如何优雅的理解PageRank
博客引流
一口气开始别憋气
终于Tex调好了 刚好最近又多次提及PageRank 于是~
目测这一系列 有个两三篇blog
PageRank 是 由佩奇(Larry Page)等人提出 的 Google 最为有名的技术之一
我 乔治 甘拜下风
PageRank 是一种基于随机游走 的 评价网站权值的算法
言而总之 PageRank是一种十分重要的算法 不管在学术界 还是在产业界
Node Similarity & Proximity
在介绍PageRank 需要先来提一下 什么叫节点相似
假设在一个有向图集合G(V, E)中研究两个节点u, v之间的相关性
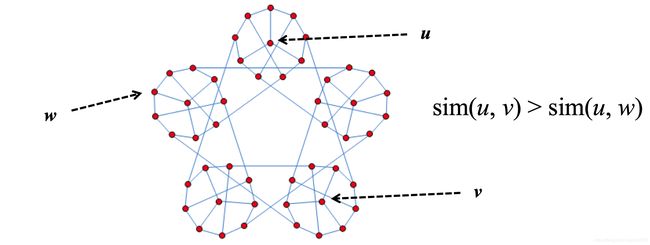
上图, 我们可以从感性的认识上判断u, v之间的相似高要比u, w之间的相似度要高
那如何来具体定义相似度呢
Common neighbor
我们很容易可以想到 好像 一个节点的邻居集合可以表征这个节点的周围结构
实际上这就是CN算法(common neighbor)
规定 C N ( u , v ) = n e i ( u ) ∩ n e i ( v ) CN(u, v)=nei(u)\cap nei(v) CN(u,v)=nei(u)∩nei(v)
Jaccard
单纯的数值对于估计一个节点的相似度 可能存在标准不统一的情况
故jaccard在CN的基础上做了一个归一化的处理
得到 J a c c a r d = C N ( u , v ) n e i ( u ) ∪ n e i ( v ) Jaccard=\dfrac{CN(u, v)}{nei(u)\cup nei(v)} Jaccard=nei(u)∪nei(v)CN(u,v)
Adamic-Adar Index
A d a m i c − A d a r I n d e x = ∑ 1 l o g N ( v ) Adamic-Adar Index=\sum \dfrac{1}{logN(v)} Adamic−AdarIndex=∑logN(v)1
当然还可以按计算时用到部分点还是全部点来进行分类
local- Common Neighbors(CN), Jaccard, Adamic-Adar Index
grobal- Personalized PageRank(PPR), SimRank, Katz
事实上 节点相似度在生产过程中有极强的落地场景
尤其是和社交网络分析相关的好友推荐
另外 还可以运用在Top-k的关系发现当中
传言王者荣耀的好友推荐 就是用PPR做的
最后需要提一句 N o d e S i m i l a r i t y ̸ = N o d e P r o x i m i t y Node Similarity\not = Node Proximity NodeSimilarity̸=NodeProximity
一般而言, s i m ( u , v ) = s i m ( v , u ) sim(u, v) = sim(v, u) sim(u,v)=sim(v,u), 但 p ( u , v ) ̸ = p ( v , u ) p(u, v) \not = p(v, u) p(u,v)̸=p(v,u)
Naive PageRank
P R ( u ) = ∑ v ∈ N i n ( u ) N 1 N o u t ( v ) P R ( v ) PR(u)=\sum\limits_{v \in N_{in}(u)}^N \dfrac{1}{N_{out}(v)}PR(v) PR(u)=v∈Nin(u)∑NNout(v)1PR(v)
S.t. P R ( u ) ≥ 0 PR(u) \ge 0 PR(u)≥0, ∑ P R = 1 \sum PR = 1 ∑PR=1
直观上看PR值的计算是一个迭代的过程,通过出度把PR值分配给下游节点
但Naive PageRank在计算的过程中会出现一些问题
P R ⃗ = P T ⋅ P R ⃗ \vec {PR} = P^T \cdot\vec{PR} PR=PT⋅PR,其中 P P P为行向量
故 P R ⃗ T = P R ⃗ T ⋅ P \vec {PR}^T = \vec{PR} ^T \cdot P PRT=PRT⋅P
因为上述PageRank的定义是一个递归过程,所以需要一个递归停止条件-Error
