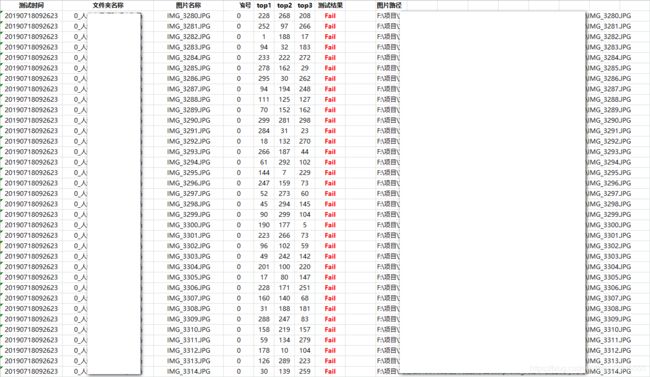
自动化测试脚本,返回值和预期结果对比,输出测试记录及统计测试数据
写个自动化测试脚本,测试给API传的bsae64编码参数,返回值和预期结果对比,输出测试记录及统计测试数据
import os
import re
import time
import datetime
import json
import requests
import xlwt
import base64
import logging
logger = logging.getLogger("log")
logger.setLevel(logging.DEBUG)
# logger的setLevel是最根本的
fh = logging.FileHandler('log' + time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) + '.log')
# 如果没有这个,就不会输出到文件
fh.setLevel(logging.INFO)
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
formatter = logging.Formatter("%(asctime)s - %(name)s - %(levelname)s - %(message)s")
ch.setFormatter(formatter)
fh.setFormatter(formatter)
logger.addHandler(ch)
logger.addHandler(fh)
print('\n')
print('保存文物文件夹命名规则:文物编号和文物名称之间用下划线连接,例如“0_人物车马俑驮行李陶马”,将所有类文物整理命名,放到一个目录文件夹下。')
print('\n')
print('备注:图片名称不用修改,只修改保存图片的文件夹名称。')
print('\n')
path = input('请将保存所有文物的文件夹拖入窗口,并点击回车!!!!!\n\n')
# accurates = input('请将、输入准确率阀值,识别准确率标准,并点击回车!!!!!\n\n')
accurates = 0.95 # 准确率阀值,识别准确率标准
num =1 # 每张图片测试次数,一般一张图测试1次
# path = r'F:\项目\文物\20190702识别率测试\小图\testprct' # 主目录为指定目录
# path = os.getcwd() #当前脚本路径下
class Cultural():
def process(self, path, accurates):
now = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) # 获取当前时间
red_style = xlwt.easyxf("font:colour_index red;font: bold on") # 写入红色加粗字体
green_style = xlwt.easyxf("font:colour_index green ;font: bold on") # 写入绿色加粗字体
# 创建表格填写表头
workbook = xlwt.Workbook() # 创建表格
worksheet0 = workbook.add_sheet('汇总页')
worksheet = workbook.add_sheet('测试记录')
# 填写测记录表头
worksheet.write(0, 0, "测试时间", xlwt.easyxf("font: bold on"))
worksheet.write(0, 1, "文件夹名称", xlwt.easyxf("font: bold on"))
worksheet.write(0, 2, "图片名称", xlwt.easyxf("font: bold on"))
worksheet.write(0, 3, "文物编号", xlwt.easyxf("font: bold on"))
worksheet.write(0, 4, "top1", xlwt.easyxf("font: bold on"))
worksheet.write(0, 5, "top2", xlwt.easyxf("font: bold on"))
worksheet.write(0, 6, "top3", xlwt.easyxf("font: bold on"))
worksheet.write(0, 7, "测试结果", xlwt.easyxf("font: bold on"))
worksheet.write(0, 9, "图片路径", xlwt.easyxf("font: bold on"))
x11 = 1
x12 = 1
x13 = 1
xt = 1
x_name_ww = 1
x_name_file = 1
x_imagepath = 1
x_serial = 1
x_result = 1
# 填写汇总测试数据表头
worksheet0.write(0, 0, "文物名称", xlwt.easyxf("font: bold on"))
worksheet0.write(0, 1, "文物编号", xlwt.easyxf("font: bold on"))
worksheet0.write(0, 2, "识别次数", xlwt.easyxf("font: bold on"))
worksheet0.write(0, 3, "准确次数", xlwt.easyxf("font: bold on"))
worksheet0.write(0, 4, "错误次数", xlwt.easyxf("font: bold on"))
worksheet0.write(0, 5, "识别准确率", xlwt.easyxf("font: bold on"))
x_name = 1
x_num = 1
x_pass = 1
xt_fail = 1
x_testnum = 1
x_rate = 1
filelist_cultural = os.listdir(path) # 获取路径下所有文件的列表
stan = [] # 达标列表
