Linux系统管理系统性能分析
Linux系统管理系统性能分析
概述
性能优化就是找到系统处理中的瓶颈以及去除这些的过程,多数管理员相信看一些相关的"cook book"就可以实现性能优化,通常通过对内核的一些配置是可以简单的解决问题,但并不适合每个环境,性能优化其实是对OS 各子系统达到一种平衡的定义。当出现故障时,我们首先就要登录操作系统进行检查,先从操作系统层面分析-确认下CPU、内存、I/O、网络是否异常,每个系统的命令不一样,常见的有top、topas、vmstat、iostat。
如果从操作系统层面发现问题,就好入手了,就算操作系统层面没有问题,至少也可以排除OS或硬件资源级
我们来看性能分析的目的1找出系统瓶颈,包括软硬件。2提供性能优化方案3资源的合理配置.
linux: top,vmstat,free,iostat。长期监控nmon。
即时查看工具:iostat、mpstat、sar
累计统计工具:sar
1 top命令
命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
top命令是Linux/unix下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。Linux/Unix系统可以通过top命令查看系统的CPU、内存、运行时间、交换分区、执行的线程等信息。
通过top命令可以有效的发现系统的缺陷出在哪里。是内存不够、CPU处理能力不够、IO读写过高。
1.1 第一行详解
top - 20:06:02 up 1 min, 1 user, load average: 0.56, 0.34, 0.13
0:06:02 表示系统当前时间。
up 1 min表示系统最后一次启动后总的运行时间。
1 user 表示当前系统中只有一个登录用户。
load average: 0.56, 0.34, 0.13 表示系统的平均负载,最后的三个数字分别表示最后一分钟的系统平均负载,最后五分钟的系统平均负载,最后十五分钟的系统平均负载。
需要注意的是load average
load average
系统负载(System Load)是系统CPU繁忙程度的度量,即有多少进程在等待被CPU调度(进程等待队列的长度)。
平均负载(Load Average)是一段时间内系统的平均负载,这个一段时间一般取1分钟、5分钟、15分钟。
CPU load averages,可以将该值除以 CPU 数量,load average低于0.7是安全的。load average接近1表明CPU在全力运作,则表示正在运行饱和,这可能会导致性能问题。
1.2 第二行和第三行详解
Tasks: 138 total, 2 running, 136 sleeping, 0 stopped, 0 zombie
Cpu(s): 34.0%us, 15.8%sy, 0.0%ni, 49.4%id, 0.7%wa, 0.0%hi, 0.2%si, 0.0%st
138 total 进程总数
2 running 正在运行的进程数
136 sleeping 睡眠的进程数
0 stopped 停止的进程数
0 zombie 僵尸进程数
34.0 us 用户空间占用CPU百分比
15.8 sy 内核空间占用CPU百分比
0.0 ni 用户进程空间内改变过优先级的进程占用CPU百分比
49.3 id 空闲CPU百分比
0.0 wa 等待输入输出的CPU时间百分比
0.0 hi 硬中断(Hardware IRQ)占用CPU的百分比
- si 软中断(Software Interrupts)占用CPU的百分比
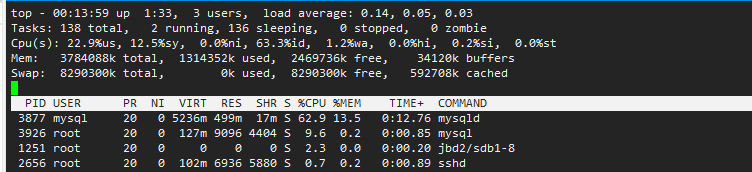
1.3 top命令-性能关注点%CPU,%M
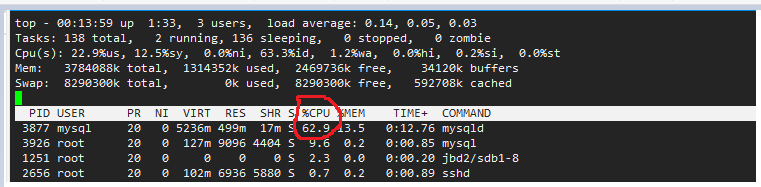
Tasks: 138 total, 2 running, 136 sleeping, 0 stopped, 0 zombie
Cpu(s): 34.0%us, 15.8%sy, 0.0%ni, 49.4%id, 0.7%wa, 0.0%hi, 0.2%si, 0.0%st
Mem: 3784088k total, 1490748k used, 2293340k free, 40248k buffers
Swap: 8290300k total, 0k used, 8290300k free, 687480k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
3877 mysql 20 0 5236m 569m 17m S 89.8 15.4 0:19.32 mysqld
