解析BERT
什么是BERT?
BERT是Transformer的双向编码器表示的缩写。它是由Google在2018年末开发和发布的一种新型语言模型。像BERT这样的预训练语言模型在许多自然语言处理任务中发挥着重要作用,例如问答,命名实体识别,自然语言推理,文本分类等等
BERT是一种基于微调的多层双向变压器编码器。此时,介绍Transformer架构非常重要。
什么是变压器?
2017年,谷歌发表了一篇题为“注意力都是你需要的”的论文,该论文提出了一种基于注意力的结构来处理与序列模型相关的问题,例如机器翻译。传统的神经机器翻译大多使用RNN或CNN作为编码器 - 解码器的模型库。然而,谷歌的基于注意力的变形金刚模型放弃了传统的RNN和CNN公式。该模型高度并行运行,因此在提高翻译性能的同时,培训速度也非常快。
让我们退后一步,理解注意力。
什么是注意力?
注意机制可以看作是模糊记忆的一种形式。内存由模型的隐藏状态组成,模型选择从内存中检索内容。在我们深入了解Attention之前,让我们简要回顾一下Seq2Seq模型。传统的机器翻译基本上是基于Seq2Seq模型。该模型分为编码器层和解码器层,并由RNN或RNN变体(LSTM,GRU等)组成。编码器矢量是从模型的编码器部分产生的最终隐藏状态。该向量旨在封装所有输入元素的信息,以帮助解码器进行准确的预测。它充当模型的解码器部分的初始隐藏状态。Seq2Seq模型的主要瓶颈是需要将源序列的全部内容压缩为固定大小的矢量。如果文本稍长,则很容易丢失文本的某些信息。为了解决这个问题,注意力应运而生。注意机制通过允许解码器回顾源序列隐藏状态,然后将其加权平均值作为附加输入提供给解码器来缓解该问题。使用Attention,顾名思义,模型在解码阶段选择最适合当前节点的上下文作为输入。注意与传统的Seq2Seq模型有两个主要区别。首先,编码器向解码器提供更多数据,编码器将所有节点的隐藏状态提供给解码器,
https://jalammar.github.io/images/seq2seq_7.mp4
其次,解码器不直接使用所有编码器提供的隐藏状态作为输入,而是采用选择机制来选择与当前位置最匹配的隐藏状态。为此,它尝试通过计算每个隐藏状态的得分值并对得分进行softmax计算来确定哪个隐藏状态与当前节点最密切相关,这允许隐藏状态的更高相关性具有更大小数值,不太相关的隐藏状态具有较低的小数值。然后它将每个隐藏状态乘以其softmaxed得分,从而放大具有高分数的隐藏状态,并淹没具有低分数的隐藏状态。该评分练习在解码器侧的每个时间步骤完成。
