关于树模型一些问题的思考--从决策树一直到XGB
首先是ID3,C4.5与CART树的区别:
1、分特征基点不同,以及对应造成的特性
:
前两者基于熵

条件熵
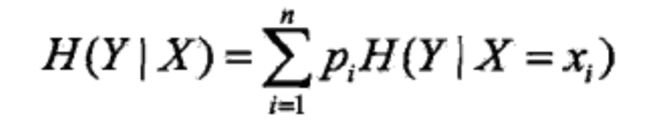
信息增益(ID3)
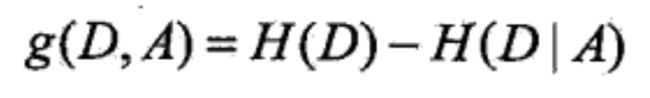
缺点:信息增益偏向取值较多的特征
原因:当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益比较 偏向取值较多的特征。
信息增益比(C4.5)
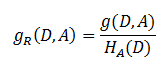

其中的 H A ( D ) H_A(D) HA(D),对于样本集合 D D D,将当前特征 A A A作为随机变量(取值是特征 A A A的各个特征值),求得的经验熵。
(之前是把集合类别作为随机变量,现在把某个特征作为随机变量,按照此特征的特征取值对集合 D D D进行划分,计算熵 H A ( D ) H_A(D) HA(D))
信息增益比本质: 是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。
这样的话避免这个 A A A本来就种类很多,像日期,身份证号这种特征可能直接把一个树分成每个节点只有一个样本的树,这时虽然熵可能是 0 0 0,但效果很差。信息增益比避免了这种情况
缺点:信息增益比偏向取值较少的特征
原因: 当特征取值较少时HA(D)的值较小,因此其倒数较大,因而信息增益比较大。因而偏向取值较少的特征。
使用信息增益比:基于以上缺点,并不是直接选择信息增益率最大的特征,而是现在候选特征中找出信息增益高于平均水平的特征,然后在这些特征中再选择信息增益率最高的特征。
CART树中分类树是基于基尼系数且是一个二叉树:
对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
CART回归树是基于MSE且是一个二叉树