3926 root 20 0 127m 9096 4404 S 10.3 0.2 0:01.60 mysql
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S —进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
查看进程所占CPU百分比的时间最多,总体使用了22.9%,mysql进程占用了62%。
如果总体再70%以下,说明服务器性能还算可以。
Shift+p 按CPU排序 shift+m 按内存排序。
2 free命令
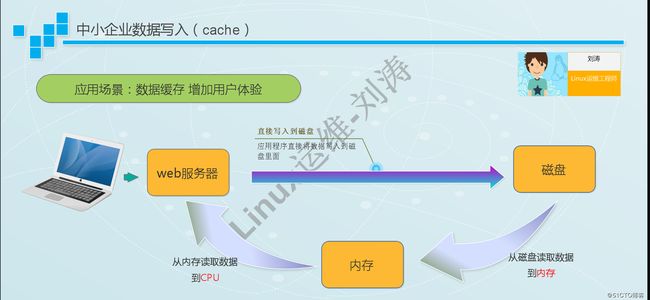
buffer:缓冲,(缓冲区)是系统两端处理速度平衡(从长时间尺度上看)时使用的。它的引入是为了减小短期内突发I/O的影响,突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O。解决写。
cache:缓存,(缓存区)是系统两端处理速度不匹配时的一种折衷策略,经常被用在磁盘的I/O请求上,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提高系统性能。解决读。
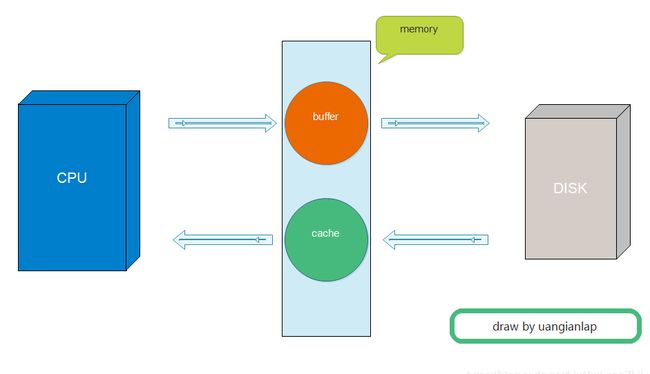
什么是buffer
buffer(即缓冲区),简单的说就是将写入磁盘的IO先写入到内存中,当达到了一定的时间或者是一定的大小的时候,再一次性地写入到磁盘中,这是一个取的过程!数据流向:CPU ==》内存==》磁盘
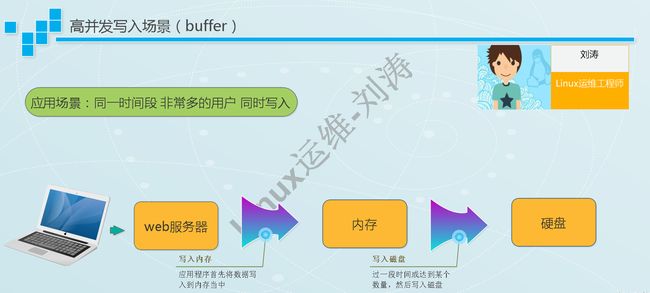
什么是cache
cache(缓存区),简单的说就是为了避免程序大量的对磁盘进行读写,我们先将磁盘中的数据写入到内存中,然后程序直接在内存中去读取数据,是一个取的过程!数据流向:磁盘==》内存==》CPU
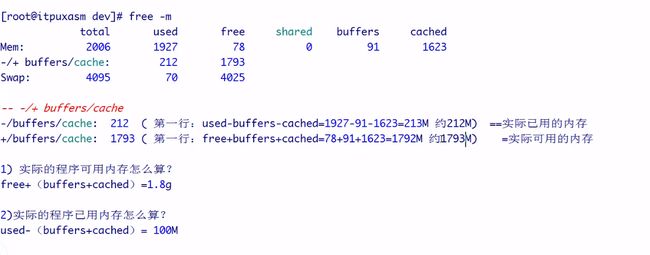
2.1 linux 6 free -hm
total used free shared buffers cached
Mem: 32099 31909 189 1 100 28679
-/+ buffers/cache: 3129 28969
Swap: 15999 0 15999
[Mem: total] 总的物理内存
[Mem: used] 表示操作系统申请的物理内存大小
[Mem: free] 表示剩余的内存(操作系统还没有占用)
[Mem: shared] 进程间共享的内存
[Mem: buffers ] 表示OS申请的内存中,可用的buffer(用于写)
[Mem: cached ] 表示OS申请的内存中,可用的cache(用于读)
[-/+buffers/cache: used ] 表示已经使用的buffer和cache
[-/+buffers/cache: used ]= [Mem: used] - [Mem: buffers+ Mem: cached]
[-/+buffers/cache: free ] 表示剩余(可用)的buffer和cache(表示OS已经申请的内存中,可用的buffer和可用的cache + 剩余可供OS申请的内存[Mem:free])
[-/+buffers/cache: free ]=[Mem: free] +[Mem: buffers] + [Mem: cached]
一般来说,如果[ -/+ buffers/cache: free ]很大,则表明剩余内存较多。
重点注意[Mem: free]的大小并不能反映内存的实际使用情况。
查看 -/+ buffers/cache : free ,如果其值非常小,而swap使用的较多,即表明内存不够用了。
2.2 linux7 free -hm
total used free shared buff/cache available
Mem: 5.7G 437M 4.5G 274M 713M 4.7G
Swap: 2.0G 0B 2.0G
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
free 与 available
在 free 命令的输出中,有一个 free 列,同时还有一个 available 列。这二者到底有何区别?
free 是真正尚未被使用的物理内存数量。至于 available 就比较有意思了,它是从应用程序的角度看到的可用内存数量。Linux 内核为了提升磁盘操作的性能,会消耗一部分内存去缓存磁盘数据,就是我们介绍的 buffer 和 cache。所以对于内核来说,buffer 和 cache 都属于已经被使用的内存。当应用程序需要内存时,如果没有足够的 free 内存可以用,内核就会从 buffer 和 cache 中回收内存来满足应用程序的请求。所以从应用程序的角度来说,available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