notstan = [] # 未达标列表
Passs = [] # 识别准确数
Fails = [] # 识别不准确数
sum = [] # 识别总次数
for fcatalog in Cultural.strsort(filelist_cultural):
path_fcatalog = os.path.join(path, fcatalog)
if os.path.isdir(path_fcatalog):
imagellist = os.listdir(path_fcatalog)
Pass = [] # 记录通过列表
Fail = [] # 记录失败列表
notimage = [] # 记录非图片列表
for imagepath in imagellist:
nowtest = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time()))
imagefile_path = os.path.join(path_fcatalog, imagepath)
if imagefile_path.endswith('.jpg'):
sum.append(imagefile_path)
for i in range(num):
top = Cultural.API(imagefile_path) # 给接口图片地址返回top3的值
try:
Cultural.writedata(xt, nowtest, x_name_file, fcatalog, x_name_ww, imagepath, x_serial, x11,top,x12, x13, x_imagepath, imagefile_path, worksheet)
except:
logger.error('写入数据异常……')
if str(fcatalog.split('_')[0]) == str(top[0]):# 判断一致通过
# if int(fcatalog.split('_')[0]) in top: # 判断top3存在
worksheet.write(x_result, 7, "Pass", green_style)
Pass.append("Pass")
Passs.append("Pass")
else:
# 不一致判断失败
worksheet.write(x_result, 7, "Fail", red_style)
Fail.append("Fail")
Fails.append("Fail")
x11 = x11 + 1
x12 = x12 + 1
x13 = x13 + 1
xt = xt + 1
x_name_ww = x_name_ww + 1
x_name_file = x_name_file + 1
x_imagepath = x_imagepath + 1
x_serial += 1
x_result += 1
elif imagefile_path.endswith('.JPG'):
sum.append(imagefile_path)
for i in range(num):
top = Cultural.API(imagefile_path) # 给接口图片地址返回top3的值
try:
Cultural.writedata(xt, nowtest, x_name_file, fcatalog, x_name_ww, imagepath, x_serial, x11,top,x12, x13, x_imagepath, imagefile_path, worksheet)
except:
logger.error('数据写入异常……')
if str(fcatalog.split('_')[0]) == str(top[0]):# 判断一致通过
#if int(fcatalog.split('_')[0]) in top: # 判断top3存在
worksheet.write(x_result, 7, "Pass", green_style)
Pass.append("Pass")
Passs.append("Pass")
else:
worksheet.write(x_result, 7, "Fail", red_style)
Fail.append("Fail")
Fails.append("Fail")
x11 = x11 + 1
x12 = x12 + 1
x13 = x13 + 1
xt = xt + 1
x_name_ww = x_name_ww + 1
x_name_file = x_name_file + 1
x_imagepath = x_imagepath + 1
x_serial += 1
x_result += 1
else:
notimage.append(imagefile_path.split('_')[-1])
# 汇总测试数据,准确率、测试次数等信息
if (len(Pass) / len(imagellist)) >= accurates: # 准确率达标判断
stan.append((len(Pass) / len(imagellist)))
worksheet0.write(x_rate, 5, (len(Pass) / (len(imagellist)*num)), green_style) # 准确率
else:
notstan.append((len(Pass) / len(imagellist)))
worksheet0.write(x_rate, 5, (len(Pass) / len(imagellist)), red_style) # 准确率
worksheet0.write(x_name, 0, fcatalog.split('_')[1:]) # 文物名称
worksheet0.write(x_num, 1, int(fcatalog.split('_')[0])) # 文物编号
worksheet0.write(x_testnum, 2, (len(imagellist) - len(notimage))*num) # 总数
worksheet0.write(x_pass, 3, len(Pass)) # 准确数
worksheet0.write(xt_fail, 4, len(Fail)) # 失败数
