离线数据系统之Hive原理及部署
一、Hive基本概念
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
1.1、Hive的特点
- 可扩展 -- Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性 -- Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 容错 -- 良好的容错性,节点出现问题SQL仍可完成执行。
1.2、 Hive架构

Jobtracker是hadoop1.x中的组件,它的功能相当于: Resourcemanager+AppMaster
TaskTracker 相当于: Nodemanager + yarnchild
基本组成
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql , derby中。
- 解释器、编译器、优化器、执行器。
各组件的基本功能
- 用户接口主要由三个:CLI、JDBC/ODBC和WebGUI。其中,CLI为shell命令行(最常用),CLI启动的时候,会同时启动一个Hive副本。JDBC/ODBC是Hive的JAVA的客户端实现,与传统数据库JDBC类似;做为Hive的客户端,用户连接至Hive Server;在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WebGUI是通过浏览器访问Hive。
- 元数据存储:Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
- Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。作为数据仓库,不支持对数据的增删改,只支持查询。
二、Hive原理
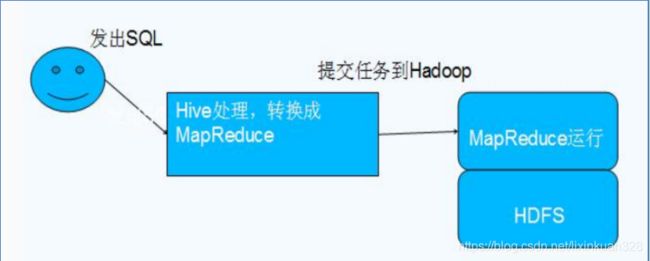
2.1、Hive与Hadoop的关系
Hive利用HDFS存储数据,利用MapReduce查询数据
运行原理:
- 编译器将一个Hive SQL转换操作符Operator
- 操作符Operator是Hive的最小的处理单元
- 每个操作符代表HDFS的一个操作或者一道MapReduce作业

Operator 操作符:
- Operator都是hive定义的一个处理过程
- Operator都定义有: protected List
2.2、Hive与传统数据库对比
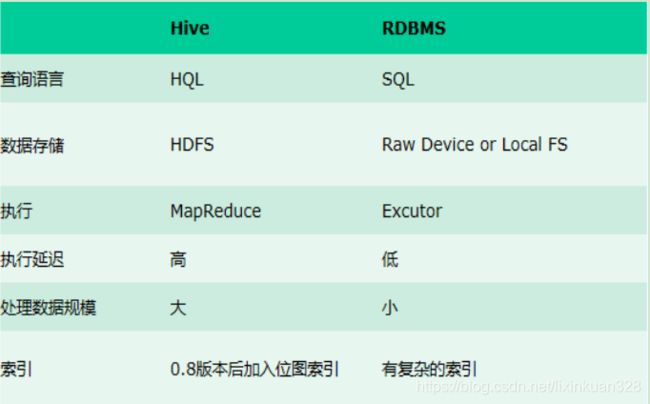
- 查询语言。由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
- 数据存储位置。Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
-
数据格式。Hive 中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive 中默认有三个文件格式 TextFile,SequenceFile 以及 RCFile)。由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的 HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定的组织存储,因此,数据库加载数据的过程会比较耗时。
- 数据更新。由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO ... VALUES 添加数据,使用 UPDATE ... SET 修改数据。
- 索引。之前已经说过,Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
- 执行。Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的,而数据库通常有自己的执行引擎。
- 执行延迟。之前提到,Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
- 可扩展性。由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
- 数据规模。由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
2.3、Hive的数据存储
1、Hive中的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text ,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
- db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
- table:在hdfs中表现所属db目录下一个文件夹
- external table:与table类似,不过其数据存放位置可以在任意指定路径
- partition:在hdfs中表现为table目录下的子目录
- bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
4、ANTLR词法语法分析工具解析hql :https://baike.baidu.com/item/antlr/9368750?fr=aladdin

三、HIVE的安装部署
Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景。(按照元数据存储方式)
3.1、内嵌模式
元数据保存在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错,一般用于Unit Test

这种方式是最简单的存储方式,只需要在hive-site.xml做如下配置便可
javax.jdo.option.ConnectionURL
jdbc:derby:;databaseName=metastore_db;create=true
javax.jdo.option.ConnectionDriverName
org.apache.derby.jdbc.EmbeddedDriver
hive.metastore.local
true
hive.metastore.warehouse.dir
/user/hive/warehouse
3.2、本地模式
多用户的模式,使用MySQL来存储元数据。连接之前无需知道数据库的密码。这种方式一般作为公司内部同时使用Hive。

配置环境变量:
- 修改~/share/hadoop/yarn/lib/jline-0.9.94.jar目录下的jline-*.jar 变成$HIVE_HOME\lib下的jline-2.12.jar。
- 拷贝mysql驱动包到$HIVE_HOME\lib目录下
- 修改hive-site.xml文件
hive.metastore.warehouse.dir
/usr/hive_remote/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://node02/hive_remote?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123
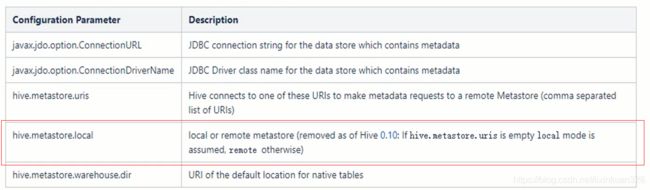

