐层表示(比如说用BERT计算,取最后一层的向量作为表示),最后选择Score function(如dot product,cosine similarity)计算相似度。这种方式由于失去了Query-Doc之间的交互,可能会产生语义漂移,精度相对来说不是太高,所以一般用来做向量召回或者粗排
- 经典模型:DSSM,SNRM
- 优点:计算量少,Document可以离线处理得到其表征,线上运行时,只需要在线计算Query端的隐层表示,而Doc端的隐层表示可以通过查询得到,非常适合精度要求不高,速度要求较快的场合
- 缺点:失去了交互信息,类似于Word2Vec的问题,学习出来的是一个静态向量,不同上下文场景下,都是同一个表达
从上面的分析可以看出,Representation-Based模型问题主要在于学习出来的语义表达有局限性,Query-Doc没有交互,没有上下文的信息。上面三篇论文也就是针对这些问题进行改进
- ColBERT、Poly-encoders则是在原始的Representation-Based模型中增加了弱交互,这种方法既丰富了模型的表达能力,又不会增加太大的计算量,并且Doc端还是能够进行预处理,保证了在线运行的速度。
- 而 Pre-training Tasks for Embedding-based Large-scale Retrieval 则是另辟蹊径,引入了三种新的Pre-train Task来提高模型对query和Doc语义信息不同粒度的理解。
Interaction-Based 模型

Interaction-Based模型结构如上图所示,Query和Doc端会做交互运算,这样可以很好地考虑上下文语境信息,不同query下,同一个Doc的表示是不同的,可以抓住语义焦点,模型的精度较高,经常用于信息检索中的精排。但是这种方法输入不同query和Doc都需要重新计算,并不能像Representation模型一样对Doc进行预处理。
- 经典模型:DeepMatch、 DRMM、KNRM、基于BERT的交互模型
- 优点:对上下文环境建模,能够抓住一些重要信息,模型精度较高,可以用于精排
- 缺点:速度慢,每次都需要计算Query和Doc的交互,当数据集很大的时候难以上线运行。
Representation-Based改进方法
从信息交互方面思考
从上面的分析可以看出,Representation-Based方法的主要缺陷在于Query端与Doc过于分离,完全没有进行信息交互,这样导致模型表达为一个静态向量,表达能力受限。但是如果像Interaction-Based方法那样,对Query和Doc端的每个词进行交互,将会有大量的运算,整个模型会非常大,训练时间和预测时间都会很长,难以在线运行。
- 所以,我们的重点是如何在尽量少的计算量条件下,进行Query与Doc的信息交互
弱交互,我们计算Query与Doc的Representation时,并不进行交互,而是在获得相应Representation输出后再进行交互,最后通过交互后的表达计算相似度
论文ColBERT、Poly-encoder中都是使用了这种弱交互的思想,在获取Representation之后,再进行Interaction这样既保证了运算的速度,又提高的模型的表达能力,ColBERT和Poly-encoder模型图如下所示:
-
Col-BERT Late Interaction

-
Poly-encoder attention

从上面的结构图可以看出,这两个模型在Encoder计算Query、Doc隐层表示时都是单独计算,而在Represetation输出时,计算相似度之前加入了Interaction,不同的是两个模型的Interaction方式不太一样,这个后面会具体介绍细节。
BERT类模型Pre-train任务
BERT提出之后,许多NLP任务用BERT都可以达到很好的效果,文本匹配也不例外。BERT分为Pre-train Fine-tune两阶段,因此用BERT类模型做Representation-Based 文本匹配还有个改进方法就是:设计合适的Pre-train任务,提高我们下游Fine-tune时的效果。在Fine-tune时我们的有监督的数据集通常来说比较少(有监督数据需要标注,难以获取),当加入合适的Pre-train之后,我们就可以用上大量的无监督数据,从而提高我们Fine-tune 的效果,通常来说我们设计Pre-train任务时需要注重以下几点:
- Pre-train任务应该与下游任务相关。比如我们需要解决信息检索的文本匹配问题,那么我们的模型应该能够理解Query和Doc之间不同粒度的语义信息。
- 同一段落之中的局部窗口两句话之间的语义关联
- 一个Document中的全局一致的语义信息(归纳理解)
- 两个Document之间的语义信息关联
- Pre-train的数据应当容易获取,不需要额外的人工标注
论文细节
ColBERT
模型结构
ColBERT的模型结构整体还是类似于Siamese结构,分为Query端和Doc端,最后在进行交互计算文本分相似度,如下图所示:

模型主体上分为Query Encoder, f Q f_Q fQ 、Document Encoder, f D f_D fD ,以及之后的Late Interaction部分,从图中可以看出Document还是可以离线处理的,
Query Encoder
![]()
Query Encoder计算如下,BERT表示为标准的BERT运算,CNN是做维度变换,用来对BERT输出降维,Normalize是方便之后计算余弦相似度。
Document Encoder
![]()
因为Doc一般比较长,所以和Query Encoder的主要区别是最后加入了Filter,用来去除Doc那么标点符号,停用词的Representation,这样可以减少每个Doc embedding的个数。
Late Interaction
这一步操作则是针对与Representation-Based方法的改进,对Query和Doc的信息进行了交互,具体公式如下:

由于之前进行过Normalize,我们只需要计算 inner-products得到的即为余弦相似度
训练方式
ColBERT训练方式用的也是Learning2Rank中的pairwise Loss,最大化相关Doc和无关Doc的分数差。
Poly-encoder
模型结构

模型结构和ColBERT大体类似,唯一不同的地方在于获得Representation之后query和Doc交互方法,这里用的是基于attention 的方法
Context Encoder
query端的Encoder,对query中的每个词计算出一个embedding
Candidate Encoder
Candidate端的Encoder,也是对Doc中的每个词计算出一个embedding,并且会经过Candidate Aggregator操作,将其变为一个向量,比如BERT中可以取第一个[CLS]的值作为表示,或者取平均
Context的隐层表示计算(控制模型大小)
poly-encoder中使用m个global features来表示input,m为超参数,会影响推断时候的速度。我们学习m个上下文向量 ( c 1 , c 2 , . . . , c m ) (c_1,c_2,...,c_m) (c1,c2,...,cm),其中 c i c_i ci用来抽取第 i i i个隐层表示 y c t x t i y^i_{ctxt} yctxti。计算方法如下:

可以知道,上面的m个向量用来做attention中的Query向量,Key向量和Value向量为计算出来的隐层表示 h i h_i hi。上述m个向量随机初始化,并且在finetuning过程中进行学习。
Context和Candidate交互
最后,要进行Context和Candidate交互,从而获得Context最后的表达,类似如上面的attention,在这一步,使用 y c a n d y_{cand} ycand作为Query向量,Key和Value向量为由上面m个向量计算出来的 y c t x t y_{ctxt} yctxt,计算方法如下:

y c t x t y_{ctxt} yctxt即为经过交互之后的最终的隐层表达。
Score计算
最终的Score为 y c t x t ⋅ y c a n d y_{ctxt} \cdot y_{cand} yctxt⋅ycand,我们可以选取 m < N ,N为context Token数量,这样就可以大大减少计算量
计算时间比较
这里贴一张论文中的计算时间比较表格,可以看出Poly-encoder加入Interaction之后,计算时间并没有太大增加,还是远远小于 Cross-encoder(Interaction方式)

PRE-TRAINING TASKS FOR EMBEDDING-BASED LARGE-SCALE RETRIEVAL
模型结构
这篇论文方法模型结构还是标准的Representation结构,主要的改进的是添加了三个针对性的Pre-train Task。

训练方式
论文中假设训练数据均为,relevant positive Queryt-Doc 对
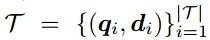
我们的训练目标是最大化Softmax条件概率:

其中 D \mathcal D D为所有可能文档的集合,这样会有个问题,因为候选文档集合可能会非常大,所以论文中使用了Sampled Softmax对训练过程进行近似,原文如下:
The Softmax involves computing the expensive denominator of Equation (3), a.k.a, the partition function, that scales linearly to the number of documents.In practice, we use the Sampled Softmax, an approximation of the full-Softmax where we replace D by a small subset of documents in the current batch, with a proper correcting term to ensure the unbiasedness of the partition function
关于Sampled Softmax
- 其实关于Sampled Softmax具体训练方法,这篇论文并没有具体说,代码也没有开源,我也不是很理解,下面是一些关于Sampled Softmax的博客:
- TF Notes (6), Candidate Sampling, Sampled Softmax Loss
- softmax with candidate sampling
- 候选采样(candidate sampling)
- TensorFlow中有关于Sampled Softmax API,如下所示
tf.nn.sampled_softmax_loss(weights, # Shape (num_classes, dim) - floatXX
biases, # Shape (num_classes) - floatXX
labels, # Shape (batch_size, num_true) - int64
inputs, # Shape (batch_size, dim) - floatXX
num_sampled, # - int
num_classes, # - int
num_true=1,
sampled_values=None,
remove_accidental_hits=True,
partition_strategy="mod",
name="sampled_softmax_loss")
其中 :
- input 为输入,这里应该为Query embedding
- weights,原本是类别输出变换的全连接层,比如输出为十个类别那么就是
(10,dim),这里的话难道是(num_documents,dims)?不是很理解,num_documents应该是千万级别的
不太理解到底怎么使用Sampled Softmax 来对上述任务进行训练,求大神们指点一下
三个Pre-train task设计
这篇论文针对性的设计了三个Pre-train task,设计的原则如下:
- Pre-train任务应该与下游任务相关。比如我们需要解决信息检索的文本匹配问题,那么我们的模型应该能够理解Query和Doc之间不同粒度的语义信息。
- Pre-train的数据应当容易获取,不需要额外的人工标注
Pre-train数据均为positive Query-document对.
Inverse Cloze Task(ICT)
- 同一段落之中的局部窗口两句话之间的语义关联
- 给定一个passage p \bold p p有n个句子, p = { s 1 , s 2 , s 3 . . . , s n } \bold p = \{\bold s_1,\bold s_2,\bold s_3...,\bold s_n\} p={s1,s2,s3...,sn},那么 q \bold q q 则是从这n个句子中随机采样出来的一个句子 q = s i \bold q = \bold s_i q=si ,剩余的句子则是 d = { s 1 , s 2 , s 3 . . . , s i − 1 , s i + 1 , . . s n } \bold d = \{\bold s_1,\bold s_2,\bold s_3...,\bold s_{i-1},\bold s_{i+1},..\bold s_n\} d={s1,s2,s3...,si−1,si+1,..sn}

Body First Selection (BFS)
- 一个Document中的全局一致的语义信息(归纳理解)
- q \bold q q是总Wikipage 第一段中随机选出来的句子,这个句子通常是整个页面的描述或者总结。 d \bold d d则是同一页面中随机选取的一个passage

Wiki Link Prediction (WLP)
- 两个Document之间的语义信息关联
- q \bold q q是总Wikipage 第一段中随机选出来的句子, d \bold d d是另外一个页面中的passage,而该句子中有超链接到 q \bold q q页面

上面三个Task训练方式则是上面说的极大化Softmax似然
Masked LM (MLM)
论文中也加入了Masked Language Model 的task
后记
信息检索中通常需要在大量文档中进行召回和排序,所以运行速度是一个很重要的因素,Interaction-Based方法由于运算量太大通常不适合在线的场景,而Representation-Based在提高速度的同时也限制了模型表达能力,上面三篇论文针对性地改进了Representation-Based的缺陷。
上面的模型应用于向量召回和粗排应该效果不错,之后有机会实际跑一下数据,在进行技术的总结,以上都是我自己对论文的理解,有很多细节可能不是很到位,欢迎大家和我讨论~