MTCNN(Multi-task convolutional neural networks)人脸检测
理论基础:

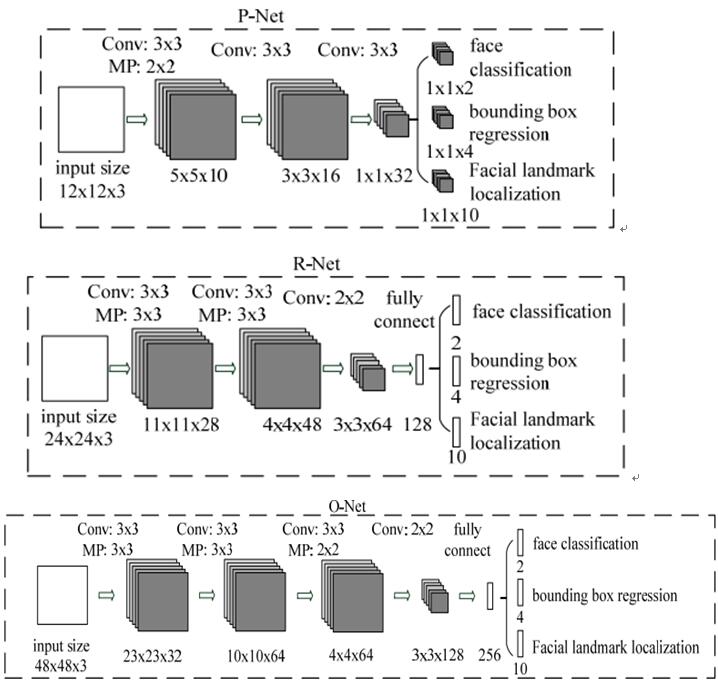
正如上图所示,该MTCNN由3个网络结构组成(P-Net,R-Net,O-Net)。
Proposal Network (P-Net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重叠的候选框。
Refine Network (R-Net):该网络结构还是通过边界框回归和NMS来去掉那些false-positive区域。
只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive的作用。
Output Network (O-Net):该层比R-Net层又多了一层卷基层,所以处理的结果会更加精细。作用和R-Net层作用一样。但是该层对人脸区域进行了更多的监督,同时还会输出5个地标(landmark)。
详细的网络结构如下图所示:
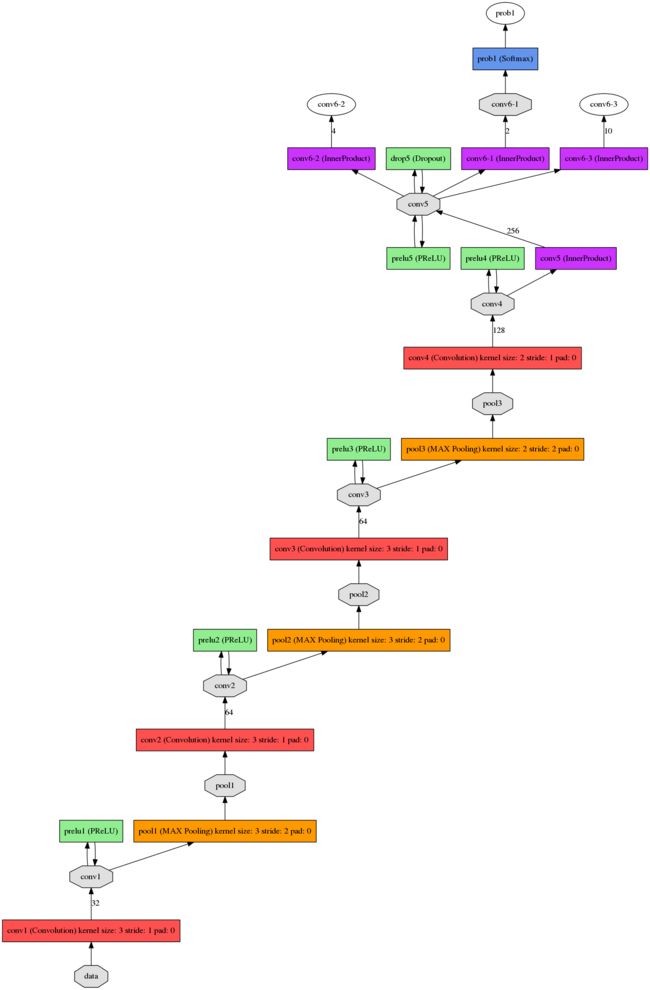
prototxt的更加详细的网络结构如下:分别为det1,det2,det3。
det1.prototxt结构:

det2.prototxt结构:

det3.prototxt结构:
训练:
MTCNN特征描述子主要包含3个部分,人脸/非人脸分类器,边界框回归,地标定位。
人脸分类:
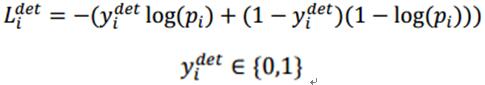
上式为人脸分类的交叉熵损失函数,其中,pi为是人脸的概率,yidet为背景的真实标签。
边界框回归:

上式为通过欧氏距离计算的回归损失。其中,带尖的y为通过网络预测得到,不带尖的y为实际的真实的背景坐标。其中,y为一个(左上角x,左上角y,长,宽)组成的四元组。
地标定位:

和边界回归一样,还是计算网络预测的地标位置和实际真实地标的欧式距离,并最小化该距离。其中,,带尖的y为通过网络预测得到,不带尖的y为实际的真实的地标坐标。由于一共5个点,每个点2个坐标,所以,y属于十元组。
多个输入源的训练:
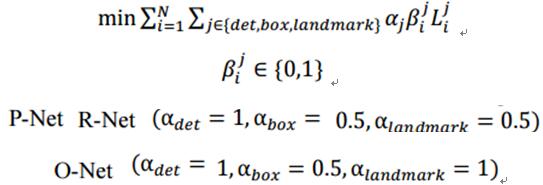
整个的训练学习过程就是最小化上面的这个函数,其中,N为训练样本数量,aj表示任务的重要性,bj为样本标签,Lj为上面的损失函数。
在训练过程中,为了取得更好的效果,作者每次只后向传播前70%样本的梯度,这样来保证传递的都是有效的数字。有点类似latent SVM,只是作者在实现上更加体现了深度学习的端到端。
---------------------
作者:watersink
来源:CSDN
原文:https://blog.csdn.net/qq_14845119/article/details/52680940
版权声明:本文为博主原创文章,转载请附上博文链接!
人脸检测——MTCNN,2014wzy
https://blog.csdn.net/u014696921/article/details/65446250
MTCNN工作原理.晴空1998
https://blog.csdn.net/qq_36782182/article/details/83624357
MTCNN学习笔记,qq_41732387
https://blog.csdn.net/qq_41732387/article/details/86044657
MTCNN解读,非文艺小燕儿_Vivien
https://blog.csdn.net/fuwenyan/article/details/73201680
MTCNN,watersink
https://blog.csdn.net/qq_14845119/article/details/52680940
MTCNN论文解析[未完],键盘里的青春
https://blog.csdn.net/qq_34374664/article/details/81915523
人脸关键点检测总结,Imcy
https://blog.csdn.net/u013948010/article/details/80520540
深度学习人脸关键点检测方法----综述,TensorSense
https://blog.csdn.net/u011995719/article/details/78890333