最前沿的12个NLP预训练模型
1 引言
17年transformer被提出,18年迎来了ELMo和BERT的横空出世,19年预训练模型不出意外地开始了全面的爆发。
所以,预训练模型也成为了NLPer绕不过去的一个技术栈,这篇文章将会梳理一下我学习过的12个预训练模型。这是一篇review性质的文章,跳过了一些基础的知识,可能会对一些没用过预训练模型的读者不大友好。
预训练模型,在我看来,相对传统模型做的革新,主要体现在以下三个方面:
(1)通用的特征提取器
早期NLP模型设计的一个重要步骤,就是考虑如何提取语料特征。这个环节会占用算法工程师大量的精力,也是影响模型效果的关键因素。
在预训练模型中,我们只需要简单粗暴地使用transformer,不需要太多地关注具体任务,就能够达到SOTA级的特征提取器的效果。
除此之外,transformer的设计思想由于其通用性,还可以拓展应用到其它领域,例如CV领域。
(2)动态化的词向量
在词向量方法刚出现的时候,例如NNLM,word2vec,Glove模型,他们针对每个特定字词所生成的词向量是一成不变的。对于存在一词多义现象的字词,这种静态的词向量很难在所有的场景下,都准确完整地表示出字词的信息。
所以,我们需要一种能够根据上下文语境进行动态调整,准确表示字词意思的词向量。预训练模型借助attention机制,就能够动态生成这种基于上下文的词向量。
(3)针对不同下游任务的强泛化性
传统的构建模型的思路,就是根据任务的具体类型,选择相应的模型。这样因地制宜、对症下药是没有问题的,但是我们要考虑到,在工业界工程落地,存在着各种各样的特殊情况和限制条件,比如说训练语料不足、算法工程师水平不够。
所以我们有时候需要一个“傻瓜式”的即插即用的模型,不需要太多的训练工作、不需要太多的调参工作、不需要太多的模型选型和优化工作。预训练模型就是这样一个强泛化性的模型,它只需要少量的训练数据和模型优化工作,就能够在新的下游任务中获得不错的效果,有时候甚至不需要训练和优化就能够直接拿来使用。
介绍完了预训练模型最显著的创新点,我们先对下文将要介绍的12个预训练模型做个一句话概览,先有个简单直观的印象:
(1)transformer是主流预训练模型的基本单元,是一个强大的特征提取器,后续的模型大多是基于transformer的优化和改进。
(2)ELMo基于传统的RNN模型框架,是一个双向模型。它会根据上下文语境,动态地生成词向量。
(3)BERT可以理解为集合了transformer优点(特征提取)和ELMo优点(双向)的模型,是最经典的预训练模型,是预训练模型的里程碑。
(4)transformer-XL将transformer作为基本单元应用于RNN模型,改善了transformer输入序列长度受限(长文本)的问题。
(5)XLNet是基于transformer-XL的模型,论文的主要创新点是双流机制和序列乱序方法。XLNet同时也使用了大量的语料,构建了更大的模型,也取得了比BERT更好的效果。但是通过大语料、大模型这种类似军备竞赛的方式刷新SOTA的方法,也逐渐开始泛滥。
(6)ERNIE是百度提出的模型,它基于BERT,百度利用其强大的语料库优势进行训练,把ERNIE推到了中文NLP任务SOTA的地位,并保持了很长一段时间。
(7)ERNIE2.0在ERNIE的基础上,使用多任务学习的方法,进一步提升了模型的泛化性和通用性。
(8)GPT是一个早期模型,可以理解为将RNN的基本单元替换为transformer,是一个单向模型。
(9)GPT-2也是一个使用大语料训练的大模型,它在文本生成任务上的表现让人惊艳了一把,也因为不肯开源被学术界工业界口诛笔伐(现在已经开源了)。
(10)RoBERTa在BERT的基础上,致力于将调参发挥到极致。
(11)ALBERT使用词向量因式分解和层间参数共享两个方法,在降低模型规模方向上,做了显著有效的尝试。
(12)TinyBERT利用知识蒸馏技术降低模型规模,也获得了很好的效果。
2 Transformer
预训练模型始于transformer,兴于BERT。
模型典型结构
