KDD2020 | 揭秘Facebook搜索中的语义检索技术

星标/置顶小屋,带你解锁
最萌最前沿的NLP、搜索与推荐技术
文 | 江城
编 | 可盐可甜兔子酱
导读:今天分享一下 Facebook 发表在 KDD2020 的一篇关于社交网络搜索中的 embedding 检索问题的工作,干货很多,推荐一读。

论文题目:
Embedding-based Retrieval in Facebook Search
论文链接:
https://arxiv.org/abs/2006.11632
Arxiv访问慢的小伙伴也可以在【夕小瑶的卖萌屋】订阅号后台回复关键词【0731】下载论文PDF~
相对于传统的网页搜索,社交网络中的搜索问题不仅需要关注输入 query 的信息,还需要考虑用户的上下文信息,在 Facebook 搜索场景中用户的社交图网络便是这种上下文信息中非常重要的一部分。
怎么把各式各样的信息进行融合呢?
虽然语义检索技术(Embedding-based Retrieval,EBR)在传统的搜索引擎中得到了广泛应用,但是 Facebook 搜索之前主要还是使用布尔匹配模型,本文就来谈谈如何将 Embedding 检索技术应用在 Facebook 搜索场景中。
文中共介绍了三方面的经验:
提出了一套统一的 embedding 框架用于建模个性化搜索中的语义
提出了基于经典的倒排索引进行在线 embedding 检索的系统
讨论了整个个性化搜索系统中很多端对端的优化技巧,例如最近邻搜索调参经验、全链路优化等
最后,在Facebook 垂直搜索场景下验证了本文方法的有效性,在线上 A/B 实验取得了显著的收益。
背景
从 query 中准确计算出用户的搜索意图以及准确表征文档的语义是非常困难的。之前的搜索算法主要还是通过关键词匹配的方式进行检索,但是对于字面不匹配但是语义相似的 case 基于关键词匹配的方法就不奏效了。而通过 embedding 可以建模句子之间的语义相似度,所以基于 embedding 的语义检索就应运而生了。
所谓 embedding 就是将高维稀疏的 id 映射成为一个低维稠密的向量,这样就可以在同一个向量空间中同时表示query 和候选集文档,从而进行譬如计算相似度等方面的操作。
一般来说,搜索主要包含检索和排序两个阶段。尽管 embedding 技术可以同时被应用在两个阶段,但相对来说应用在召回阶段可以发挥出更大的作用。简单来说,EBR 就是用 embedding 来表示 query 和 doc,然后将检索问题转化为一个在 Embedding 空间的最近邻搜索的问题。它要解决的问题是如何从千万个候选集中找到最相关的 topK 个,难点有如下的两个:一方面是如何构建千万级别的超大规模索引以及如何在线上进行服务;另一方面是如何在召回阶段同时考虑语义信息和关键词匹配信息。
本文从三个方面详细讲述了在 Facebook 搜索中应用 Embedding 检索技术遇到的挑战:
modeling: 本文提出了一套统一的 Embedding 模型框架 ,也就是经典的双塔结构,一侧是抽取用户侧 query 特征;另一侧则是抽取 document 侧的特征。
serving: 为了优化系统检索和排序的综合效果,Facebook 提出了将 EBR 的 embedding 作为特征整合进 ranking 模型中,以及创建了一套数据反馈机制,以便更好地识别和利用 EBR 的召回结果。
full-stack optimization: 针对实际的搜索效果优化提出了多个实用的 tricks。
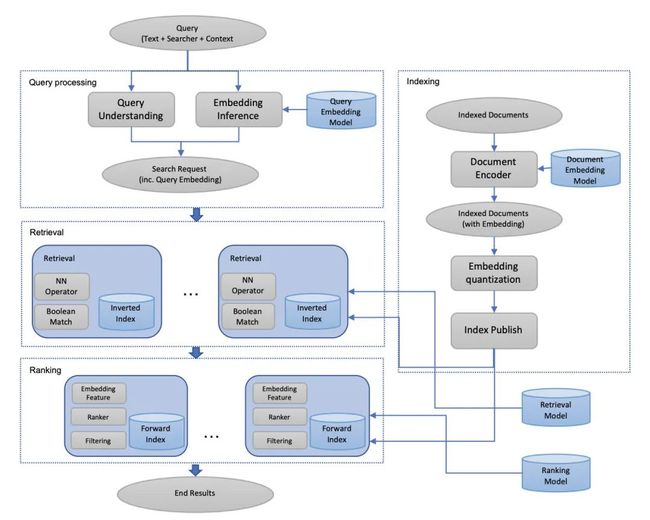
系统建模
本文将搜索引擎中的检索任务建模为一个召回优化问题。从离线指标的角度,我们希望最大化 topK 返回结果的recall 指标。给定一个 query,以及期望被检索到的目标文档集合 T,T 中包含的文档可以来自用户的点击数据,也可以是经过人工筛选排序后的文档,我们的优化目标则是 recall@K。
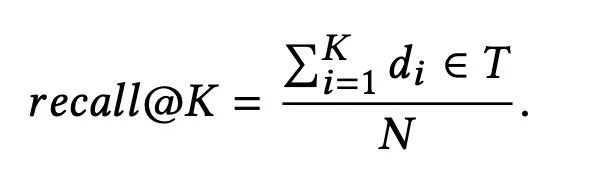
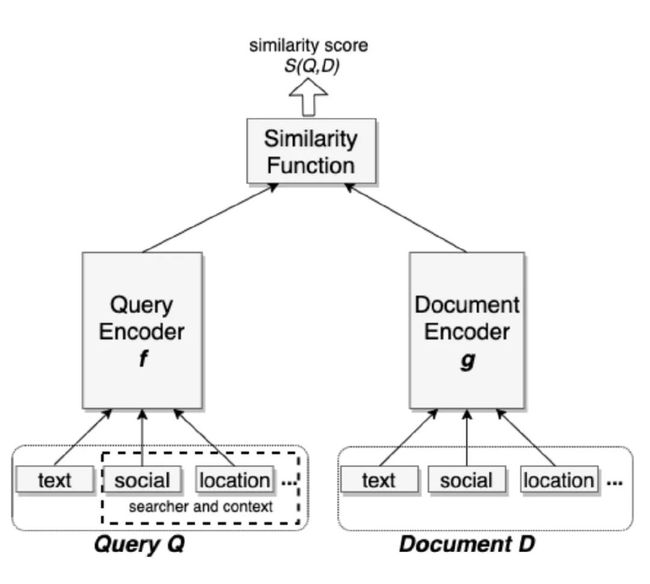
继而我们把召回优化问题建模成 query 和 doc 之间基于距离的排序问题,把 query 和 doc 同时表示成低维稠密的向量,通过计算向量空间中的距离衡量它们之间的相似度或相关度,本文中我们采用 cosine 距离。
