Python Crawler
Python Spider
Python 爬虫
# coding:utf8
__author__ = 'xgqfrms'
__editor__ = 'vscode'
__version__ = '1.0.1'
__copyright__ = """
Copyright (c) 2012-2050, xgqfrms; mailto:[email protected]
"""
# 导入整个模块
import logging
import url_manager
import html_downloader
import html_parser
import html_outputer
# import url_manager, html_downloader, html_parser, html_outputer
# 导入部分模块
# from spider import url_manager
# from spider import html_downloader
# from spider import html_parser
# from spider import html_outputer
# import group modules
# from spider import url_manager, html_downloader, html_parser, html_outputer
# from url_manager import UrlManager
# from html_downloader import HtmlDownloader
# from html_parserimport HtmlParser
# from html_outputer import HtmlOutputer
class SpiderMain(object):
# 构造函数 初始化
def __init__(self):
# urls 管理
self.urls = url_manager.UrlManager()
# html 下载
self.downloader = html_downloader.HtmlDownloader()
# html 解析
self.parser = html_parser.HtmlParser()
# html 输出结果
self.outputer = html_outputer.HtmlOutputer()
# function
def craw(self, root_url):
# 计数
count = 1
self.urls.add_new_url(root_url)
while self.urls.has_new_url():
try:
new_url = self.urls.get_new_url()
print 'craw %d:%s' %(count,new_url)
html_cont = self.downloader.download(new_url)
new_urls,new_data = self.parser.parse(new_url,html_cont)
self.urls.add_new_urls(new_urls)
self.outputer.collect_data(new_data)
print new_data['title']
#
if count == 10:
break
count = count + 1
# except Exception, e:
except Exception as e:
logging.exception(e)
print 'craw failed' + e
self.outputer.output_html()
print 'finished'
# main 程序的入口
if __name__ == '__main__':
# 实例化
obj_spider = SpiderMain()
root_url = 'http://baike.baidu.com/view/21087.htm'
# 启动 crawler
obj_spider.craw(root_url)
Pycham CE
bug
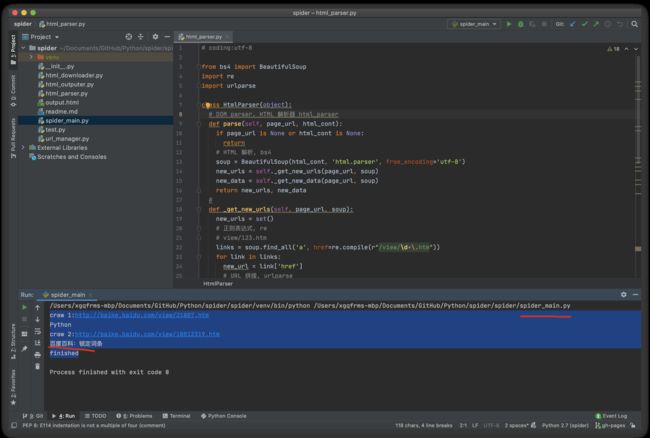
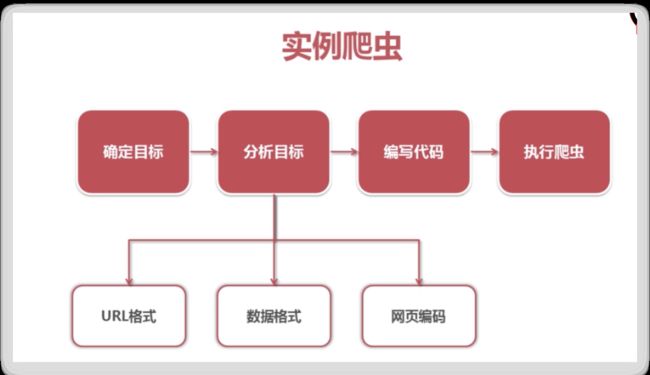
简单爬虫架构
爬虫调度端:启动爬虫
程序中三个模块:
- url管理器,管理还未爬取和已经爬取的 url 进行统一管理;
- url管理器将待爬取的url传送给网页下载器,进行下载,然后以字符串的形式传递给网页解析器进行解析;
- 解析出有价值的数据,然后解析出来的新的url又补充到url管理器,这样就形成了一个循环;
爬虫动态运行流程
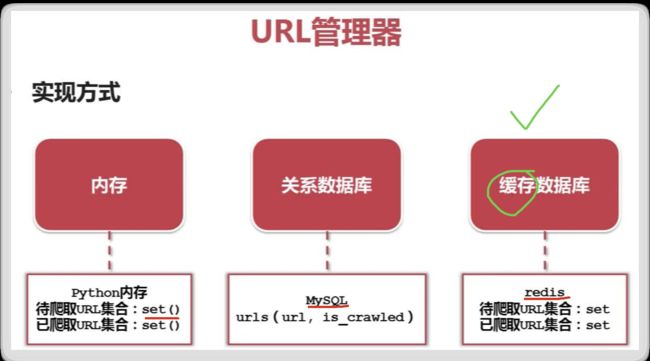
URL管理器
URL管理器 , 三种实现方式:
- 小型使用内存,set()可去除列表中重复的元素
- 永久存储使用关系数据库 MySQL
- 大型公司出于性能考虑,使用缓存数据库 Redis
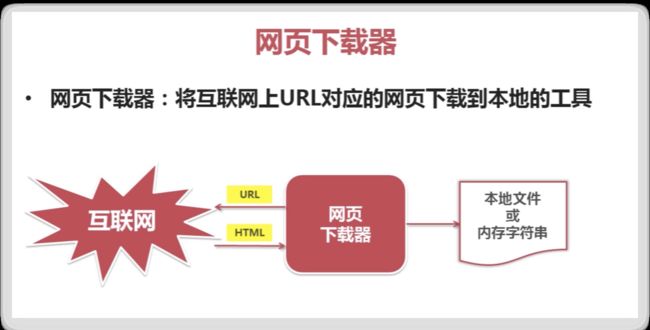
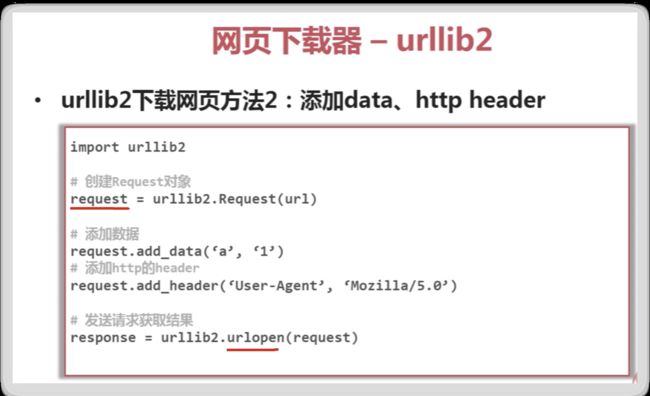
网页下载器
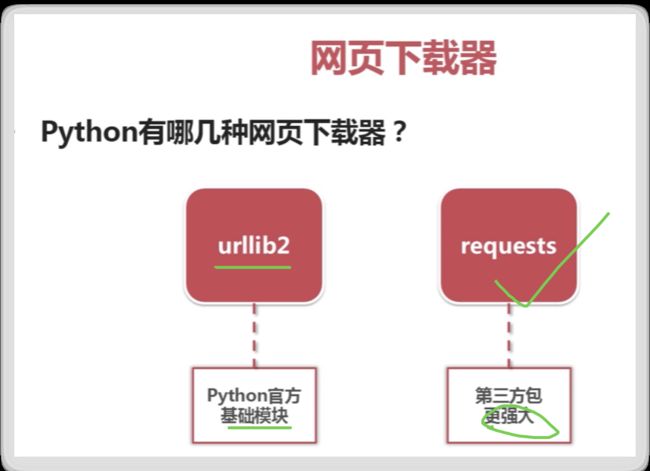
Python urllib与urllib2区别
https://www.cnblogs.com/yuxc/archive/2011/08/01/2124073.html
https://www.zhihu.com/question/27621722
# coding:utf8
import urllib2
import cookielib
url="http://www1.szu.edu.cn"
print "第一种方法"
response1=urllib2.urlopen(url)
print response1.getcode()
print len(response1.read())
print "第二种方法"
request=urllib2.Request(url)
request.add_header("user-agent", "Mozilla/5.0 ")
response2=urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
print "第三种方法"
cj=cookielib.CookieJar()
opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
urllib2.install_opener(opener)
response3=urllib2.urlopen(url)
print response3.getcode()
print cj
print response3.read()
HTTP request
HTTPS, Proxy
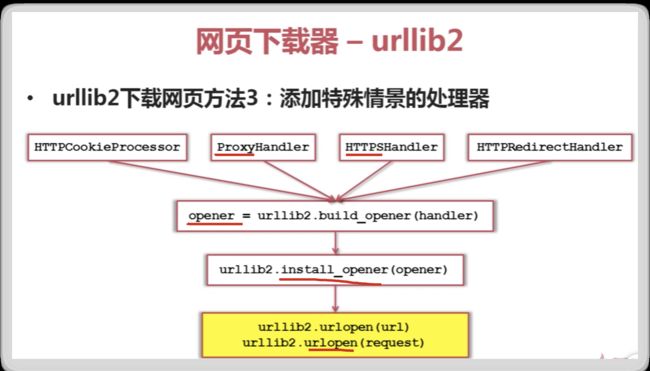
cookies

爬虫抓取策略
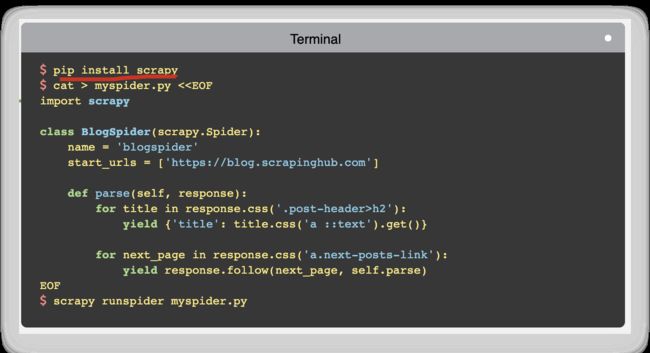
Scrapy
Scrapy 2.3.0
$ pip install scrapy
web spiders
An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.
一个开放源代码和协作框架,用于从网站提取所需的数据。 以一种快速,简单但可扩展的方式。
https://scrapy.org/
ref
https://gaocegege.com/Blog/spider/scrapy
refs
Python 我自成佛自度我,佛度凡尘我度佛。
https://www.cnblogs.com/xgqfrms/tag/Spider/
https://www.imooc.com/learn/563
Python语言程序设计
https://www.icourse163.org/course/BIT-268001
Python网络爬虫与信息提取
https://www.icourse163.org/course/BIT-1001870001
https://www.youtube.com/watch?v=ZMjhBB17KVY
https://python123.io/index/courses/3044
https://python123.io/index/opencourses
https://www.runoob.com/w3cnote/python-spider-intro.html
爬虫实战
https://www.imooc.com/video/10688/0

©xgqfrms 2012-2020
www.cnblogs.com 发布文章使用:只允许注册用户才可以访问!