# worksheet.write(x_rate, 28, ("%.2f%%" % ((len(Pass) / len(imagellist)) * 100))) # 准确率
x_name += 1
x_num += 1
x_pass += 1
xt_fail += 1
x_testnum += 1
x_rate += 1
worksheet0.write(0, 7, '测试汇总', xlwt.easyxf("font: bold on"))
worksheet0.write(1, 7, '文物识别测试件数:' + str((len(filelist_cultural))))
worksheet0.write(2, 7, '识别总数(次数、图片总数):' + str(len(sum)*num))
worksheet0.write(3, 7, '识别准确数:' + str(len(Passs)))
worksheet0.write(4, 7, '识别不准确数:' + str(len(Fails)))
worksheet0.write(5, 7, '识别准确率达标数:' + str(len(stan)))
worksheet0.write(6, 7, '识别准确率未达标数:' + str(len(notstan)))
worksheet0.write(8, 7, '文物识别准确率满足标准的达标率:' + ("%.2f%%" % (len(stan) / (len(filelist_cultural)) * 100)))
worksheet0.write(7, 7, '准确率标准为不低于' + str(accurates * 100) + '%')
worksheet0.write(9, 7,
'本次文物识别共计测试' + str(len(filelist_cultural)) + '件,准确率达标' + str(len(stan)) + '件,剩余' + str(
len(notstan)) + '件未达标,达标率为:' + ("%.2f%%" % (len(stan) / (len(filelist_cultural)) * 100)),
xlwt.easyxf("font: bold on"))
worksheet0.write(11, 7, '于' + datetime.datetime.now().strftime('%Y{y}%m{m}%d{d}').format(y='年', m='月', d='日'))
workbook.save('文物识别准确率测试' + now + '.xls') # 保存excel
def writedata(self, xt, nowtest, x_name_file, fcatalog, x_name_ww, imagepath, x_serial, x11, top, x12, x13,
x_imagepath, imagefile_path, worksheet):
worksheet.write(xt, 0, nowtest)
# logger.info("写入" + str(fcatalog) + "文件夹名称")
worksheet.write(x_name_file, 1, fcatalog)
# logger.info("写入" + str(imagepath) + "测试图片名称")
worksheet.write(x_name_ww, 2, imagepath)
# logger.info("写入" + fcatalog.split('_')[0] + "文物编号")
worksheet.write(x_serial, 3, int(fcatalog.split('_')[0]))
logger.info("文物《" + str(fcatalog) + "》的《" + str(imagepath) + "》图片,识别为:" + str(top[0])+','+str(top[1])+','+str(top[2]))
worksheet.write(x11, 4, (top[0]))
# logger.info("写入文物《" + str(fcatalog) + "》的《" + str(imagepath) + "》图片,top2:" + str(top2))
worksheet.write(x12, 5, (top[1]))
# logger.info("写入文物《" + str(fcatalog) + "》的《" + str(imagepath) + "》图片,top3:" + str(top3))
worksheet.write(x13, 6, (top[2]))
# logger.info("写入" + str(imagefile_path) + "图片路径")
worksheet.write(x_imagepath, 9, imagefile_path)
def API(self, imagefile_path):# 给接口图片地址返回top3的值
with open(imagefile_path, "rb") as f:
# b64encode是编码,b64decode是解码
base64_data = base64.b64encode(f.read())
str_base64 = str(base64_data, 'utf-8')
url = "https://**.*************.com:8***/***/***/Test.html"
payload = {
"file": str_base64, "fileName": imagefile_path.split('\\')[-1]
}
headers = {
'Content-Type': "application/json",
}
payload = json.dumps(payload) # 将字典类型转换为 JSON 对象,序列化
try:
r = requests.post(url, data=payload, headers=headers)
r.raise_for_status() # 如果响应状态码不是 200,就主动抛出异常
except :
#logger.error( '请查看网络是否异常!!')