但是在 Facebook 个性化检索场景下,仅仅计算 query 本身与候选文档的相似性是远远不够的,我们同时要考虑用户的上下文信息,比如他关注的人,他的关注话题等等,才能帮用户找到他真实的最想要的结果。为了实现这个目标,本文提出了统一嵌入模型,即Unified Embedding Model。Unified Embedding Model的思路相对来说比较简单,沿用了经典的双塔结构,包括三个部分:query encoder,document encoder 以及 similarity function。两个encoder是互相独立的,也可以共享一部分网络参数,左边是 user 的塔;右边是 document 的塔,但是 Unified Embedding Model 的 encoder 的输入是和传统的输入不同的,user 塔的输入包括用户的检索 query,以及用户位置、用户社交关系等上下文特征,document 塔的输入包括文档本身,以及文档的 group 信息等上下文特征,模型结构详见下图所示。其中大部分的特征都是类别型特征,进行 one-hot 或者 multi-hot 的向量化;连续型特征则是直接输入到各自的塔中。
在模型训练的损失函数上,本文定义了一个三元组损失函数,使得负例比正例相对 query 的距离尽可能的远。在使用三元组损失函数的情况下,使用随机采样的负样本可以近似求解召回优化问题。
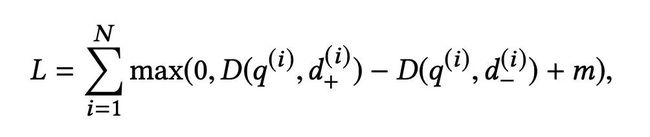
对于训练 embedding 语义召回模型来说,如何定义正负样本对于模型的效果至关重要。点击样本作为正样本这个没有疑问,针对负样本我们采用了如下的两种的策略进行试验。
随机负样本:随机从文档库中采样 document 作为负样本;
曝光但未点击样本:随机采样在同一个 session 中曝光但未点击的样本作为负样本;
本文发现前者作为负样本的效果要明显好于后者,原因是前者可以有效消除负样本偏差。另外,本文还进行了一组把曝光但是未点击的样本作为正样本的实验,实验结果表明并没有带来额外的收益。
特征工程
Unified Embedding Model 架构的一个最明显的优势是可以任意加入各种各样的上下文特征。我们都知道 Facebook 推出的工业界实战论文都比较注重特征工程,Unified Embedding 大体上采用了如下三个方面的特征:
Text features
Text Embedding 采用 char n-gram,相对于 word n-gram 有两方面的优势,一是有限的词典,char embedding table 会比较小,训练更高效;二是不会有 OOV 问题,subword 可以有效解决拼写错误以及单词的多种变体引入的 OOV 问题。
Location features
位置特征对于搜索引擎的很多场景是非常重要的,因此本文在 query 和 document 侧的都加入了 location 的特征。
Social Embedding features
为了有效利用 Facebook 社交网络中的丰富信息,本文额外地训练了一个社交网络的 Graph Embedding,然后将这个预训练的 Embedding 作为特征输入到模型当中。

在线Serving
前面的章节讲如何进行离线建模以及特征工程,这一节主要讲如何进行在线实时检索,Facebook 采用了自家的 Faiss 库进行线上近似最近邻搜索(approximate nearest neighbor search, ANN)。具体地,他们在实际系统中部署了一套基于倒排索引的 ANN 搜索算法,首先,利用自家的 Faiss 库创建向量索引,然后对索引表进行高效的最近邻检索。对 embedding 进行量化可以有效节省存储开销,同时可以方便地集成到现有的检索系统当中。
一个 query 可以表示为基于 term 的布尔表达式,譬如 john 和 smithe 住在 seattle 或者 menlo_park 可以用下面的布尔表达式来表示。在实际使用中,在 document 的布尔表示基础上,加上了 document embedding 的索引。

Embedding model 离线训练完成后通过 spark 构建候选文档集 document 的索引,当用户请求过来时,query 的 embedding 在线计算,进行 topK 召回。针对全量的候选文档集进行索引是非常耗存储和费时的,所以本文在构建索引的时候,只选择了月活用户,近期事件,热门的事件,以及热门 group。大部分公司在构建索引的时候也都会采取这样的策略,很多长时间不活跃的可以不构建索引。