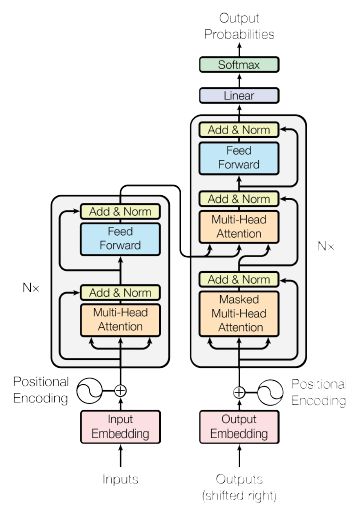
图2.1transformer架构
transformer的架构如图2.1所示,和传统的seq2seq模型一样,它由encoder和decoder构成。在这里,我们只需要重点关注encoder,因为后续大多数模型使用的是encoder的结构,而不是decoder的。
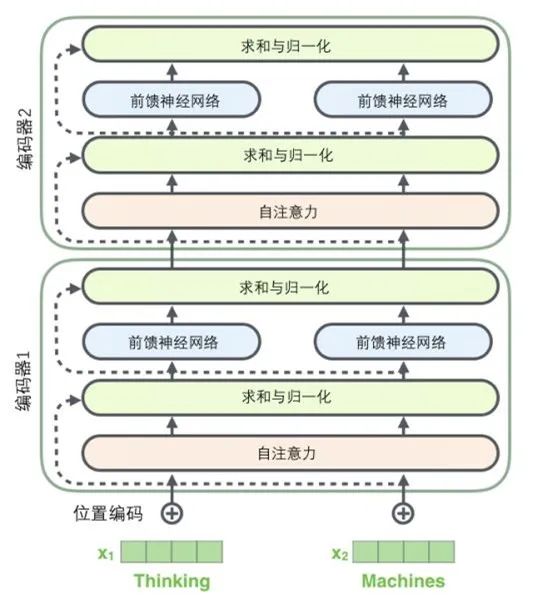
图2.2transformer单元
transformerencoder是一个多层模型,图2.2呈现的是transformer encoder的一层,我们将它称之为transformer单元。这也是我们学习transformer论文时要重点关注的内容。后续有些论文提及的“transformer”大部分指的是transformer单元,而不是整个transformer模型。transformer单元在示意图中常常被缩写成TRM。
模型层结构:
(1)transformer的encoder由6层transformer单元组成。
(2)每层transformer单元包含8个头(header),每个herder输出的向量的维度是64,所以每个字词token通过模型输出的向量的维度是512(64*8)。
(3)query/key/value的维度和单个header输出的维度一致,均为64。
(4)每个transformer单元包含2个相同的子层,每个子层包含多头自注意力层(self-attention sublayer)和全连接前馈神经网络层(FFN)。
模型创新点
(1)传统的NLP模型大多是基于RNN序列模型结构的,这个结构会导致数据处理时延过长,影响模型的线上性能。transformer采用了类似CNN的结构,能够同时并行处理整个序列的所有token,极大地改善了模型的效率。
(2)模型使用了多头自注意力机制:(a)多头:多头结构类似于CNN的多channel机制,是提高泛化性和健壮性的一个机制;(b)自注意力:自注意力机制和传统注意力机制的思路基本一致,让字词token输出的向量都和前一层的上下文相关联,也就是让上下文也参与到词向量的构建过程中,从而解决了一词多义的问题。
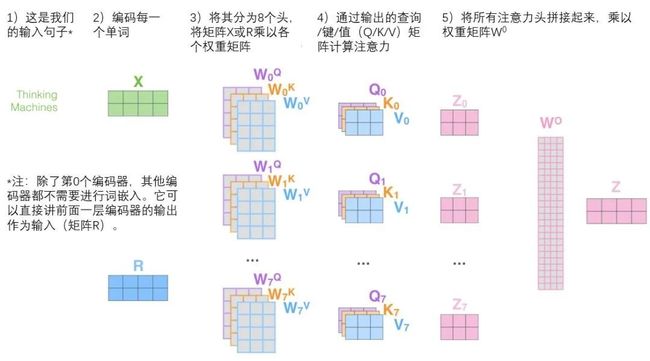
图2.3 多头机制
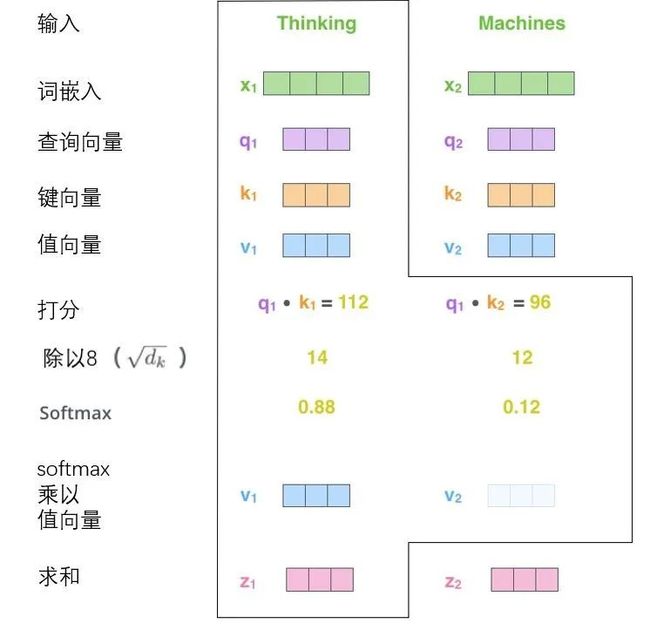
图2.4 自注意力机制
注:论文认为,在self-attention的过程中,每个token只能看到前文的信息,不能看到后文的信息。所以transformer使用了sequence mask,在self-attention时将后文的所有token给屏蔽了。因此,transformer是一个单向的模型。
(3)使用了基于欧拉公式的位置嵌入机制。让模型更容易捕捉到位置信息。在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
![]()
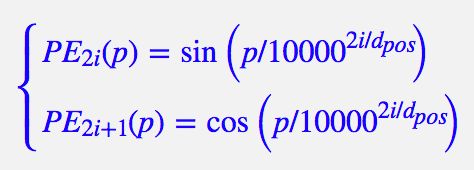
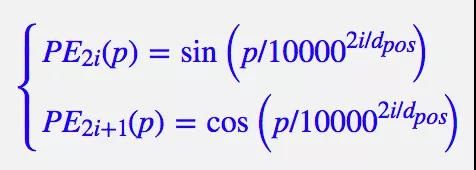
图2.5 位置嵌入信息
模型其它特性
(1)使用了残差网络。
(2)使用了层归一化。
3 ELMo
ELMo是一个继承传统NLP模型架构的新模型,依旧是一个RNN体系下的模型,模型能够根据上下文语境,动态地生成词向量。
模型典型结构
(1)模型使用了多层RNN结构,每层都使用的都是标准的Bi-LSTM,上一层的输出作为下一层相同单元的输入。
(2)在下游任务需要用到特定层的输出时,模型将抽取目标层的两个单向LSTM网络输出的向量concat后交给下游任务。
(3)在应用到特定任务时,ELMo可以添加到原始任务模型的input端(将token输入ELMo,输出词向量后再输入原始任务模型),也可以添加到output端。

图3.1 ELMo模型
模型创新点
(1)模型在词向量embedding的过程中引入了上下文特征,同一个词会根据不同的上下文语境,通过注意力机制,动态地改变其生成的词向量,这改善了传统的静态词向量的一词多义的问题。