本地元存储和远程元存储的区别:本地元存储不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。远程元存储需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程元存储的metastore服务和hive运行在不同的进程里。
3.3、远程模式,即server模式
这种模式需要使用hive安装目录下提供的beeline+hiveserver2配合使用才可以。
其原理就是将metadata作为一个单独的服务进行启动。各种客户端通过beeline来连接,连接之前无需知道数据库的密码。

将hive-site.xml配置文件拆为如下两部分
1)、服务端配置文件
hive.metastore.warehouse.dir
/user/hive/warehouse
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.57.6:3306/hive?createDatabaseIfNotExist=true
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
123456
2)、客户端配置文件
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.metastore.local
false
hive.metastore.uris
thrift://192.168.57.5:9083
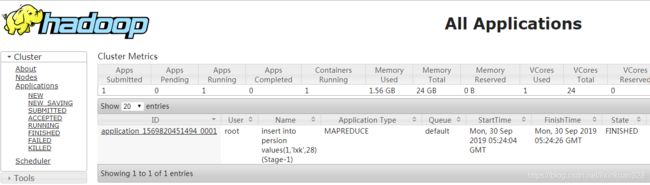
启动hive服务端程序: hive --service metastore (或者 hive --service metastore 2>&1 >> /dev/null & )
客户端直接使用hive命令即可
root@my188:~$ hive
Hive history file=/tmp/root/hive_job_log_root_201301301416_955801255.txt
hive> show tables;
OK
test_hive
Time taken: 0.736 seconds
hive> 客户端启动的时候要注意:[ERROR] Terminal initialization failed; falling back to unsupportedjava.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected at jline.TerminalFactory.create(TerminalFactory.java:101)错误的原因: Hadoop jline版本和hive的jline不一致
四、使用方式
4.1、本地metastore,直接通过hive命令启动
- 使用以下命令开启:$HIVE_HOME/bin/hive
- hive命令默认是启动client服务,相当于以下命令:$HIVE_HOME/bin/hive --service cli
- 也可以不进入命令行,直接执行脚本文件:hive -e ‘sql’
不需要启动server,使用本地的metastore,可以直接做一些简单的数据操作和测试。

4.3、使用远程的metastore
metastore可以和hive客户端不在一个机器上。
- 服务器1启动metastore服务(端口号默认9083): $HIVE_HOME/bin/hive --service metastore
- 也可以通过-p指定端口号:$HIVE_HOME/bin/hive --service metastore -p 9088
- 服务器2直接启动cli即可:$HIVE_HOME/bin/hive
同样不需要启动server,只需要启动元数据服务,即可使用远程的metastore
4.4、使用Hive thrift服务

远端启动方式,(假如是在服务器1上):
- 启动为前台:bin/hiveserver2
- 启动为后台:nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
- 启动成功后,可以在别的节点上用beeline去连接
方式(1)-- hive/bin/beeline 回车,进入beeline的命令界面
输入命令连接hiveserver2: beeline> !connect jdbc:hive2//mini1:10000
(mini1是hiveserver2所启动的那台服务器1,端口默认是10000)
方式(2)-- 或者启动就连接:bin/beeline -u jdbc:hive2://mini1:10000 -n hadoop
扩展:以前Hive Cli 服务器是HiveServer,而beeline Cli服务器是HiveServer2。HiveServer不能处理多个客户端的并发请求,所以产生了HiveServer2。但是,从hive1.0.0开始,HiveServer已经不存在了,从Hive代码中删除了,Hive Cli 也使用的是HiveServer2了,这对用户来说是透明的。(Hive社区一直建议使用Beeline + HiveServer2配置,由于Hive CLI的广泛使用,所以Hive CLI的实现已被替换)
方式(3)-- 使用客户端软件$HIVE_HOME/bin/hive --service hiveserver2
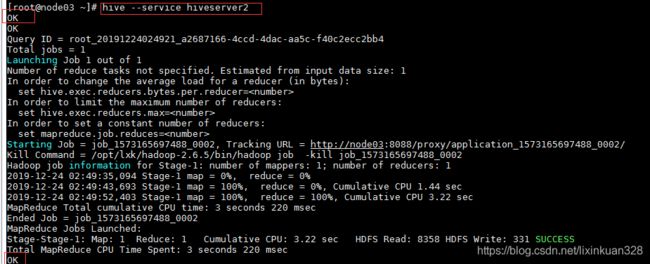
4.5、启动hiveWebInterface,通过网页访问hive
hive提供网页GUI来访问Hive数据仓库 ,可以通过以下命令启动hwi,默认端口号9999
$HIVE_HOME/bin/hive --service hwi
从Hive 2.2.0开始不再支持hwi,故此处不再赘述。
4.6、cli和beeline区别
hiveserver2 也可以用来访问元数据的,他和metastoreServer是访问元数据的二种不同服务。
- cli是通过metaServer访问元数据的:$HIVE_HOME/bin/hive --service metastore
- beeline是通过hiverserver2访问元数据的:$HIVE_HOME/bin/hive --service hiveserver2