sklearn.cluster聚类算法:K-means和DBSCAN 学习笔记
首先放两个好玩的网页,动态可视化展示K-means和DBSCAN
- K-mean
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/ - DBSCAN
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
import pandas as pd
beer=pd.read_csv('data.txt',sep=' ')
X = beer[['calories', 'sodium', 'alcohol', 'cost']]
from sklearn.cluster import KMeans
km = KMeans(n_clusters = 3).fit(X)
km2 =KMeans(n_clusters = 2).fit(X)
print(km.labels_)
print(km2.labels_)
beer['cluster'] = km.labels_
beer['cluster2'] =km2.labels_
beer.sort_values('cluster')

# 画图
from pandas.plotting import scatter_matrix
%matplotlib inline
cluster_centers = km.cluster_centers_
cluster2_centers=km2.cluster_centers_
centers = beer.groupby('cluster').mean().reset_index()
centers2=beer.groupby('cluster2').mean().reset_index()
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14
import numpy as np
colors = np.array(['red','green','blue','yellow'])
plt.figure(figsize=(8,6))
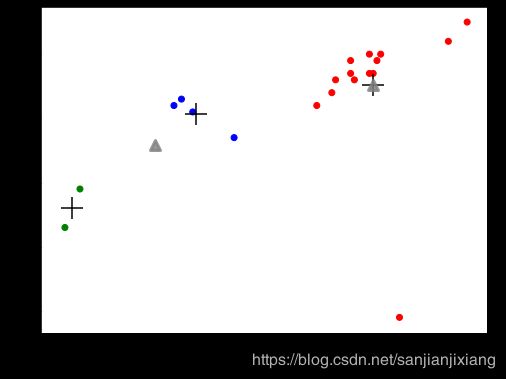
plt.scatter(beer['calories'], beer['alcohol'], c = colors[beer['cluster']])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=500, c='black')
plt.scatter(centers2.calories,centers2.alcohol,linewidths=3, marker='^',s=100,c='gray',alpha=0.8)
plt.xlabel('Calories')
plt.ylabel('Alcohol')
plt.show()
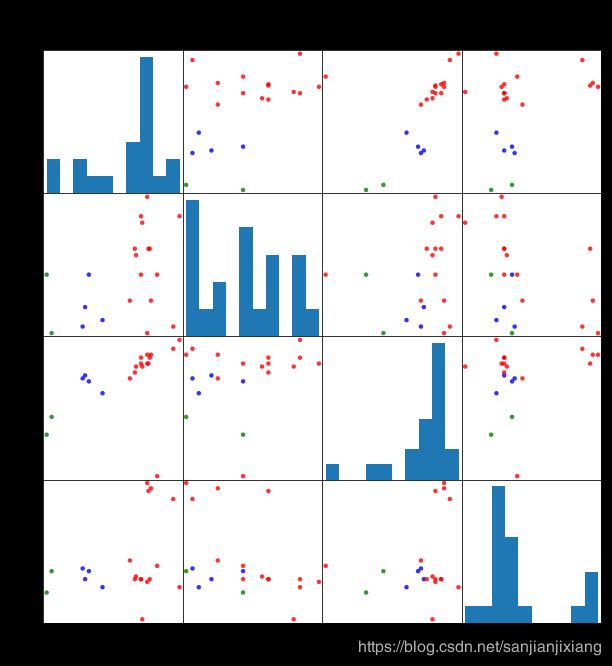
scatter_matrix(beer[['calories','sodium','alcohol','cost']],s=80,alpha=0.8,
c=colors[beer['cluster']],figsize=(10,10))
plt.suptitle('With 3 centroids initialized',fontsize=18)
plt.subplots_adjust(top=0.92)
plt.show()
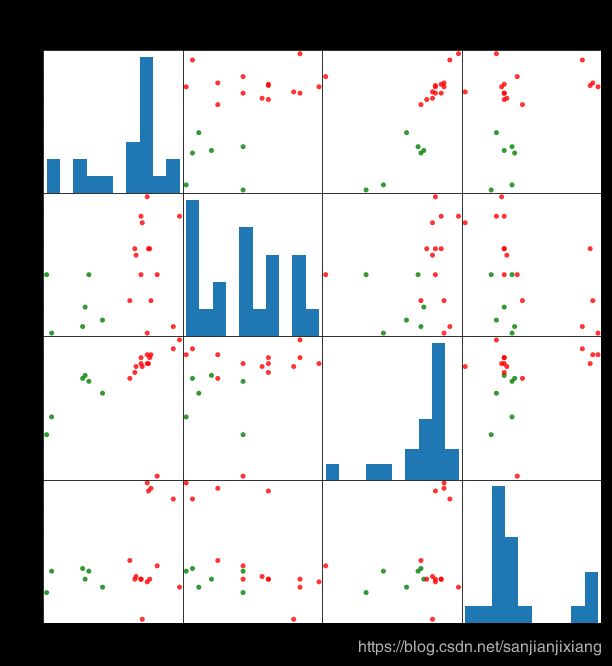
scatter_matrix(beer[['calories','sodium','alcohol','cost']], s=100, alpha=0.8,
c = colors[beer['cluster2']], figsize=(10,10))
plt.suptitle('With 2 centrorids initialized', fontsize=18)
