MyDLNote-Enhancement : CVPR2019-基于注意力的操作适应性选择的混合未知畸变图像修复
CVPR 2019 : Attention-based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions

[paper] : Attention-based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions
目录
CVPR 2019 : Attention-based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions
Abstract
Introduction
Operation-wise Attention Network
Operation-wise Attention Layer
Operation Layer
Feature Extraction Block and Output Layer
Experimental Configuration
Abstract
Many studies have been conducted so far on image restoration, the problem of restoring a clean image from its distorted version. There are many different types of distortion which affect image quality.
Previous studies have focused on single types of distortion, proposing methods for removing them. However, image quality degrades due to multiple factors in the real world.
Thus, depending on applications, e.g., vision for autonomous cars or surveillance cameras, we need to be able to deal with multiple combined distortions with unknown mixture ratios.
这段介绍了研究背景、问题和动机。
For this purpose, we propose a simple yet effective layer architecture of neural networks. It performs multiple operations in parallel, which are weighted by an attention mechanism to enable selection of proper operations depending on the input. The layer can be stacked to form a deep network, which is differentiable and thus can be trained in an end-to-end fashion by gradient descent.
本文的方法:提出了一个网络结构,并行地执行多个操作,并通过一个注意机制对其进行加权,以便根据输入选择适当的操作。
The experimental results show that the proposed method works better than previous methods by a good margin on tasks of restoring images with multiple combined distortions.
实验结论:实验结果表明,该方法在处理多重畸变的图像恢复时比以往的方法有更好的效果。
Introduction
The problem of image restoration, which is to restore a clean image from its degraded version, has a long history of research. Previously, researchers tackled the problem by modeling (clean) natural images, where they design image prior, such as edge statistics [7, 34] and sparse representation [1, 45], based on statistics or physics-based models of natural images. Recently, learning-based methods using convolutional neural networks (CNNs) [18, 16] have been shown to work better than previous methods that are based on the hand-crafted priors, and have raised the level of performance on various image restoration tasks, such as denoising [44, 50, 39, 51], deblurring [29, 38, 17], and superresolution [6, 19, 53].
研究领域的大背景:图像修复,早期就是基于自然图像的物理模型来设计图像先验,例如边缘统计和稀疏表示等。深度学习的出现,全面超越了手动设计先验知识的方法。
There are many types of image distortion, such as Gaussian/salt-and-pepper/shot noises, defocus/motion blur, compression artifacts, haze, raindrops, etc. Then, there are two application scenarios for image restoration methods. One is the scenario where the user knows what image distortion he/she wants to remove; an example is a deblurring filter tool implemented in a photo editing software. The other is the scenario where the user does not know what distortion(s) the image undergoes but wants to improve its quality, e.g., applications to vision for autonomous cars and surveillance cameras.
In this paper, we consider the latter application scenario. Most of the existing studies are targeted at the former scenario, and they cannot be directly applied to the latter. Considering that real-world images often suffer from a combination of different types of distortion, we need image restoration methods that can deal with combined distortions with unknown mixture ratios and strengths.
问题铺垫和动机提出:
有许多类型的图像失真,如高斯/盐和胡椒/镜头噪声,散焦/运动模糊,压缩伪影,烟雾,雨滴,等等。
一种情况是,用户知道他/她想要消除什么样的图像失真;一个例子是在照片编辑软件中实现的去模糊滤镜工具。(现象大部分算法这么做)
另一种情况,用户不知道图像会有什么样的失真,但想要提高其质量,比如自动驾驶汽车和监控摄像头的视觉应用。(本文要解决的问题)
考虑到现实世界的图像经常会受到不同类型失真的组合,我们需要一种能够处理混合比例和强度未知的组合失真的图像恢复方法。
There are few works dealing with this problem. A notable exception is the work of Yu et al. [48], which proposes a framework in which multiple light-weight CNNs are trained for different image distortions and are adaptively applied to input images by a mechanism learned by deep reinforcement learning. Although their method is shown to be effective, we think there is room for improvements. One is its limited accuracy; the accuracy improvement gained by their method is not so large, as compared with application of existing methods for a single type of distortion to images with combined distortions. Another is its inefficiency; it uses multiple distortion-specific CNNs in parallel, each of which also needs pretraining.