(2)ELMo是一个双向网络,使用Bi-LSTM结构,能够获取上文和下文的信息。
模型各层输出词向量的特性
(1)模型各层的输出,抽取的特征有不同的侧重点,有的侧重语义信息,有的侧重语法信息。
(2)论文建议使用各层输出向量的加权和作为模型的最终输出向量。各层的权重值,是一个非常重要的参数,它根据下游任务的需要,有侧重点地挑选不同层所抽取出的特性信息,并进行合并,最终传递给特定的下游任务中。
(3)高层的Bi-LSTM输出,能够更多地捕捉到语义信息(以及上下文信息)。
(4)低层的Bi-LSTM输出,能够更多地捕捉到语法信息。
模型其它特性
(1)ELMo模型的局限性:Bi-LSTM是一个不完全的双向网络。因为每次只训练单向的网络,然后把两个单向网络的输出concat起来,而不是同时训练双向网络。所以ELMo模型输出的向量,是将前向/后向网络学习到的向量concat的结果,而不是同时学到上文和下文的信息,属于浅层的双向网络。
(2)在应用到特定任务时,ELMo可以添加到原始任务模型的input端(将token输入ELMo,输出词向量后再输入原始任务模型),也可以添加到output端。
(3)模型使用了dropout方法。
(4)模型使用了L2正则项。较小的λ会让各层的权重,有更大的波动。ELMo模型倾向使用较小的λ。
4 BERT
BERT不是第一个预训练模型,BERT也不是效果做好的预训练模型,但是它是一个里程碑,标识着NLP进入预训练模型时代。
模型典型结构
(1)BERT可以理解为transformer和ELMo的结合体。
(2)使用了transformer的特征提取机制。
(3)引入了ELMo的双向机制。
模型创新点
transformer和BERT的论文作者是同一个团队,在BERT论文里,作者更侧重于论述如何训练BERT模型,以及如何让BERT模型去适配下游任务。
(1)将transformer的mask机制由只mask下文改进为mask上下文的随机token,也就将单向网络改进为双向网络。
(2)提出了两种预训练任务:masked language model(masked LM),NSP(next sentence predict)。
(3)给出了应用于不同下游任务的语料改造建议。
masked LM任务及其局限性
(1)模型随机挑选输入序列15%的token进行mask。模型的任务就是预测这些被mask的token。
(2)局限性一:由于在预测阶段,模型包含[MASK]这种token,但是在预测阶段不会出现[MASK]这种token,这导致了训练阶段和预测阶段的MASK不一致性。
(3)局限性二:在训练阶段,模型对上下文所有语料进行随机mask。在文本生成这类特定任务里,模型只看得到上文,而看不到下文,这也导致了训练阶段和预测阶段的单双向模型不一致性。
NSP任务
(1)输入语料时两个句子的concat,NSP的目标是预测第一句文本在原文中的下一句,是否是语料中的第二句。
(2)[cls]对应位置的输出向量,用于表示预测结果的label。
(3)NSP任务在后续的很多论文中都被证明效果不佳,具体内容在相应的论文里再进行进一步描述。
模型输入参数的构建
inputrepresentation的构成(相加):Token Embd(原始词向量),Segment Embd(不同句子的分段标注信息),Position Embd(位置信息)
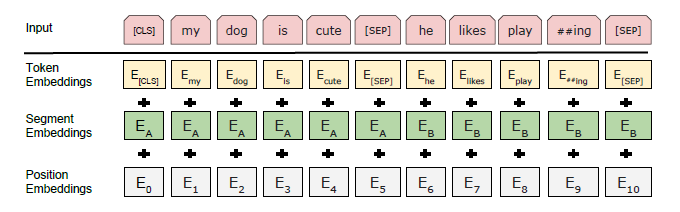
图4.1 模型输入参数的构建
针对不同下游任务的语料改造
针对不同的下游任务,网络上的大牛们给出了直观的改造示意图,如图4.1和4.2所示。
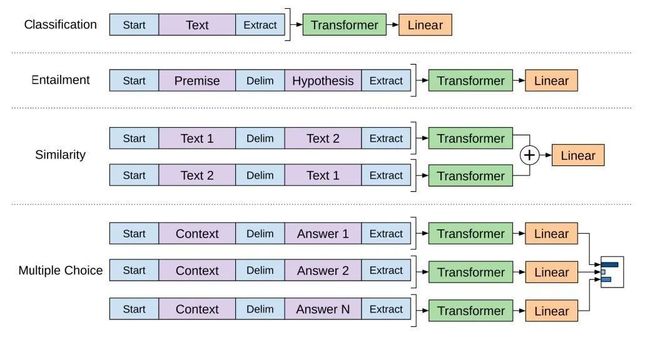
图4.2 下游任务改造1

图4.3 下游任务改造2
对于下游任务,需要说明2点:
(1)BERT在自然语言生成任务上效果不佳,估计和训练-预测阶段模型的差异性有关。
(2)对于很多任务,即使不经过fine-tune,模型也是能用的,所以BERT模型具有极强的泛化性!