2、特征分法不一样
前两者选择一个特征之后进行分割时要把这个特征完全分裂,即分出来的结点中每个子节点上面关于这个特征都是一样的;而CART树对于一个特征做分类时是做二分,对于分类树,因为背景要求就是每个特征只取2值,所以与前两者类似,但是回归树对一个特征二分后子节点中对于这个特征还是有可能有不同对样本,这个需要注意。
3、对特征分割的时候从损失函数与信息增益来看思想内在统一,很重要!
ID3与C4.5进行剪枝时其实是对损失函数做极小化,这个损失如果不看后面的正则项其实就是一个信息增益的变换:
考虑从最开始的单结点开始分:
损失: C α ( T ) = ∑ t ∣ T ∣ N t H t ( T ) + α ∣ T ∣ C_{\alpha}(T)=\sum_t^{|T|}N_tH_t(T)+\alpha|T| Cα(T)=∑t∣T∣NtHt(T)+α∣T∣
H ( T ) H(T) H(T)是节点 t t t上的熵,不是条件熵, N t N_t Nt是节点 t t t上样本个数(此时 T = 1 T=1 T=1)
去掉正则项后的分割过程:
C α 0 ( T ) = N H ( T ) ( N C_{\alpha}^0(T)=NH(T)(N Cα0(T)=NH(T)(N为样本数量)>>> C α 1 ( T ) = ∑ t ∣ T ∣ N t H t ( T ) C_{\alpha}^1(T)=\sum_t^{|T|}N_tH_t(T) Cα1(T)=∑t∣T∣NtHt(T)
考虑上下同除一个样本数量 N N N
得到: C α 0 ( T ) / N = H ( T ) C_{\alpha}^0(T)/N=H(T) Cα0(T)/N=H(T)>>> C α 1 ( T ) / N = ∑ t ∣ T ∣ ( N t / N ) ∗ H t ( T ) C_{\alpha}^1(T)/N=\sum_t^{|T|}(N_t/N)*H_t(T) Cα1(T)/N=∑t∣T∣(Nt/N)∗Ht(T)
**可以看到这其实就是熵的变化,所以其实要让不带正则损失减小最大,就是要选信息增益最大的特征。
这点比较重要的原因是因为GBDT和XGB就是根据损失函数来确定树结构的,可以看出一脉相承的思想
4、《统计学习方法》上有说对于损失函数 C α ( T ) = ∑ t ∣ T ∣ N t H t ( T ) + α ∣ T ∣ C_{\alpha}(T)=\sum_t^{|T|}N_tH_t(T)+\alpha|T| Cα(T)=∑t∣T∣NtHt(T)+α∣T∣的极小化等价于正则化的极大似然
首先正则化显而易见,如何理解极大似然呢?做如下的转化:
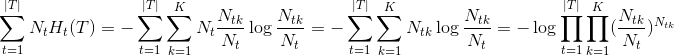
其中 N t N_{t} Nt为 t t t节点中样本数, N t k N_{tk} Ntk表示叶节点 N t N_{t} Nt中类别为k的样本数。 K K K表示样例类别总数。
这时,去掉前面的 − l o g -log −log就变成了如下:
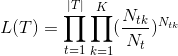
以极大似然估计角度来说,模型可以看成树模型,参数值可以看成具体的树的结构以及每个叶节点中的取值,则极大似然为
L ( θ ) = ∏ p ( x , y ) L(\theta)=\prod{p(x,y)} L(θ)=∏p(x,y)
而对树模型来说一个树的结构确定之后,对于一个样本,被分到某个节点是确定的,所以写成 L ( θ ) = ∏ t = 1 ∣ T ∣ ∏ x ∈ t p ( y ∣ x ∈ t ) L(\theta)=\prod_{t=1}^{|T|}\prod_{x\in t}p(y|{x\in t }) L(θ)=t=1∏∣T∣x∈t∏p(y∣x∈t)再看对每个叶子节点做一个极大似然估计,即
L ( θ ) = ∏ t = 1 ∣ T ∣ ( ∏ k = 1 K p ( y ∣ x ∈ t ) ) L(\theta)=\prod_{t=1}^{|T|}(\prod{_{k=1}^K}p(y|{x\in t) }) L(θ)=t=1∏∣T∣(∏k=1Kp(y∣x∈t))括号里面的部分这里其实与朴素贝叶斯求先验是一样的,用极大似然估计会得到 p ( y ∣ x ∈ t ) = N t k N t p(y|{x\in t) }=\frac{N_tk}{N_t} p(y∣x∈t)=NtNtk,进而 L ( θ ) = ∏ t = 1 ∣ T ∣ ∏ k = 1 K ( N t k N t ) N t k L(\theta)=\prod_{t=1}^{|T|}\prod_{k=1}^K(\frac{N_tk}{N_t})^{N_{tk}} L(θ)=∏t=1∣T∣∏k=1K(NtNtk)Ntk对它求极大其实就是要对树结构进行优化使得估计最大。至此,两者就等价了。
因为树模型如果不加正则的话,其实会使得每个叶子节点中的样本y值都一样,那么此时 N t k N t \frac{N_tk}{N_t} NtNtk其实就是1,因为它中只有一类。如果说加了正则项,那么节点中可能有多类;此时如果不考虑对每个节点只设置一个值,从生成模型的观点出发,也可以把这时候的树看成一个生成模型,(个人观点),但是树模型对每个节点都规定了统一的值,所以说它是一个判别模型(无法得到概率分布 p ( x , y ) {p(x,y)} p(x,y))
ID3.0和C4.5区别与联系
C4.5算法继承了ID3算法的优点,并在以下几方面对ID3算法进行了改进:
- 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;(可以看最开始但时候的说明)
- 在树构造过程中进行剪枝;(ID3.0没有剪枝流程)
- 能够完成对连续属性的离散化处理;(连续值离散化,ID3.0没有)
- 能够对不完整数据进行处理。(ID3.0没有)
C4.5算法有如下优点:产生的分类规则易于理解,准确率较高。其缺点是:在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
另外,无论是ID3还是C4.5最好在小数据集上使用,决策树分类一般只试用于小数据。当属性取值很多时最好选择C4.5算法,ID3得出的效果会非常差。
总结决策树的优缺点
优点:
- 可解释性强
- 可处理混合类型的特征
- 不用归一化处理
- 由特征组合的作用
- 可自然的处理缺失值
- 对异常点鲁棒性较强
- 有特征选择的作用
- 可扩展性强,容易并行
缺点:
- 缺乏平滑性
- 不适合处理高维度稀疏的数据
关于GBDT以及XGB的构造方法的探究
首先这两个树都是基于泰勒公式,GBDT是一阶
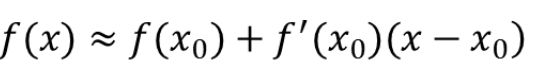
XGB是二阶
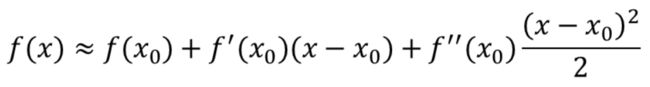
其实他们的做法的思想就是最速下降和牛顿法,这里先列一下这两者优化方法
- 最速下降应用泰勒

使用

得到

此时应该取 α = a r g m i n α ( L ( θ ) ) \alpha=argmin_{\alpha}(L(\theta)) α=argminα(L(θ))
- 牛顿法应用泰勒

用 g , h g,h g,h表示一阶和二阶导数得

因为前面的 L ( θ t − 1 ) L(\theta^{t-1}) L(θt−1)是常数,所以要求后面的最小,可以看出它是一个凸函数(因为原函数是凸的,所以二阶倒数 h h h为正/正定矩阵),所以求的最小值有