https://jalammar.github.io/images/attention_process.mp4
现在让我们在下面的可视化中将整个事物放在一起,看看注意过程是如何工作的:
- 注意解码器RNN接收令牌的嵌入和初始解码器隐藏状态。
- RNN处理其输入,产生输出和新的隐藏状态向量(h4)。输出被丢弃。
- 注意步骤:我们使用编码器隐藏状态和h4向量来计算该时间步长的上下文向量(C4)。
- 我们将h4和C4连接成一个向量。
- 我们通过前馈神经网络(与模型共同训练的一个)传递此向量。
- 前馈神经网络的输出指示该时间步长的输出字。
- 重复下一步的步骤
https://jalammar.github.io/images/attention_tensor_dance.mp4
回到transformer
变压器模型使用编码器 - 解码器架构。在Google发表的论文中,编码器层由6个编码器堆叠,解码器层相同。每个编码器和解码器的内部结构如下 -
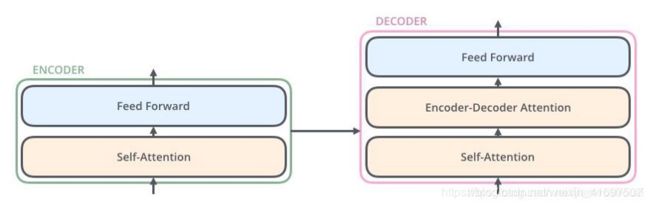
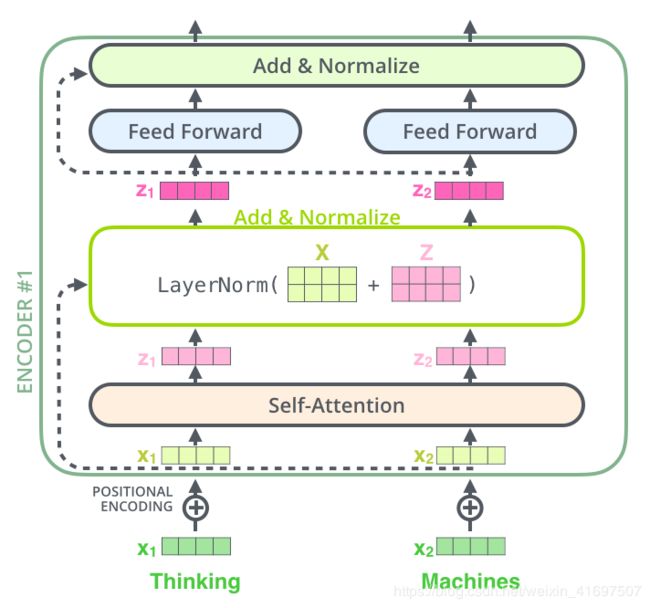
编码器由两层组成,一个自注意层和一个前馈神经网络。自我关注有助于当前节点不仅关注当前单词,而且还获得上下文的语义。解码器还包含编码器提到的双层网络,但在两层中间还有一个关注层,以帮助当前节点获得需要注意的关键内容。
以下是Transformer架构的详细结构 -
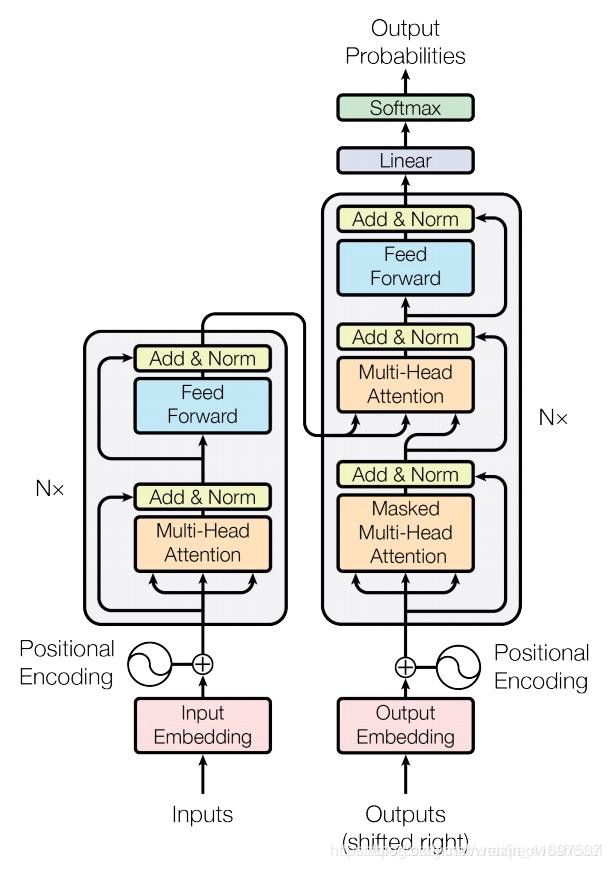
让我们分解各个组件。
自我关注
自我关注是Transformer将其他相关单词的“理解”转换为我们正在处理的单词的一种方式。
首先,自我关注计算三个新的向量。在论文中,向量的维度是512维。我们分别将这三个向量称为Query,Key和Value。这三个向量是通过将字嵌入向量与随机初始化矩阵(文中的维数为(64,512))相乘而产生的,其值在反向传播过程中被更新。
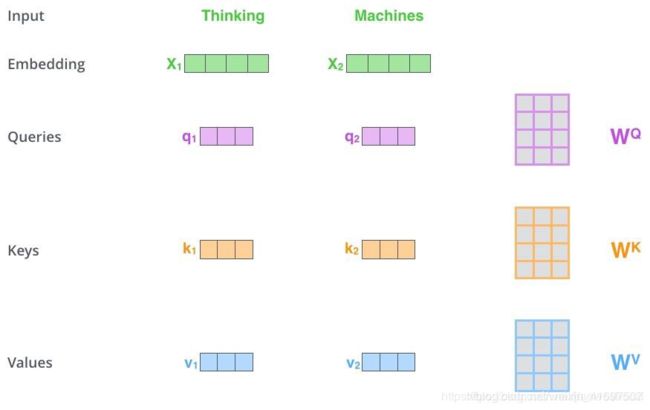
接下来,我们计算自我关注的分数值,它确定当我们在某个位置编码单词时对输入句子的其余部分的注意力。该小数值的计算方法使用Query和Key向量。然后我们将结果除以常数。这里我们除以8.这个值通常是上面提到的矩阵的第一维的平方根,也就是64的平方根8.然后我们对所有得分进行softmax计算。结果是每个单词与当前位置的单词的相关性。当然,当前位置的相关性一词肯定会很大。最后一步是将Value向量与softmax结果相乘并添加它们。结果是当前节点处的自我关注的价值。