交换空间(swap space)
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件。所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。
现在的机器一般都不太缺内存,如果系统默认还是使用了 swap 是不是会拖累系统的性能?理论上是的,但实际上可能性并不是很大。并且内核提供了一个叫做 swappiness 的参数,用于配置需要将内存中不常用的数据移到 swap 中去的紧迫程度。这个参数的取值范围是 0~100,0 告诉内核尽可能的不要将内存数据移到 swap 中,也即只有在迫不得已的情况下才这么做,而 100 告诉内核只要有可能,尽量的将内存中不常访问的数据移到 swap 中。在 ubuntu 系统中,swappiness 的默认值是 60。如果我们觉着内存充足,可以在 /etc/sysctl.conf 文件中设置 swappiness:
vm.swappiness=10
Linux7不会显示buff/cache单独的使用量,其实 free 命令中的信息都来自于 /proc/meminfo 文件。/proc/meminfo 文件包含了更多更原始的信息
cat /proc/meminfo
3 vmstat命令
vmstat 命令报告关于内核线程、虚拟内存、磁盘、陷阱和 CPU 活动的统计信息。由 vmstat 命令生成的报告可以用于平衡系统负载活动。系统范围内的这些统计信息(所有的处理器中)都计算出以百分比表示的平均值,或者计算其总和。
其中有两个比较常用的参数
vmstat 5 每5秒执行一次
vmstat 5 8 每5秒执行一次,执行8次。
[root@mysql5 ~]# vmstat 5 4
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2808468 45332 372920 0 0 7 7 14 38 0 0 100 0 0
1 0 0 2808452 45332 372948 0 0 0 0 28 102 0 0 100 0 0
1 0 0 2808436 45332 372948 0 0 0 4 26 95 0 0 100 0 0
1 0 0 2808436 45332 372948 0 0 0 20 27 74 0 0 100 0 0
Procs(进程):
r: 运行队列中进程数量——不能超过CPU个数。
b: 等待IO的进程数量
Memory(内存):
swpd: 使用虚拟内存大小——不能大于0。
free: 可用内存大小
buff: 用作缓冲的内存大小
cache: 用作缓存的内存大小
Swap:
si: 每秒从交换区写到内存的大小——不能大于0。
so: 每秒写入交换区的内存大小——不能大于0。
IO:
bi: 每秒读取的块数
bo: 每秒写入的块数
系统:
in: 每秒中断数,包括时钟中断。【interrupt】
cs: 每秒上下文切换数。 【count/second】
CPU(以百分比表示):
us: 用户进程执行时间(user time)
sy: 系统进程执行时间(system time)
id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
wa: 等待IO时间
4 iostat性能分析
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
单独首次执行iostat,显示的结果为从系统开机到当前执行时刻的统计信息。
第一行 最上面指示系统版本、主机名和当前日期
avg-cpu 总体cpu使用情况统计信息,对于多核cpu,这里为所有cpu的平均值
Device 各磁盘设备的IO统计信息

选项 说明
%user CPU在用户态执行进程的时间百分比。
%nice CPU在用户态模式下,用于nice操作,所占用CPU总时间的百分比
%system CPU处在内核态执行进程的时间百分比
%iowait CPU用于等待I/O操作占用CPU总时间的百分比
%steal 管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU的百分比
%idle CPU空闲时间百分比
备注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
device:磁盘名称
tps:每秒钟发送到的I/O请求数.