现有算法考察:
Yu et al. [48] 是最早的混合失真图像处理,针对不同的图像畸变训练多个轻型 CNNs,并通过深度强化学习机制自适应地应用于输入图像。但这个方法有两个问题:有限的准确性和效率低。
In this paper, we show that a simple attention mechanism can better handle aforementioned combined image distortions. We design a layer that performs many operations in parallel, such as convolution and pooling with different parameters. We equip the layer with an attention mechanism that produces weights on these operations, intending to make the attention mechanism to work as a switcher of these operations in the layer. Given an input feature map, the proposed layer first generates attention weights on the multiple operations. The outputs of the operations are multiplied with the attention weights and then concatenated, forming the output of this layer to be transferred to the next layer.
We call the layer operation-wise attention layer. This layer can be stacked to form a deep structure, which can be trained in an end-to-end manner by gradient descent; hence, any special technique is not necessary for training. We evaluate the effectiveness of our approach through several experiments.
本文的方法:
1. 设计了一个层并行执行许多操作:如卷积和池与不同的参数;
2. 采用了一个注意力机制:目的对这些不同操作进行选择切换。
实例:给定一个输入特征图,提取不同特征;通过注意力机制选择符合该收入图像修复所需特征层。
这种结构的好处是可堆叠成一个深层结构,通过梯度下降进行端到端训练;因此,训练中不需要任何特殊的技巧。
本文的贡献(略)。
Operation-wise Attention Network
In this section, we describe the architecture of an entire network that employs the proposed operation-wise attention layers; see Fig.1 for its overview. It consists of three parts: a feature extraction block, a stack of operation-wise attention layers, and an output layer. We first describe the operationwise attention layer (Sec.3.1) and then explain the feature extraction block and the output layer (Sec.3.2).
Figure 1. Overview of the operation-wise attention network. It consists of a feature extraction block, a stack of operation-wise attention layers, and an output layer.

图 1 的 overview 可看出,该操作注意网络包括三个部分:特征提取模块;操作注意力层;输出层。
Operation-wise Attention Layer
- Overview
The operation-wise attention layer consists of an operation layer and an attention layer; see Fig.2. The operation layer contains multiple parallel operations, such as convolution and average pooling with different parameters. The attention layer takes the feature map generated by the previous layer as inputs and computes attention weights on the parallel outputs of the operation layer. The operation outputs are multiplied with their attention weights and then concatenated to form the output of this layer. We intend this attention mechanism to work as a selector of the operations depending on the input.
Figure 2. Architecture of the operation-wise attention layer. It consists of an attention layer, an operation layer, a concatenation operation, and 1 × 1 convolution. Attention weights over operations of each layer are generated at the first layer in a group of consecutive k layers. Note that different attention weights are generated for each layer.
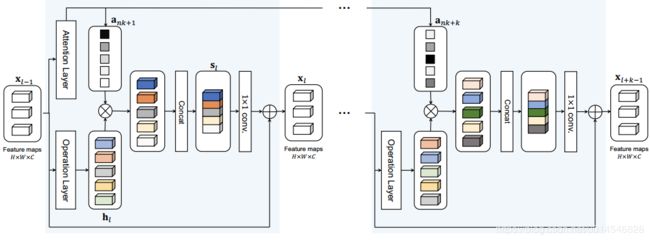
操作注意力层包括两个部分:操作层和注意力层。
操作层包含多个并行操作,比如不同参数的卷积、平均池等。
注意层将前一层生成的特征图作为输入,计算对操作层并行输出的注意权值。
操作输出与它们的注意力权重相乘,然后连接起来形成这一层的输出。
这个注意机制能够根据输入作为操作的选择器。
- Operation-wise Attention
We denote the output of the
-th operation-wise attention layer by
, where H, W, and C are its height, width, and the number of channels, respectively. The input to the first layer in the stack of operationwise attention layers, denoted by
, is the output of the feature extraction block connecting to the stack. Let
be a set of operations contained in the operation layer; we use the same set for any layer
, we calculate the attended value
on an operation o(·) in
where
is a mapping realized by the attention layer, which is given by
where
and
are learnable weight matrices; σ(·) denotes a ReLU function; and
is a vector containing the channel-wise averages of the input
as
Thus, we use the channel-wise average
to generate attention weights
instead of using full feature maps, which is computationally expensive.

这段公式挺多。但其实很简单。
公式(3)就是全局平均池化,将每个通道聚合成一个点;公式(2)![]() 相当于感知器;公式(1)是 softmax。对于给定的 , 每个注意力模块基本就是 SENet 。但图 2 中的注意力层(Attention Layer)用的是多个 SENet,为什么呢?
相当于感知器;公式(1)是 softmax。对于给定的 , 每个注意力模块基本就是 SENet 。但图 2 中的注意力层(Attention Layer)用的是多个 SENet,为什么呢?