这种通过查询和密钥之间的相似度来确定值的权重分布的方法被称为缩放的点积注意。
多头注意力
本文中更强大的部分是增加了另一种自我关注机制,称为“多头”关注,它不仅仅初始化了一组Q,K,V矩阵。相反,初始化多个组,变换器使用8个组,因此最终结果是8个矩阵。
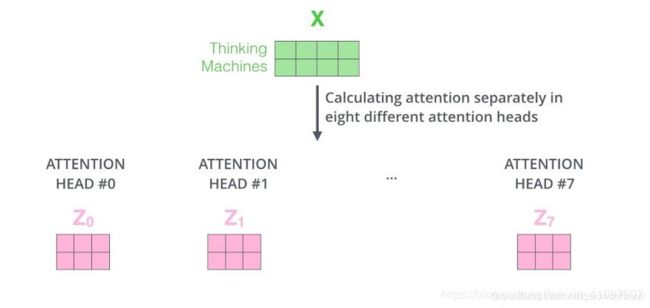
前馈神经网络不能接受8个矩阵,因此我们需要一种方法将8个矩阵减少到1.为此,我们首先将8个矩阵连接在一起得到一个大矩阵,然后将这个组合矩阵与一个随机初始化矩阵相乘得到最后的矩阵。让我们来看看整个过程。

Transformer以三种不同的方式使用多头注意力:
在“编码器 - 解码器关注”层中,查询来自先前的解码器层,并且存储器键和值来自编码器的输出。这允许解码器中的每个位置都参与输入序列中的所有位置。这模拟了序列到序列模型中典型的编码器 - 解码器注意机制。
编码器包含自我关注层。在自我关注层中,所有键,值和查询来自相同的位置,在这种情况下,是编码器中前一层的输出。编码器中的每个位置都可以处理编码器前一层中的所有位置。
类似地,解码器中的自注意层允许解码器中的每个位置参与解码器中的所有位置直到并包括该位置。我们需要防止解码器中的向左信息流以保持自回归属性。我们通过屏蔽(设置为-∞)softmax输入中与非法连接相对应的所有值来实现缩放点产品注意内部。这将在解码器部分中更详细地探讨,我们将讨论掩蔽。
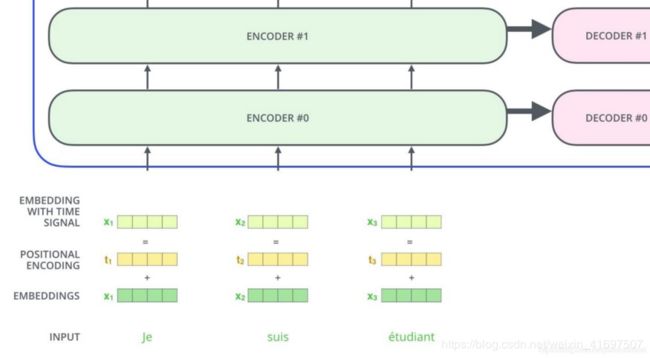
位置编码
到目前为止,我们没有办法解释变换器模型中输入序列中的单词顺序。为了解决这个问题,变换器在编码器和解码器层的输入端增加了一个额外的矢量位置编码。尺寸与嵌入尺寸相同。此位置编码的值将添加到嵌入值中,并作为输入发送到下一层。有许多位置编码选项,包括学习和修复。
残差连接和图层规范化
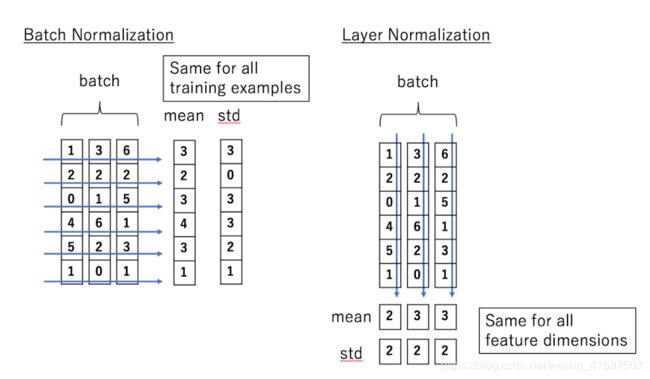
在编码器和解码器中,在两个子层中的每一个周围采用残余连接,然后进行层标准化。跳过连接或剩余连接用于允许梯度直接流过网络,而不通过非线性激活功能。非线性激活函数本质上是非线性的,导致梯度爆炸或消失(取决于权重)。从概念上说,跳过连接形成一条“总线”,它在网络中流动,反过来,梯度也可以沿着它向后流动。标准化有助于解决称为内部协变量偏移的问题。内部协变量移位是指在神经网络中发生的协变量移位,即从(例如)第2层到第3层。这是因为,当网络学习并且权重被更新时,网络中特定层的输出分布发生变化。这迫使较高层适应该漂移,这减慢了学习速度。