5 Transformer-XL
Transformer单元是一个类似CNN的结构,那么也就有着类似“感受野”的属性。在Transformer模型函数里,有一个“最大序列长度”的配置,默认配置成512,也就是说此时模型只能接受长度不长于512的输入序列。所以,输入transformer模型的序列的长度是受到限制的。
为了改善transformer在长文本任务中表现不佳的情况,transformer-XL模型就被提出来了。
模型结构和创新点
(1)transformer-XL以RNN网络为基础架构。
(2)transformer-XL以transformer为基本单元(segment)。
(3)使用了新的attention机制,以解决不同单元(segment)之间的信息传递的问题。
(4)使用了相对位置编码机制,以解决不同单元(segment)之间的绝对位置编码的混淆问题。
新的attention机制
(1)传统transformer的token接受下一层的token(传统transformer只有一个segment)的输出作为attention机制的入参。
(2)Transformer-XL模型的token接受的输入,不仅仅是同一个segment中的前一层的输出,还包含前一个segment的前一层的输出(还可以对模型进行修改,使用更早sengment的输出)。
(3)Query使用的是本segment的目标token的输出,Key和Value使用的是前sengment的输出和本segment的输出。
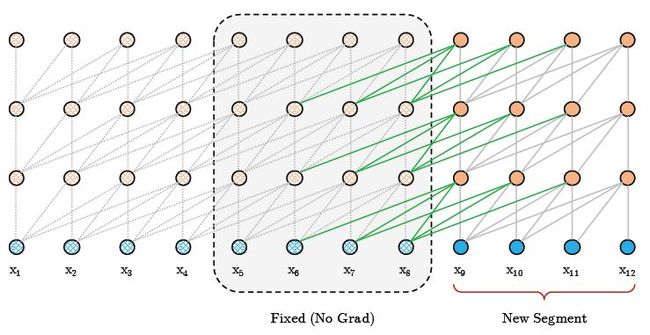
图5.1 segment间信息传递示意图
相对位置编码
使用相对位置编码,而不是绝对位置编码。是为了和跨segment的attention机制相配合,否则会引起位置上的混乱。
基于相对位置编码的attention机制的分数计算

图5.2 基于相对位置编码的attention机制的分数计算
其中:
(1)R(i-j)表示一个相对位置编码。
(2)u和v是需要训练得到的向量。由于在相对位置的坐标系中,q的位置可以理解为一个初始位置,所以u和v在所有的attention中都是一样的。
(3)c项和d项的W(k)是不一样的,一个和上下文语义相关,一个和位置信息相关。
完整的单层Transformer-XL信息流

模型其它特性
(1)Transformer-XL能够捕捉的最长距离,等于N*L(sengment最大长度N,Transformer的层数L)。
(2)不同于传统RNN模型的只使用最后时刻输出的向量,Transformer使用了整个序列时刻的输出。
6 XLNet
类似于transformer和BERT的一脉相承,transformer-XL和XLNet的作者也是同一个团队。
作为第一个跟进BERT的预训练模型,XLNet当年还是火过一阵的,它在长文本和NLG任务上有着良好的表现。
模型典型结构
XLNet继承了transformer-XL的结构特性:
(1)以transformer-XL为基本单元(segment)的RNN网络;
(2)使用相对位置编码,这个结构尤其适用于长文本序列场景。
模型创新点
XLNet的创新点有两个:
(1)双流机制
(2)序列乱序方法
双流机制
(1)模型将语句包含的信息,分为语义(上下文)信息和位置信息两个方面。
(2)在预测目标token的时候,传统的语言模型是仅仅使用了上文的语义信息和位置信息,XLNet除此之外还使用了目标token的位置信息。
(3)通过双流机制来实现(见图6.1):(a)内容流h:包含上文序列所有token的语义信息和位置信息;(b)查询流g:包含上文序列所有token的语义信息和位置信息,还包含当前token的位置信息。
(4)第一层的g是一个可训练的向量w,第一层的h是embedding词向量。
(5)双流的Q/K/V矩阵是同一组。
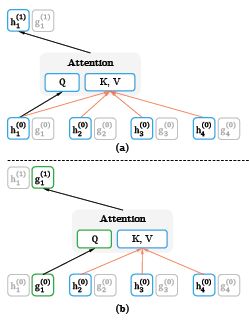
图6.1 双流机制(a)内容流attention(b)查询流attention
序列乱序方法
(1)计算语言模型的条件概率时,先对输入语句进行乱序排列,再计算单向序列的条件概率分布。由于乱序后的目标token,可能会学到上文和下文随机token的信息(下文乱序后可能成为上文),所以XLNet形式上是单向网络,实际上是双向网络。
(2)对于长度为T的序列,乱序后全排列共有T!种情形。
(3)由于文本序列的向量,编码进了位置信息,所以乱序后模型依旧知道token的次序。
(4)为了提高运算速度和减少内存消耗,模型仅通过序列的前c个token预测后续的token。序列长度和待预测token的长度的比值K是一个超参数,需要配置。之所以选择通过前序的词,预测后续的词,是因为后续的词在条件概率语言模型中,能够包含更多的信息。
(5)当前segment在使用到前序segment的信息时,虽然前序的segment是乱序的,但是由于其token包含位置信息,所以前序segment的次序会被纠正为正常序列。
模型其它特性
(1)弃用了[MASK],缓解了pre-train和fine-tine之间不匹配的现象。
在BERT模型中,被MASK的待预测token,不会使用到其它被MASK的token的信息,因为其他token被替换成了[MASK]。