return ["请查看网络是否异常!!", 'error', 'error'] # 出现异常,能不中断继续测试
else:
if len(r.text.split(',')) == 3:
return list(map(int, r.text.split(','))) # 将字srt列表转int列表
elif r.text=='-1':
return [-1,' ',' ']
else:
#logger.error(r.text + '……请查看服务器网络否异常!!')
return [r.text, 'error', 'error'] # 出现异常,能不中断继续测试
def sort_key(self, s): # 排序
# 排序关键字匹配
# 匹配开头数字序号
if s:
try:
c = re.findall('^\d+', s)[0]
except:
c = -1
return int(c)
def strsort(self, alist): # 排序
alist.sort(key=Cultural.sort_key)
return alist
def execute(self, path, accurates):
if os.path.exists(path):
try:
Cultural.process(path, accurates)
except:
print('\n')
print('拖入文件夹不满足要求!!!')
else:
print('输入的路径不存在')
if __name__ == '__main__':
Cultural = Cultural()
Cultural.execute(path, accurates)
print('\n')
input('Press Enter to exit...')
脚本运行:
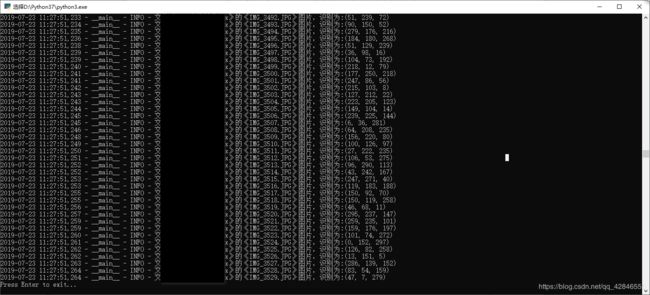
汇总测试数据结果
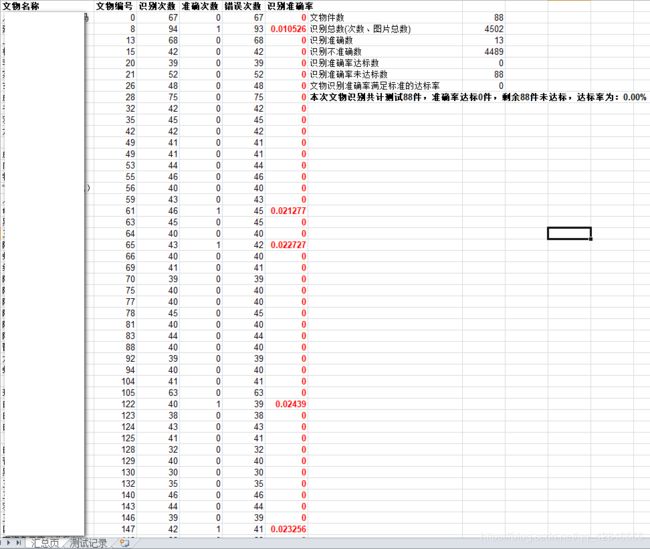
测试记录