在对神经网络中的输入进行归一化后,我们不必担心输入特征的规模差别很大。要了解图层规范化,将其与批量标准化进行对比非常有用。小批量包含具有相同数量功能的多个示例。小批量是矩阵 - 如果每个输入是多维的,则为张量 - 其中一个轴对应于批次,另一个轴 - 或轴 - 对应于特征尺寸。批量标准化规范化批次维度中的输入要素。图层规范化的关键特性是它可以对要素之间的输入进行标准化。在批量标准化中,统计数据是在批次中计算的,并且对于批次中的每个示例都是相同的。相反,在层规范化中,统计数据是跨每个特征计算的,并且与其他示例无关。
将剩余连接和层规范化结合在一起。
解码器
回到Transformer体系结构图,我们可以看到解码器部分类似于编码器部分,但底部有一个掩盖的多头注意。Mask表示屏蔽某些值的掩码,以便在更新参数时它们不起作用。Transformer模型中有两种掩码 - 填充掩码和序列掩码。填充掩码用于所有缩放的点积注意,并且序列掩码仅用于解码器的自我注意。
填充掩码解决了输入序列具有可变长度的问题。具体来说,我们在较短的序列后填0。但是如果输入序列太长,则会截取左侧的内容,并直接丢弃多余的内容。因为这些填充的位置实际上没有意义,我们的注意机制不应该集中在这些位置,所以我们需要做一些处理。具体方法是在这些位置的值上加一个非常大的负数(负无穷大),这样这些位置的概率在softmax之后将接近0!填充掩码实际上是一个张量,每个值都是一个布尔值,false值是我们想要处理的值。
序列掩码旨在确保解码器无法查看将来的信息。也就是说,对于序列,在time_step t,我们的解码输出应该仅取决于t之前的输出,而不取决于t之后的输出。这特定于Transformer架构,因为我们没有RNN,我们可以按顺序输入序列。在这里,我们一起输入所有内容,如果没有掩码,多头注意力将考虑每个位置的整个解码器输入序列。我们通过生成上三角矩阵来实现这一点,上三角形的值全为零,并将该矩阵应用于每个序列。
为了解码器的自我关注,使用缩放的点积注意,并且添加填充掩码和序列掩码作为attn_mask。在其他情况下,attn_mask等于填充掩码。
另一个细节是解码器输入将向右移动一个位置。这样做的一个原因是我们不希望我们的模型在训练期间学习如何复制我们的解码器输入,但我们想要了解给定编码器序列和模型已经看到的特定解码器序列,预测下一个单词/字符。如果我们不移位解码器序列,则模型学习简单地“复制”解码器输入,因为位置i的目标字/字符将是解码器输入中的字/字符i。因此,通过将解码器输入移位一个位置,我们的模型需要预测仅看到单词/字符1,…,i-1的位置i的目标字/字符在解码器序列中。这可以防止我们的模型学习复制/粘贴任务。我们用句子开头令牌填充解码器输入的第一个位置,因为由于右移,该位置将是空的。类似地,我们将一个句末结尾标记附加到解码器输入序列以标记该序列的结尾,并且它还附加到目标输出语句。