但是在XLNet模型中,待预测的token可能会使用到任意token的信息,所有乱序后的位置位于待预测token前面的token信息都将被完整地用到。同时由于文本序列有被多次乱序后,所以待预测token可能会学习到所有上下文的信息。
(2)XLNet认为NSP没有效果,所以没有采用NSP进行pre-train。
(3)BERT使用segment encoding来标注拼接到一个输入序列里的两个分句。XLNet做了改进,使用s+和s-来表示两个位置的token是否属于同一个segment。s+和s-是可训练向量。所以:(1)XLNet不关注目标token是来源于哪个分句,只关注两个token是否来源于同一个分句。这提升了模型的泛化能力。(2)模型因此能够适用于多个(多于2个)分句的场景。
(4)使用了span-predict的pre-train方法。
(5)在pre-train过程中,使用了正序和倒序(bidirectional data input pipeline)输入数据的技巧。
7 ERNIE
ERNIE是百度提出的基于BERT的预训练模型。作为掌握着最多中文语料的互联网公司,百度毫无疑问在训练语料上有着先发优势,ERNIE的确也在很长一段时间内占据着中文NLP的SOTA地位。
模型特点和创新点
ERNIE的优势来源于两个方面:
(1)输入语料包含了知识特征,让模型能够更好地学习到知识。
(2)使用了大量的异构的无监督语料。包括中文维基百科、百度百科、百度新闻、百度贴吧的语料。
除此之外,ERNIE使用对话语言模型(DLM ,Dialogue Language Model)作为预训练任务。
知识的学习
(1)通过知识掩码策略来学习知识,包括短语mask和专名mask。BERT在mask过程中,是以token为粒度随机mask的,ERNIE是以短语或专名为粒度。
(2)通过一个三阶段的策略对模型进行训练:第一阶段使用标准mask(15%的token被mask)。在这个阶段里,高级的语义知识很难被学习到;第二阶段使用短语mask;第三阶段使用专名mask。
DLM预训练任务
模型使用DLM (Dialogue Language Model)任务进行预训练:
(1)BERT输入序列的每个token,其向量由三个部分组成:token embd,位置embd,segment embd。ERNIE将segment embd替换为dialogue embd。
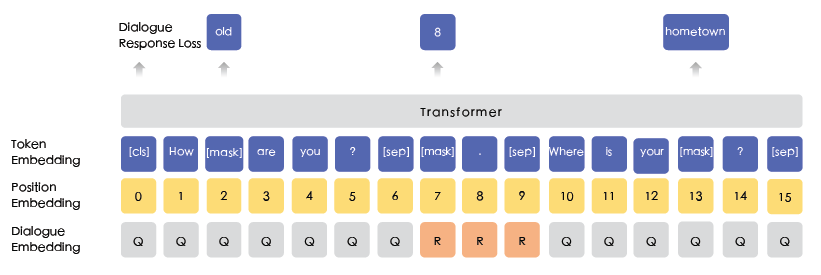
图7.1 DLM输入数据构建
(2)通过将Q或R替换成一个随机的句子,来构建负样本。
(3)这个思路还可以用于多轮对话。
模型其它特性
(1)进行了完形填空任务的对比实验,在一些对比示例里,模型发现BERT倾向于拷贝上下文里的词,而ERNIE模型学习到了知识,则会根据知识和上下文来填空。
(2)模型对中文语料做了繁简转换的预处理,对英文语料做了大写转小写的预处理。
(3)模型使用了17964个单词的词表。
8 ERNIE2.0
ERNIE的一大特点是使用了异构的无监督语料,提高了模型的泛化性。ERNIE2.0使用多任务进行预训练,在提高泛化性的路上又往前走了一步。
模型创新点
ERNIE2.0论文的贡献主要在两个方面:
(1)提出了序列多任务学习的预训练任务机制。
(2)定制和引入了多种预训练任务。
序列多任务学习
(1)通过序列多任务学习,模型能够学习到词汇、语法、语义信息。
(2)序列多任务学习需要解决的两个问题:(a)如何在不忘记之前学到的知识的前提下,进行持续训练(这是continual learning存在的问题)。(b)如何以一个高效的方式进行训练。
(3)序列多任务学习包含两个阶段:(a)不断的利用大量的、包含先验知识的语料,构建无监督预训练任务;(b)利用序列多任务学习方法,不断地更新模型。
(4)序列多任务学习结构,和多任务学习、持续学习结构的对比:
![]()
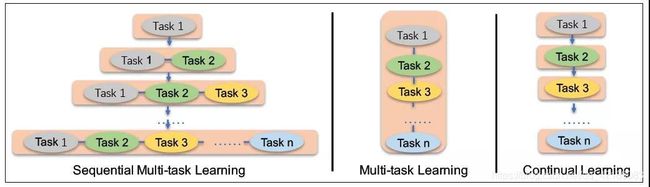
图8.1 序列化多任务学习/多任务学习/持续学习
(5)不同于持续学习和多任务学习,序列多任务学习在引入新的训练任务时,先利用之前学习到的参数对模型进行初始化,再同时训练新任务和旧任务。
(6)模型通过将所有的任务按需分配给不同的迭代轮次,达到高效训练的目的(文章没有提及分配的标准和方法)。
(7)序列多任务学习的模型里,有两个损失函数。一个是句子级别的损失函数,一个是token级别的损失函数。
论文中定制的三大类预训练任务
(1)侧重词汇的任务,能够让模型学习到词语信息,包括:知识mask任务,大写字词预测任务,字词-文章关系的预测任务。
(2)侧重结构的任务,能够让模型学习到语法信息,包括:语句重排序任务(通过一个n!分类的模型),语句距离任务。
(3)侧重语义的任务,能够让模型学习到语义信息,包括:文章关系任务,信息检索相关性任务。
(4)这些任务都是基于无监督或者弱监督的,因此这些语料数量巨大且不需要人为标注。
(5)模型的输入向量,除了token embd、位置embd、segment embd(sentence embd),还有task embd。
模型其它特性
(1)在pre-train阶段使用序列多任务学习方法,在fine-tune阶段根据特定任务进行微调。