We found in our preliminary experiments that it makes training more stable to generate attention weights in the first layer of every few layers rather than to generate and use attention weights within each individual layer. (By layer, we mean operation-wise attention layer here.) To be specific, we compute the attention weights to be used in a group of k consecutive layers at the first layer of the group; see Fig.2.
Letting
for a non-negative integer n, we compute attention weights
, . . . ,
at the
这是因为,初步实验发现在,对第一层中生成的注意力权重比在每一层中生成和使用注意力权重更稳定。(这里的层,指的是 操作注意力层,不是卷积层哦。)这句话的意思是,看图 2,attention layer 只用过一次,后面几个 操作注意力并没有再用 attention layer 了。具体使用时,是在 attention layer 模块中,是一组 SENet(公式 (1)-(3)),一共  个,对于给定的输入
个,对于给定的输入 ![]() ,直接采用 个注意力向量
,直接采用 个注意力向量 ![]() , . . . ,
, . . . , ![]() 。
。
We multiply the outputs of the multiple operations with the attention weights computed as above. Let
be the
-th operation and
be its output for
. We multiply
’s with the attention weights
The output of the
where
denotes a 1 × 1 convolution operation with C filters. This operation makes activation of different channels interact with each other and adjusts the number of channels. We employ a skip connection between the input and the output of each operation-wise attention layer, as shown in Fig. 2.
后面这几段内容就是讲,如何将 attention 和 operation 之间进行组合。方法是:将计算的 channel attention ![]() (长度为
(长度为 ![]() , 即操作的个数) 与操作相乘,然后将它们级联(公式(4)),最后再进行残差连接。
, 即操作的个数) 与操作相乘,然后将它们级联(公式(4)),最后再进行残差连接。
Operation Layer
Considering the design of recent successful CNN models, we select 8 popular operations for the operation layer: separable convolutions [4] with filter sizes 1 × 1, 3 × 3, 5 × 5, 7 × 7, dilated separable convolutions with filter sizes 3 × 3, 5 × 5, 7 × 7 all with dilation rate = 2, and average pooling with a 3 × 3 receptive field. All convolution operations use C = 16 filters with stride = 1, which is followed by a ReLU. Also, we zero-pad the input feature maps computed in each operation not to change the sizes of its input and output. As shown in Fig.3, the operations are performed in parallel, and they are concatenated in the channel dimension as mentioned above.
Figure 3. An example of the operation layer in the operation-wise attention layer.

操作层,就是通过不同的卷积、池化等操作得到不同的特征表示。每帧操作得到的特征通道都是 16。
具体操作包括:
4 个可分离卷积,卷积核分别为 1 × 1, 3 × 3, 5 × 5, 7 × 7;
3 个膨胀卷积,卷积核大小为 3 × 3, 5 × 5, 7 × 7, dilation rate = 2;
平均池化,核大小为 3 × 3。
Feature Extraction Block and Output Layer
For the feature extraction block, we use a stack of standard residual blocks, specifically, K residual blocks (K = 4 in our experiments), in which each residual block has two convolution layers with 16 filters of size 3×3 followed by a ReLU. This block extracts features from a (distorted) input image and passes them to the operation-wise attention layer stack.
For the output layer, we use a single convolution layer with kernel size 3 × 3. The number of filters (i.e., output channels) is one if the input/output is a gray-scale image and three if it is a color image.
特征提取层采用标准残差 block (用了 4 个)。
输出层采用一个 3 × 3 卷积。
Experimental Configuration
1. 全文采用 L1 损失函数。
2. 数据集:
DIV2K dataset containing 800 high-quality, large-scale images. The 800 images are divided into two parts: (1) the first 750 images for training and (2) the remaining 50 images for testing. Then 63 × 63 pixel patches are cropped from these images, yielding a training set and a testing set consisting of 249, 344 and 3, 584 patches, respectively.
They then apply multiple types of distortion to these patches. Specifically, a sequence of Gaussian blur, Gaussian noise and JPEG compression is added to the training and testing images with different degradation levels. The standard deviations of Gaussian blur and Gaussian noise are randomly chosen from the range of [0, 5] and [0, 50], respectively. The quality of JPEG compression is randomly chosen from the range of [10, 100]. The resulting images are divided into three categories based on the applied degradation levels; mild, moderate, and severe (examples of the images are shown at the first row of Fig.4). The training are performed using only images of the moderate class, and testing are conducted on all three classes.
数据集采用 pair 策略。先从 DIV2K Dataset 得到干净图像的 patches,249, 344 个训练样本,和 3, 584 测试样本。
然后对这些干净的 patches 做 Gaussian blur, Gaussian noise and JPEG compression 这三种降质。