输出层
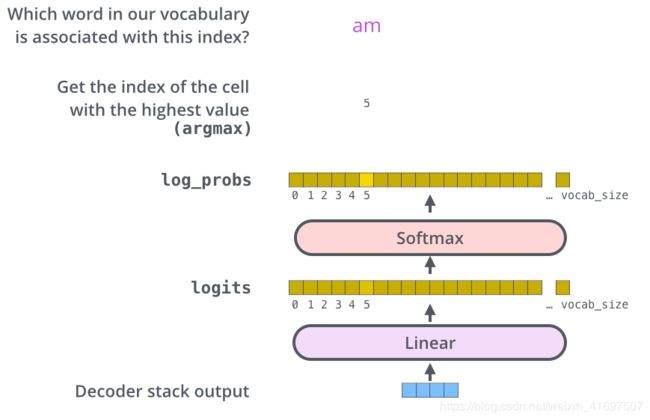
在完全执行解码器层之后,为了将得到的矢量映射到来自词汇表的单词,最后添加全连接层和
softmax层。
线性层是一个简单的完全连接的神经网络,它将解码器堆栈产生的矢量投影到一个更大,更大的矢量中,称为logits矢量。让我们假设我们的模型知道从训练数据集中学到的10,000个独特的英语单词(我们的模型的“输出词汇表”)。这将使logits矢量10,000个细胞宽 - 每个细胞对应于一个唯一单词的得分。这就是我们如何解释模型的输出,然后是线性层。然后,softmax层将这些分数转换为概率(所有正数,所有加起来都为1.0)。选择具有最高概率的单元,并且将与其相关联的单词作为该时间步的输出。
回到BERT
BERT基于Transformer架构。它是一种深度,双向深度神经网络模型。Google最初发布了两个版本,如下图所示。这里L表示变压器的层数,H表示输出的维数,A表示多头注意的数量。在这两个版本中,前馈大小设置为4层。
BERTBASE:L = 12,H = 768,A = 12,总参数= 110M
BERTLARGE:L = 24,H = 1024,A = 16,总参数= 340M
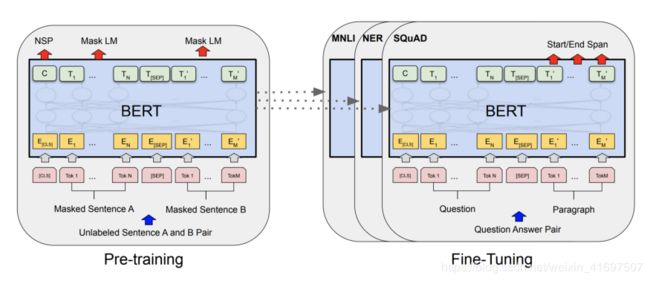
使用BERT有两个阶段:预训练和微调。在预训练期间,模型在不同的预训练任务上训练未标记的数据。对于微调,首先使用预先训练的参数初始化BERT模型,并使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的微调模型,即使它们使用相同的预先训练的参数进行初始化。BERT的一个显着特点是它跨越不同任务的统一架构。预训练架构与最终下游架构之间的差异很小。在微调期间,所有参数都经过微调。
BERT训练前流程
BERT预训练阶段包括两个无监督预测任务,一个是掩蔽语言模型,另一个是下一句预测。
蒙面语言模型 - 由于双向功能(双向性)和BERT使用的多层自我关注机制的效果,为了训练深度双向表示,一些百分比(本文中为15%)输入令牌的输入被简单地随机掩盖,然后预测那些被屏蔽的令牌。对应于掩模标记的最终隐藏向量被馈送到词汇表上的输出softmax,如在标准LM中。与从左到右的语言模型预训练不同,MLM目标允许表示融合的左侧和右侧的上下文,这使得可以预先训练深度双向变换器。