Full-stack优化
Facebook 的搜索引擎可以看作是一个复杂的多阶段的排序系统,检索是排序之前的流程,检索得到的结果需要经过排序层的过滤和 ranking,我们可以将检索过程召回的分数(也就是向量的相似度)作为 ranking 阶段的一个特征,通过 ranking 模型进行统一排序。由于现有的排序算法是基于已有的检索算法的特点设计的,所以对于基于 embedding 召回的结果自然是被次优处理的,为了解决这个问题,作者提出了两个方法:
Embedding as ranking feature: 将检索这一步骤得到的 embedding similarity 作为接下来排序的输入特征,实验证明余弦相似度的效果要优于其他相似度特征。
Training data feedback loop: 基于 embedding 的语义召回的结果存在召回高但是精度低的问题,所以本文就采用了对召回结果进行人工标注的方法,对每个query召回的结果进行标注,区分相关结果和不相关结果,然后用标注后的数据重新训练模型,从而提升模型精度。(人工大法好)
基于 embedding 的语义召回模型需要更加深入的分析才能不断提升性能,Facebook 给出了其中可以提升的重要方向一个是 Hard Mining,另一个是 Embedding Ensemble。具体地有以下几个方法:
Hard Negative Mining 文章发现很多时候同语义召回的结果,大部分都是相似的,而且没有区分度,最相似的结果往往还排不到前面,这些就是之前的训练样本太简单了,导致模型学习的不够充分。所以本文把那些和 positive sample 很近的样本作为负样本去训练,这样模型就能学到这种困难样本的区分信息。
Online hard negative mining 模型是采用mini-batch的方式进行参数更新的,对batch中每个positive pair (q_i, d_i),利用除 d_i 以外的其他正例文档组成一个文档集,从中选择最相近的文档作为困难负例 hard negative sample,通过这种方式构造的三元组数据 可以使模型效果提升非常明显,同时也注意到了每个 positive pair,最多只能有两个 hard negative sample,不然模型的效果会下降。
Offline hard negative mining 首先针对每个 query 召回 topK 个结果;然后选择一些 hard negative samples 进行重新训练,重复整个过程。同时根据经验负例样本的比例是 easy : hard=100:1。
Hard positive mining 模型采用了用户点击的样本为正样本,这一部分样本是现有系统已经可以召回的相对简单样本,但是还有一些用户未点击但是也能被认为是正样本的样本。作者从用户日志中挖掘出潜在的困难正样本(具体如何挖掘文章没有提及),发现训练数据量只有原来 4% 的情况下可以得到和原来相近的召回率,如果把这些困难正例和用户点击数据一起训练说不定有更好的效果。
Embedding Ensemble 简单样本和困难样本对训练 EBR 模型都很重要,简单样本可以让模型快速学习到数据分布特点,困难样本可以提升模型的 precision,所以采用不同难度的正负样本训练出来的模型各有优势,如何对这些模型进行融合以提升性能呢?第一种方案是 Weighted Concatenation,通过对不同模型计算的相似度 score 进行加权平均作为最终相似度值,采用加权融合的模型对于单模型而言有 4.39% 的提升。第二种方案是 Cascade Mode,模型以串行方式在第一阶段模型的输出上运行第二阶段模型。采用串行的方式,模型也有 3.4% 的提升。
总得来说,这是一篇浓浓工业风的文章,虽然没有特别fancy的方法,但是系统级的优化方案上很值得大家学习。
文末福利
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
有顶会审稿人、大厂研究员、知乎大V和妹纸
等你来撩哦~
关注星标
带你解锁最前沿的NLP、搜索与推荐技术
参考文献
[1] Embedding-based Retrieval in Facebook Search
[2] https://zhuanlan.zhihu.com/p/152570715