Blk_read/s:每秒读取的block数.
Blk_wrtn/s:每秒写入的block数.
Blk_read:读入的block总数.
Blk_wrtn:写入的block总数.
iostat 1 5
间隔1秒,总共显示5次
iostat -x 2 3
每隔2秒显示一次,共输出3次,详细信息
iostat -m
以M为单位显示所有信息
备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
4.1 查询tps
iostat -d -m 2
Linux 4.1.12-61.1.28.el6uek.x86_64 (mysqldb) 2020年07月26日 _x86_64_ (2 CPU)
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 1.62 0.02 0.00 351 41
sdb 0.21 0.00 0.00 17 0
scd0 0.00 0.00 0.00 0 0
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
MB_read:读取的总数据量;
MB_wrtn:写入的总数量数据量
5 sar性能分析工具(很少用)
在使用 Linux 系统时,常常会遇到各种各样的问题,比如系统容易死机或者运行速度突然变慢,这时我们常常猜测:是否硬盘空间不足,是否内存不足,是否 I/O 出现瓶颈,还是系统的核心参数出了问题?这时,我们应该考虑使用 sar 工具对系统做一个全面了解,分析系统的负载状况。
sar(System Activity Reporter)是系统活动情况报告的缩写。sar 工具将对系统当前的状态进行取样,然后通过计算数据和比例来表达系统的当前运行状态。它的特点是可以连续对系统取样,获得大量的取样数据;取样数据和分析的结果都可以存入文件,所需的负载很小。 sar 是目前 Linux 上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。为了提供不同的信息,sar 提供了丰富的选项、因此使用较为复杂。
sar命令常用格式
sar [options] [-A] [-o file] t [n]
t为采样间隔, n为采样次数,默认值是1 ;
5.1 u CPU使用率
sar (查看全天)
sar -u 1 10 (1:每隔一秒,10:写入10次)
sar –u –o.log 1 10 (1:每隔一秒,10:写入10次,写入文件)
sar 8 5 #不加任何选项默认就是CPU,每隔8秒,扫描5次。
[root@mysqldb ~]# sar -u 8 6
Linux 4.1.12-61.1.28.el6uek.x86_64 (mysqldb) 2020年07月26日 _x86_64_ (2 CPU)
18时34分03秒 CPU %user %nice %system %iowait %steal %idle
18时34分11秒 all 0.00 0.00 0.06 0.00 0.00 99.94
18时34分19秒 all 0.38 0.00 0.25 0.00 0.00 99.37
18时34分27秒 all 0.00 0.00 0.00 0.00 0.00 100.00
18时34分35秒 all 0.00 0.00 0.06 0.00 0.00 99.94
18时34分43秒 all 0.00 0.00 0.00 0.00 0.00 100.00
18时34分51秒 all 0.00 0.00 0.06 0.00 0.00 99.94
平均时间: all 0.06 0.00 0.07 0.00 0.00 99.86
输出项说明:
| CPU |
all 表示统计信息为所有 CPU 的平均值。 |
| %user |
显示在用户级别(application)运行使用 CPU 总时间的百分比。 |
| %nice |
显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。 |
| %system |
在核心级别(kernel)运行所使用 CPU 总时间的百分比。 |
| %iowait |
显示用于等待I/O操作占用 CPU 总时间的百分比。 |
| %steal |
管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟 CPU 的百分比。 |
| %idle |
显示 CPU 空闲时间占用 CPU 总时间的百分比。 |
若 %iowait 的值过高,表示硬盘存在I/O瓶颈
若 %idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
若 %idle 的值持续低于 10,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
5.2 r 内存和交换空间监控
sar -r (查看全天)
sar -r 5 4 (5:每隔5秒,4:写入4次)
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间。
Kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间。
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比。
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache。
Kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap)。
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比。