plt.subplots_adjust(top=0.92)
数据预处理后看聚类效果
# 数据预处理:标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
km = KMeans(n_clusters = 2).fit(X_scaled)
beer['scaled_cluster'] = km.labels_
beer.sort_values('scaled_cluster')
pd.plotting.scatter_matrix(X,c=colors[beer.scaled_cluster],alpha=0.8,figsize=(10,10),s=120)
plt.show()
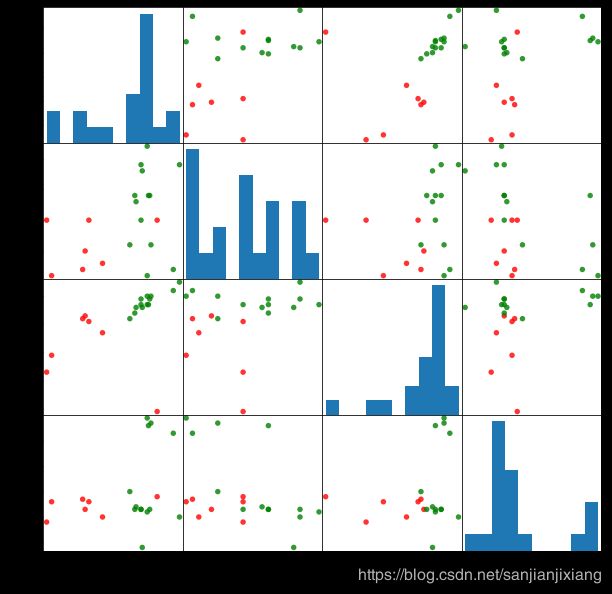
从上图可看出此次数据标准化后聚类效果并不如原始数据.
聚类评估:轮廓系数(Silhouette Coefficient)
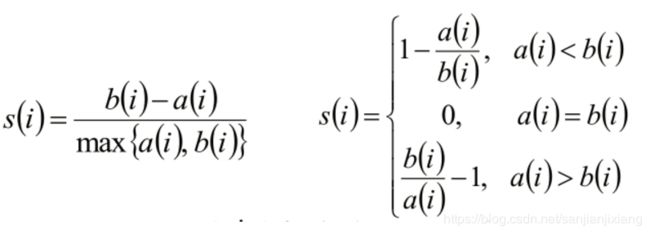
si接近1,则说明样本i聚类合理
si接近-1,则说明样本i更应该分类到另外的簇
若si 近似为0,则说明样本i在两个簇的边界上。
from sklearn import metrics
score_scaled = metrics.silhouette_score(X, beer.scaled_cluster)
score = metrics.silhouette_score(X, beer.cluster)
score2= metrics.silhouette_score(X, beer.cluster2)
print(score_scaled, score, score2)
0.5562170983766765
0.6731775046455796
0.6917656034079486
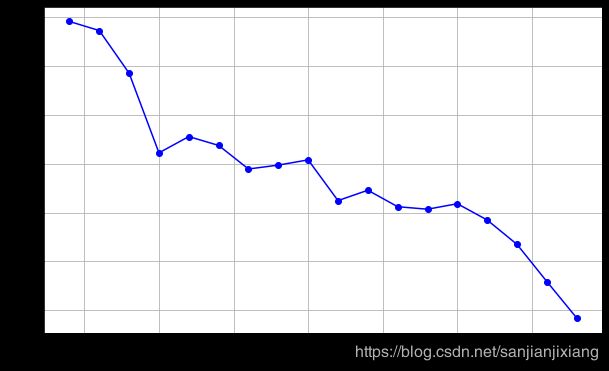
scores = []
for k in range(2,20):
labels = KMeans(n_clusters = k).fit(X).labels_
score = metrics.silhouette_score(X, labels)
scores.append(score)
plt.figure(figsize = (10, 6))
plt.plot(list(range(2,20)), scores, 'bo-')
plt.grid()
plt.xlabel('Number of Clusters Initialized')
plt.ylabel('Sihouette Score')
DBSCAN clustering
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=10, min_samples=2).fit(X)
labels = db.labels_
beer['cluster_db'] = labels
beer.sort_values('cluster_db')
pd.plotting.scatter_matrix(X, c=colors[beer.cluster_db], figsize=(10,10), s=100)
plt.show()

scores = []
for s in range(2, 10):
labels = DBSCAN(eps = 10, min_samples = s).fit(X).labels_
score = metrics.silhouette_score(X, labels)
scores.append(score)
plt.figure(figsize = (8, 6))
plt.plot(list(range(2,10)), scores, 'r*-')
plt.grid()
plt.xlabel('Number of min_samples')
plt.ylabel('Sihouette Score')