(2)区分大小写字词的模型适用于NER任务,不区分大小写的模型适用于其它任务。
(3)字词-文章关系的预测任务里,如果一个字词在一篇文章里多次出现,那么这个字词常常与这篇文章的主题相关。
(4)句子顺序任务和相邻句任务,能够让模型学习到结构化的信息。文章级别的语义相似度任务和句子间的论述关系任务,能够让模型学习到语义信息。
9 GPT
GTP是一个很早期的模型,在transformer之后,在BERT、XLNet、ERNIE之前。
模型典型结构
(1)GPT使用transformer的decoder作为模型的基本单元,是一个单向模型,可以理解为单向版本的BERT。
(2)GPT使用语言模型的条件概率作为辅助目标函数(auxiliary objective)。并且发现在大语料场景下,模型效果得到改善,但是小语料场景下效果有限。
因为这两个特性,GPT很适合NLG任务。
针对不同下游任务的改造
和BERT类似,GPT针对不同类型的下游任务,需要对输入序列进行改造:
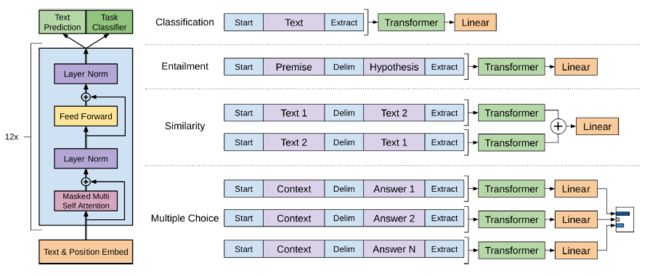
图9.1 GPT针对不同下游任务的改造
模型其它特性
(1)在ablation study中,尝试不进行pre-train,直接在特定任务上fine-tune,发现效果很差。
(2)使用了7000多本书的语料进行训练。
10 GPT-2
GPT-2就是那个因为声称“危险到不能公布”拒绝开源,从而被业界学术界推上风口浪尖的模型。他的成名作就是那个“独角兽的故事”。

图10.1 GPT-2写的关于独角兽的故事
模型特征
GPT-2的模型架构和GPT基本一致,但是却“大”了很多:
(1)使用了大语料。
(2)使用了大模型。
“大”语料
(1)使用了大量的、多领域、高质量的训练语料,例如爬虫得到的网页文本。
(2)在使用爬虫获取网页文本时,特别关注了语料的质量。
(3)使用了网页内容提取器:Dragnet,Newspaper。
(4)在大语料场景下,byte-level语言模型的效果不如word-level语言模型的效果。
“大”模型
(1)扩展最大序列长度,从512到1024个token。
(2)使用大batch:512。
(3)扩展词表大小到50257个。
模型的通用性和泛化性
论文还特别强调了预训练模型的通用性和泛化性:
(1)多任务学习是提高模型框架通用性的一种可靠方法。
(2)使用大量且多样的语料进行pre-train后,能够直接用于(zero-shot)多个不同领域的下游任务。
模型其它特性
(1)使用了Byte-Pair Encoding (BPE)方法。使用BPE方法使得模型不会受到预处理、分词、词表大小等方面的限制。
(2)层归一化被移到了每个sub-block的输入处。
(3)残差网络在入口处,先使用了激活函数。
(4)在最后一个自注意力模块后加一个层归一化。
(5)根据残差网络路劲的模型深度的累积和,定义残差网络的初始值:乘以1/sqrt(N),其中N是残差网络的层数。
11 RoBERTa
我们经常自称为“调参工程师”,但是自嘲归自嘲,实际上调参试错的确是我们工作中不可缺少的一个环节。
模型技巧和经验
论文没有太多很惊艳的创新点,但是它的调参技巧却是我们能够学习和借鉴的:
(1)使用全新的、更多的、多样性的语料。
(2)训练更长的时间。
(3)使用更大的batch:使用大batch能够提高收敛速度和下游任务表现。
(4)弃用NSP。
(5)利用更长的句子进行训练:在训练周期的前90%,只使用达到最大长度的语料进行训练。
(6)在训练的过程中,动态改变mask的位置(BERT模型中,所有epoch的输入语料的mask都是相同的。RoBERTa中每个epoch的输入语料的mask都是不同的)。
(7)使用Byte-Pair Encoding (BPE)方法。BPE是一种介于char-level和word-level的方法,属于subword方法的一种,即能够缓解word-level的未登录词的问题,又能够改善char-level的词表达效果不佳的问题。
(8)论文强调了,BERT对语言模型的mask思路,在当前公开的训练目标函数方法中,是最有效地一个。
12 ALBERT
在BERT之后出现的一些预训练模型,都以BERT作为baseline,并且声称模型效果超越了BERT。但是我们必须注意到,大部分这些模型的规模,都是超过BERT的。
这种类似军备竞赛的研究方法,在工业界的意义是不大的,因为即使模型的效果再好,也无法部署上线,只能跑跑离线任务。
所以,这份笔记的最后两篇论文,都是和简化模型工作有关的。这节我们先介绍ALBERT模型。
模型创新点
(1)两个提高模型参数效率的方法:词嵌入向量的因式分解,层间参数共享。
(2)SOP (Sentence-Order Prediction)预训练任务。
模型参数效率提升
在工业界,我们在部署预训练模型时,会遇到以下三个难点:
(1)内存不足。
(2)在分布式场景,训练速度无法提高,原因传输大量的参数需要很大的通信带宽。
(3)模型规模增加后,反而引起效果的下降(泛化性不足)。
为了提高模型参数的效率,ALBERT基于BERT模型基础框架,提出了两个方法:
(1)词嵌入向量的因式分解。
(2)层间参数共享。
此外,参数的减少,可以视为一种正则化方法,能够提升模型的效果。