m a x ∣ P R ⃗ ( l + 1 ) ( i ) − P R ⃗ ( l ) ( i ) ∣ ≤ ϵ max|\vec {PR}^{(l+1)}(i) - \vec {PR}^{(l)}(i)|\le \epsilon max∣PR(l+1)(i)−PR(l)(i)∣≤ϵ
其实严格上还需要证明上述递推关系的收敛性 , 事实上Naive PageRank是不一定收敛的
当然还有解的存在性,唯一性 等等
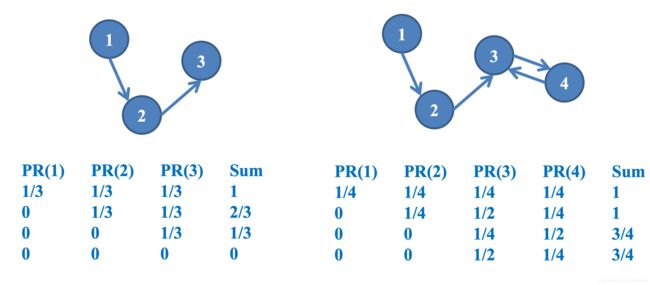
Flaw 1 Multiple Solutions

对于图示这种情况 PR的值其实有无数钟取法
只要满足 P R a = P R b = P R c , P R p = P R q = P R r PR_a = PR_b = PR_c, PR_p = PR_q = PR_r PRa=PRb=PRc,PRp=PRq=PRr
Flaw 2 Link Spam
还是上面的例子a, b, c 此时 P R a = P R b = P R c = 1 3 PR_a = PR_b = PR_c = \dfrac{1}{3} PRa=PRb=PRc=31
如果把 c − > a c->a c−>a的边改为 c − > b c->b c−>b, 迭代后就会造成 P R a = 0 , P R b = P R c = 1 2 PR_a = 0, PR_b = PR_c = \dfrac{1}{2} PRa=0,PRb=PRc=21
当一个平衡建立之后,如果因为少数几个节点的异常更改,就会造成全部PR值的改变,这就很容易导致少数几个节点操控整个系统的PR值
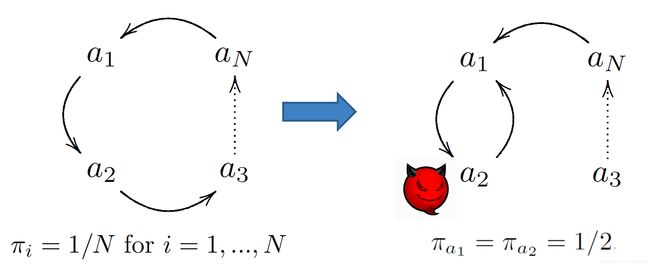
Flaw 3 Dead Ends and Spider Traps
其实仔细想一想 Flaw2是因为其他节点变得没有入度造成的
那么如果有那么一些点是只入不出的,则会造成PR值随着迭代向该点聚集
这样的点 可以看做 强连通子图
PageRank
为解决上述的问题 佩奇 提出 P R ( ) = α ∑ v ∈ N i n ( u ) N 1 N o u t ( v ) P R ( v ) + ( 1 − α ) 1 n PR() =\alpha \sum\limits_{v \in N_{in}(u)}^N \dfrac{1}{N_{out}(v)}PR(v) + (1-\alpha) \dfrac{1}{n} PR()=αv∈Nin(u)∑NNout(v)1PR(v)+(1−α)n1
相对于Naive PageRank 相对于做了一个平滑处理 给一个偏置量
- Flaw 1. P R ( a ) = P R ( b ) = P R ( c ) = P R ( p ) = P R ( q ) = P R ( r ) = 1 6 PR(a) = PR(b) = PR(c) = PR(p) = PR(q) = PR(r) = \dfrac{1}{6} PR(a)=PR(b)=PR(c)=PR(p)=PR(q)=PR(r)=61
- Flaw 2. 减少出现Link Spam的可能性
- Flaw 3. Doesn’t help ☹
- 移除没有出度的节点或者结构
- 加一条回边
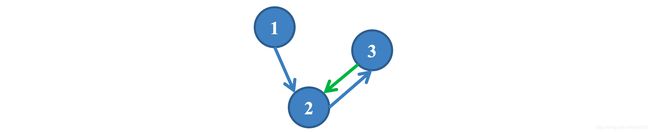
正如前面所说的,因为PageRank define by 递归
所以,我们需要证明解的存在性,唯一性,收敛性,此处省略若干证明
收敛性: 我们用矩阵形式表示 π = P R ⃗ \pi = \vec {PR} π=PR
则根据上述定义可得, π v ( t ) = ( 1 − ϵ ) ∑ ( w , v ) ∈ E π w ( t − 1 ) d w + ϵ n \pi_v^{(t)}= (1-\epsilon)\sum\limits_{(w,v) \in E} \dfrac{\pi_w^{(t-1)}}{d_w}+\dfrac{\epsilon}{n} πv(t)=(1−ϵ)(w,v)∈E∑dwπw(t−1)+nϵ
Let E r r ( t ) = ∑ v ∣ π v ( t ) − π v ∗ ∣ Err(t)=\sum\limits_v|\pi_v^{(t)}-\pi_v^*| Err(t)=v∑∣πv(t)−πv∗∣