得

写成向量形式,其中 H − 1 H^{-1} H−1为二阶海森矩阵的逆

现在对应到GBDT和XGB
首先因为他们的基分类器都是CART树,而GBDT一般用CART回归树(也有可能用其他的),即loss是MSE,那么此时
L ( θ t ) = L ( y , y t − 1 + f t ( x ) ) = 1 2 ( y − y t − 1 − f t ( x ) ) 2 L(\theta_t)=L(y,y_{t-1}+f_t(x)) =\frac{1}{2}(y-y_{t-1}-f_t(x))^2 L(θt)=L(y,yt−1+ft(x))=21(y−yt−1−ft(x))2
令 r = y − y t − 1 r=y-y_{t-1} r=y−yt−1为残差,则
L ( θ t ) = 1 2 ( r − f t ( x ) ) 2 = ∑ i 1 2 ( r i − f t ( x i ) ) 2 L(\theta_t)=\frac{1}{2}(r-f_t(x))^2=\sum_i\frac{1}{2}(r_i-f_t(x_i))^2 L(θt)=21(r−ft(x))2=i∑21(ri−ft(xi))2
这时候我们发现要使得loss最小,就让新的树去拟合残差就好,对应到刚才到最速下降里面,
![]()
我们对它一阶展开
L ( θ t − 1 ) = ∑ i 1 2 ( y − y i t − 1 ) 2 = ∑ i 1 2 r i 2 L(\theta^{t-1})=\sum_i\frac{1}{2}(y-y_i^{t-1})^2=\sum_i\frac{1}{2}r_i^2 L(θt−1)=i∑21(y−yit−1)2=i∑21ri2
L ′ ( θ t − 1 ) = ∑ i − r i L^{'}(\theta^{t-1})=\sum_i-r_i L′(θt−1)=i∑−ri
Δ θ = − α L ′ ( θ t − 1 ) = α ∑ i r i \Delta\theta=-\alpha L^{'}(\theta^{t-1})=\alpha\sum_ir_i Δθ=−αL′(θt−1)=αi∑ri
则 L ( θ t ) ≈ ∑ i ( 1 2 − α ) r i 2 L(\theta^t)\approx \sum_i(\frac{1}{2}-\alpha)r_i^2 L(θt)≈i∑(21−α)ri2
取 α = a r g m i n α ( L ( θ ) ) \alpha=argmin_{\alpha}(L(\theta)) α=argminα(L(θ)),
这里以 α = 1 2 \alpha=\frac{1}{2} α=21才算好,这与我们之前看到的取拟合残差 r i r_i ri明显不同,这是因为泰勒公式是一个近似,后面的余项还是正的,所以我们我们从负梯度出发,只能保证方向正确,最好的学习率不能保证,所以需要换一个方法:

这里,我们先利用MSE为度量用第t棵树 h t ( x ) h_t(x) ht(x)去拟合负梯度 y ⌢ \overset{\frown}y y⌢,然后学好一棵树之后,再去找步长!也就是2.3中的操作,最后得到了完整的树模型。我们经常忽略这一步是因为用CART回归树作基分类器具时,2.3步求得的参数为1,所以没有考虑。而且其实我们可以看出来2.2里面确定树的准则就是MSE,所以说它和拟合残差的过程是一模一样的。(损失函数改变时候就不是了)
其实上面开始所说的思路,这种思想其实是XGB的思路,那为什么XGB可以这样做?因为它用到了二阶泰勒,所以后面的余项是影响大大减小了
XGB推导过程
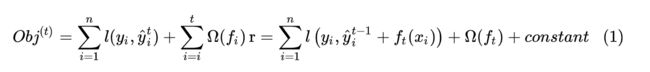



此时求极小

我们就根据这个loss去一步步的确定树的结构

另一个博客上的写法
这时候XGB与GBDT的差别出来了,GBDT在基于CART回归树时,可以看作我们先确定好每个 x i x_i xi要拟合的值(即残差)再去根据MSE去构造一棵树,为什么这两种等价,就是因为构造方法和损失都是MSE,而现在我们构造不再根据MSE,而是根据这个Gain,如果我们要先确定叶节点再去根据gain构造树的话, 行不通的点在于叶节点值是一个商,而计算Gain时需要将G和H还原,这点不能实现。
总结起来:学习负梯度,之后再去寻求最佳步长or拟合上一轮残差(在以CART回归树为基函数,即loss为MSE时等价),这种思想是GBDT的思想;去根据泰勒公式去极小化目标函数这是XGB的思想。GBDT可以先确定叶节点再构造树,XGB不能。
贴一个链接,讲的挺好的
https://blog.csdn.net/fantacy10000/article/details/84257281
还有一个对XGB并行的理解:
为什么说XGB的并行很厉害,其实决策树本来确定特征和切分点的时候就是并行,它厉害的点在于它用的信息里面有二阶海森阵,计算时可以并行计算这个海森阵,而这个东西很难算,这也是牛顿法不常用的原因。