词嵌入向量的因式分解
(1)传统的BERT模型,词向量的维度和模型隐藏层的维度是一致的。
(2)由于词向量没有包含上下文信息,而模型隐藏状态向量有包含上下文信息,所以隐藏状态向量应该比词向量包含更多的信息。因此,将两者的维度绑定到一起是不合理的,隐藏状态向量的维度应该远大于词向量的维度。
(3)所以将词向量维度降维成E,隐藏状态维度H保持不变,同时训练一个E*H转换矩阵。在词向量和隐藏状态向量交互时,先将词向量乘以转换矩阵升维到隐藏状态的维度。
(4)因式分解后,模型需维护一个V*E(词表大小V*词向量维度E)的矩阵,和一个E*H(词向量维度E*隐藏状态维度H)的矩阵。
层间参数共享
传统的BERT有12层,每层有FFN和attention两个子层,模型训练好后,它们的参数是不一样的。在“层间参数共享”方法里,部分层(子层)的参数可以是共享的,这样就节约了存储参数的空间。
经过炼丹实践,得出以下经验:
(1)共享FFN层的参数,会导致模型效果下降。
(2)共享attention层的参数,模型效果不会下降(词向量维度E=128时)或者轻微下降(词向量维度E=768时)。
(3)我们可以将L层模型分为N组,每组包含M层,进行组内参数的共享。
NSP任务和SOP任务
除此之外,BERT的NSP方法也经常被一些论文所诟病,ALBERT对NSP效果不佳的原因做了分析,并提出了一个新的训练任务Sentence-Order Prediction (SOP)自监督方法:
(1)NSP的设计思路实际上是将主题预测和连贯性预测这两个任务混杂在同一个任务里。主题预测任务比连贯性预测任务更容易学习训练,并且在MASK语言模型的训练过程中已经学到了不少主题预测的信息。
(2)在NSP任务中,负例为选自不同文档的句子concat,这种负例构建方法即不利于主题预测任务,又不利于连贯性预测任务。
(3)句间连贯性对于NLU是很重要的,所以我们提出了SOP自监督方法,SOP方法的关注点是句子间的连贯性(inter-sentence coherence)
(4)模型利用句子顺序损失函数去优化模型,这避免模型引入主题预测任务的干扰,而只专注于连贯性预测任务。
(5)在SOP方法中,我们判定两个顺序不是原文顺序的句子caocat为负例。
13 TinyBERT
近年来,模型蒸馏也是一个很热门的领域,TinyBERT就是一个很有名的将模型蒸馏方法应用于transformer上的模型。
模型创新点
(1)TinyBERT模型提出了一个用于transformer模型的知识蒸馏方法。
(2)TinyBERT模型提出了一个两阶段的学习框架:通用知识蒸馏阶段,基于特定任务的蒸馏阶段。
基于transformer的知识蒸馏方法
(1)在两个方面对模型进行了简化:层数,向量维度。
(2)设计了三种损失函数:embd层的输出,每个transform层的隐藏状态和注意力矩阵,最后一层的logits输出。
(3)BERT学习到的注意力权重包含了潜在的语言信息,在从教师网络BERT到学生网络TinyBERT的转换中,语义信息也被传递了。
(4)
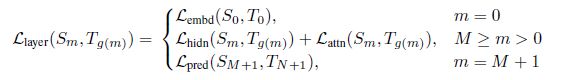
其中m=0表示表示embd层,m=M+1表示输出层。
(5)
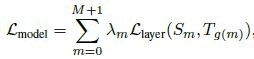
其中λ是一个人为定义的超参数,表示对应蒸馏层的重要程度。在实验中,λ取值为1的时候模型的效果最好。
(6)

在TinyBERT模型的注意力矩阵的损失函数中,注意力矩阵是没有做归一化的,因为实验表明不做归一化能够让模型收敛更快且表现更好。
(7)
![]()
![]()
对于两个模型维度不同的向量,在求损失函数时,要将学生模型的向量乘上一个可训练的矩阵,让它的向量维度和教师模型一致。
(8)
![]()
在输出层,采用交叉熵作为损失函数。其中t是温度参数,在本实验中,t取值为1时效果最好。
(9)不同的下游任务,重点使用模型的不同层的输出向量的信息。
两阶段的蒸馏框架
(1)在通用知识蒸馏阶段,缩减层数和维度,会导致模型效果的下降。
(2)模型在fine-tune蒸馏阶段使用了数据增强。
数据增强
论文还提出了一个数据增强方法:
(1)先mask文本中的一个字词,使用语言模型BERT预测出这个位置最有可能的M个字词,作为候选集。
(2)使用一个门限p去决定,是否将这个被mask的字词随机替换为备选集中的一个字词。如果词语由多个字组成,那么使用GloVe的固定词向量进行替换,而不使用BERT模型输出的候选集中的字词。
(3)对文本中的每个词,重复地执行以上步骤,这样能得到一个新的文本。
论文提及的其它一些Tips
(1)简化模型的主流技术有:量化、权重剪枝、知识蒸馏。
(2)有的知识蒸馏实例,会利用教师模型的参数对学生模型进行初始化。
14 总结
先上一张网络上大佬做的预训练模型的关系图,看署名是清华的大佬做的。
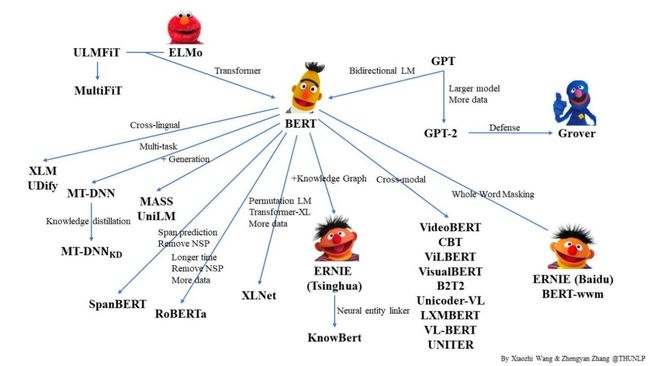
图14.1 预训练模型家谱
自从18年BERT问世后,19年各种预训练模型就层出不穷,新论文发表的速度,甚至都快于我们看论文的速度。
所以,如何去学习了解新的预训练模型,我在这里讲下我的心得体会,从理论和实践两方面来讲。