而 ∣ π v ( t ) − π v ∗ ∣ ≤ ( 1 − ϵ ) ∑ ( w , v ) ∈ E π w ( t − 1 ) − π w ∗ d w |\pi_v^{(t)}-\pi_v^*| \le (1-\epsilon)\sum\limits_{(w,v) \in E} \dfrac{\pi_w^{(t-1)} - \pi_w^*}{d_w} ∣πv(t)−πv∗∣≤(1−ϵ)(w,v)∈E∑dwπw(t−1)−πw∗
则 E r r ( t ) = ∑ v ∣ π v ( t ) − π v ∗ ∣ ≤ ( 1 − ϵ ) ∑ w [ π w ( t − 1 ) − π w ∗ ] ≤ ( 1 − ϵ ) E r r ( t − 1 ) ≤ ( 1 − ϵ ) t E r r ( 0 ) Err(t)=\sum\limits_v|\pi_v^{(t)}-\pi_v^*|\le (1-\epsilon)\sum\limits_w [\pi_w^{(t-1)} - \pi_w^* ]\le(1-\epsilon)Err(t-1)\le(1-\epsilon)^tErr(0) Err(t)=v∑∣πv(t)−πv∗∣≤(1−ϵ)w∑[πw(t−1)−πw∗]≤(1−ϵ)Err(t−1)≤(1−ϵ)tErr(0)
当 0 < ϵ < 1 0<\epsilon <1 0<ϵ<1时,上述递推关系式具有收敛性
把第t轮递推式子依次带入t-1, t-2, …
得到 P R ⃗ l ⋅ T = α l P R ⃗ 0 ⋅ T P l + 1 − α n 1 ⃗ T ( α l − 1 ⋅ P l − 1 + ⋅ ⋅ ⋅ + α P + I ) \vec{PR}^{l \cdot T}=\alpha ^l\vec{PR}^{0\cdot T}P^l+\dfrac{1-\alpha}{n}\vec{1}^T(\alpha^{l-1}\cdot P^{l-1}+\cdot \cdot \cdot+\alpha P + I) PRl⋅T=αlPR0⋅TPl+n1−α1T(αl−1⋅Pl−1+⋅⋅⋅+αP+I)
可以看出当迭代轮数l比较大时, α l \alpha ^l αl会是一个小量,造成PR只剩下第二项
故 P R v ⃗ T = 1 − α n 1 ⃗ T ( α l − 1 ⋅ P l − 1 + ⋅ ⋅ ⋅ + α P + I ) \vec{PR_v}^T=\dfrac{1-\alpha}{n}\vec{1}^T(\alpha^{l-1}\cdot P^{l-1}+\cdot \cdot \cdot+\alpha P + I) PRvT=n1−α1T(αl−1⋅Pl−1+⋅⋅⋅+αP+I)
对于这个式子的含义学术界有很多解释
- R a n d o m − W a l k Random-Walk Random−Walk: 看作是以概率 α \alpha α留下, 1 − α 1-\alpha 1−α转移随机游走的概率值
- P R ( v ) PR(v) PR(v) = # walks ends at v n r \dfrac{v}{nr} nrv
- 看做是一个长时间随机游走的结果
- α − W a l k \alpha-Walk α−Walk: 与Random Walk一致, 看做是一个以概率 α \alpha α留下, 1 − α 1-\alpha 1−α转移随机游走过程,约定经过某个点,该点的 s c o r e ( w ) + = ( 1 − α ) score(w) +=(1-\alpha) score(w)+=(1−α)
- α − W a l k \alpha-Walk α−Walk相对于Random Walk,方差更小,复杂度很低,实际效果更好,是目前研究的热点方向
Next maybe Talk About PPR/SimRank or maybe Top-k PPR
好 一口气结束 hhh
Reference
- The PageRank Citation Ranking: Bringing Order to the Web
- Fast Distributed PageRank Computation
- PageRank and The Random Surfer Model
- bidirectional-random-walk, 大图的随机游走( 个性化 PageRank ) 算法