虽然这允许获得双向预训练模型,但缺点是预训练和微调之间存在不匹配,因为在微调期间不会出现[MASK]标记。为了缓解这种情况,作者并不总是用实际的[MASK]令牌替换“蒙面”单词。训练数据生成器随机选择15%的令牌位置进行预测。如果选择了第i个令牌,则将其替换为(1)[MASK]令牌80%的时间(2)随机令牌10%的时间(3)未更改的第i个令牌10%时间。
下一句话预测 - 。为了训练理解句子关系以及单词之间的语义关系的模型,BERT还预先训练二进制化的下一句预测任务,该任务可以从任何文本语料库中非常容易地生成。为A和B选择一些句子,其中50%的数据B是A的下一个句子,剩余的50%的数据B是在语料库中随机选择的,并学习相关性。添加这种预训练的目的是许多NLP任务(如QA和NLI)需要理解两个句子之间的关系,以便预训练模型能够更好地适应这些任务。
标记化 - BERT不会将单词视为标记。相反,它看着WordPieces。这意味着一个单词可以分解为多个子单词。这种标记化在处理词汇单词时是有益的,它可以帮助更好地表示复杂的单词。
BERT模型输入
BERT的输入可以是单词序列中的单个句子或句子对(例如,[问题,答案])。对于给定的单词,其输入表示可以由三部分嵌入求和组成。嵌入的可视化表示如下所示:

令牌嵌入表示单词向量。第一个字是CLS标志,可用于后续分类任务。对于非分类任务,可以忽略CLS标志。段嵌入用于区分两个句子,因为预训练不仅是语言模型,而且是具有两个句子作为输入的分类任务。位置嵌入编码字顺序。
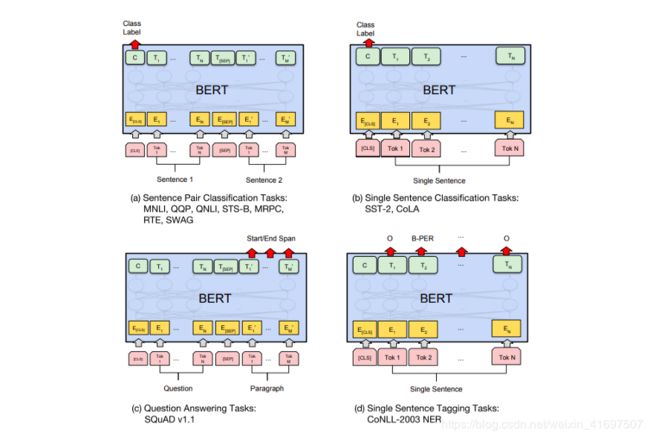
用于下游NLP任务的BERT微调
对于每个下游NLP任务,我们只需将特定于任务的输入和输出插入BERT并对端到端的所有参数进行微调。在输入处,来自预训练的句子A和句子B可以类似于释义中的句子对,蕴涵中的假设前提对,问题回答中的问题 - 通道对等。在输出处,令牌表示被馈送到用于令牌级别任务的输出层,例如序列标记或问题回答,并且[CLS]表示被馈送到输出层以进行分类,例如蕴涵或情绪分析。与预训练相比,微调相对便宜。
BERT用于特征提取
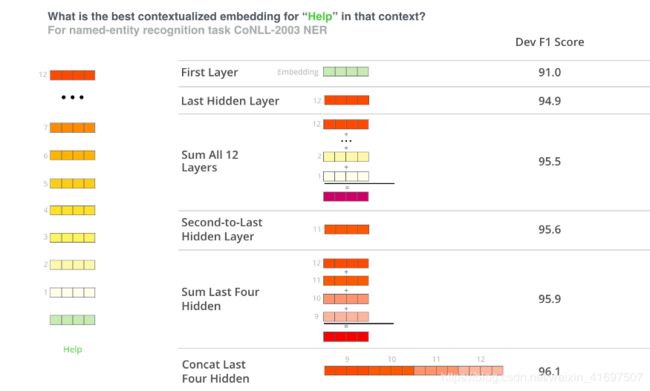
微调方法不是使用BERT的唯一方法。您可以使用预先训练的BERT创建语境化词嵌入。然后,您可以将这些嵌入提供给您现有的模型 - 这个过程本文显示了在命名实体识别等任务上微调BERT的产量结果。

哪个向量最适合作为上下文嵌入?这取决于任务。本文考察了六种选择(与得分为96.4的微调模型相比):