理论方面,transformer/BERT/ELMo这三篇论文建议仔细看完,这三篇论文算是预训练模型的基础入门文章。精读完这三篇,后续阅读新的预训练模型论文时,只要关注模型的改进点就可以了,一般3~4小时就能看完一篇新论文。另外transformer-XL和XLNet两篇论文的技巧思路也很棒,也建议看看。
实践方面,如果是自学的话,肯定会遇到一些内容文章里没讲明白直接跳过了,我们就会很疑惑这个模块到底是怎么实现的。那么这时候看源代码就很重要了,网络上很多讲解文章,都是重理论轻实践,在创新点理论方面分析得很到位透彻,对于原论文一笔带过的实现细节却不甚了解。所以无论如何,大家在看了论文之后,还是要找个模型的源码去研究下的。虽然我们不造轮子,但是我们要知道轮子是怎么造的。虽然去了解轮子是怎么造的,不会提高我们的绩效,也需要我们在加班之余挤出一些些宝贵的时间,但是九层之台,起于累土,打好基础还是很重要的。
最后吐个槽,现在很多论文里模型的优质效果都是大语料堆出来的,所以我一直觉得搞AI,语料数据就等同于钱,你要是钱多了,模型想怎么搞怎么搞,结果都差不到哪去。这个在学术界,就是有些论文的结果是靠语料提高的,实际上模型在改进创新方面没什么贡献。在工业界,很多团队都把重点放在模型本身上,而不注重语料数据的获取和清洗。
15 参考资料
[1] Vaswani A,Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neuralinformation processing systems. 2017: 5998-6008.
[2] Peters M E,Neumann M, Iyyer M, et al. Deep contextualized word representations[J]. arXivpreprint arXiv:1802.05365, 2018.
[3] Devlin J,Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformersfor language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[4] Dai Z, YangZ, Yang Y, et al. Transformer-xl: Attentive language models beyond afixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
[5] Yang Z, DaiZ, Yang Y, et al. XLNet: Generalized Autoregressive Pretraining for LanguageUnderstanding[J]. arXiv preprint arXiv:1906.08237, 2019.
[6] Sun Y, WangS, Li Y, et al. ERNIE: Enhanced Representation through KnowledgeIntegration[J]. arXiv preprint arXiv:1904.09223, 2019.
[7] Sun Y, WangS, Li Y, et al. Ernie 2.0: A continual pre-training framework for languageunderstanding[J]. arXiv preprint arXiv:1907.12412, 2019.
[8] Radford A,Narasimhan K, Salimans T, et al. Improving language understanding by generativepre-training[J]. URL https://s3-us-west-2. amazonaws.com/openai-assets/researchcovers/languageunsupervised/language understandingpaper. pdf, 2018.
[9] Radford A,Wu J, Child R, et al. Language models are unsupervised multitask learners[J].OpenAI Blog, 2019, 1(8).
[10] Liu Y, OttM, Goyal N, et al. Roberta: A robustly optimized bert pretraining approach[J].arXiv preprint arXiv:1907.11692, 2019.
[11] Lan Z, ChenM, Goodman S, et al. Albert: A lite bert for self-supervised learning oflanguage representations[J]. arXiv preprint arXiv:1909.11942, 2019.
[12] Jiao X, YinY, Shang L, et al. Tinybert: Distilling bert for natural languageunderstanding[J]. arXiv preprint arXiv:1909.10351, 2019.