5.3 –d磁盘IO
一定要加-p 就知道磁盘的名字了
sar -d 2 2
[root@mysqldb ~]# sar -d -p 3 2
Linux 4.1.12-61.1.28.el6uek.x86_64 (mysqldb) 2020年07月26日 _x86_64_ (2 CPU)
23时40分15秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
23时40分18秒 sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
23时40分18秒 sdb 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
23时40分18秒 sr0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
await表示平均每次设备I/O操作的等待时间(以毫秒为单位)。
svctm表示平均每次设备I/O操作的服务时间(以毫秒为单位)。
%util表示一秒中有百分之几的时间用于I/O操作。 这个值如果很大的话就有问题,值越高,说明I/O越慢
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。这个值不能超过设备总体70%。
DEV 磁盘设备的名称,如果不加-p,会显示dev253-0类似的设备名称,因此加上-p显示的名称更直接
tps 每秒I/O的传输总数
rd_sec/s 每秒读取的扇区的总数
wr_sec/s 每秒写入的扇区的总数
avgrq-sz 平均每次次磁盘I/O操作的数据大小(扇区)
avgqu-sz 磁盘请求队列的平均长度
await 从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括请求队列等待时间,单位是毫秒(1秒等于1000毫秒),等于寻道时间+队列时间+服务时间
svctm I/O的服务处理时间,即不包括请求队列中的时间
%util I/O请求占用的CPU百分比,值越高,说明I/O越慢
5.5 q查看平均负载
sar -q 3 2
Linux 4.1.12-61.1.28.el6uek.x86_64 (mysqldb) 2020年07月26日 _x86_64_ (2 CPU)
23时34分42秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
23时34分45秒 0 212 0.00 0.01 0.05
23时34分48秒 0 212 0.00 0.01 0.05
平均时间: 0 212 0.00 0.01 0.05
runq-sz 运行队列的长度(等待运行的进程数,每核的CP不能超过2个)
plist-sz 进程列表中的进程(processes)和线程数(threads)的数量
ldavg-1 最后1分钟的CPU平均负载,即将多核CPU过去一分钟的负载相加再除以核心数得出的平均值,5分钟和15分钟以此类推
ldavg-5 最后5分钟的CPU平均负载
ldavg-15 最后15分钟的CPU平均负载
5.X –o导出成文件
sar –u –o.log 1 10 (1:每隔一秒,10:写入10次,写入文件)
sar -f cpu.log 查看 用cat是乱码
6 网络相关
6.1netstat
Netstat是控制台命令,是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。Netstat用于显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
netstat常见参数
-a (all) 显示所有选项,默认不显示LISTEN相关。
-t (tcp) 仅显示tcp相关选项。
-u (udp) 仅显示udp相关选项。
-n 拒绝显示别名,能显示数字的全部转化成数字。
-l 仅列出有在 Listen (监听) 的服务状态。
-p 显示建立相关链接的程序名
-r 显示路由信息,路由表
-e 显示扩展信息,例如uid等
-s 按各个协议进行统计
-c 每隔一个固定时间,执行该netstat命令。
netstat -help
状态说明
LISTEN:侦听来自远方的TCP端口的连接请求
SYN-SENT:再发送连接请求后等待匹配的连接请求(如果有大量这样的状态包,检查是否中招了)
SYN-RECEIVED:再收到和发送一个连接请求后等待对方对连接请求的确认(如有大量此状态,估计被flood攻击了)
ESTABLISHED:代表一个打开的连接
FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认
FIN-WAIT-2:从远程TCP等待连接中断请求
CLOSE-WAIT:等待从本地用户发来的连接中断请求
CLOSING:等待远程TCP对连接中断的确认
LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认(不是什么好东西,此项出现,检查是否被攻击)
TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认
CLOSED:没有任何连接状态
netstat -lntup
6.2 ifconfig
Ifconfig 查看网卡信息
6.3 traceroute 追踪路由
traceroute 182.61.200.7
traceroute to 182.61.200.7 (182.61.200.7), 30 hops max, 60 byte packets
1 192.168.198.2 (192.168.198.2) 0.206 ms 0.053 ms 0.101 ms