【机器学习】贝叶斯分类-垃圾短信分类-SMSSpamCollection
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB,BernoulliNB,GaussianNB
# 读取文件
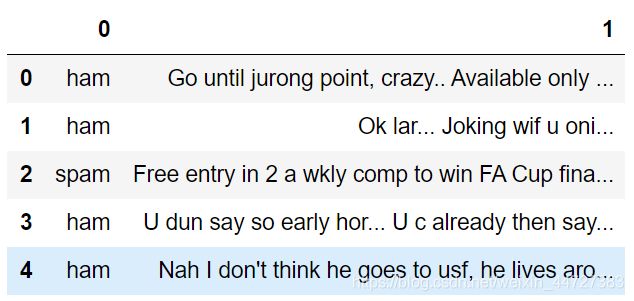
sms = pd.read_csv('./data/SMSSpamCollection', sep='\t', header=None)
sms.head()
查看数据,ham表示非垃圾邮件,spam表示垃圾邮件
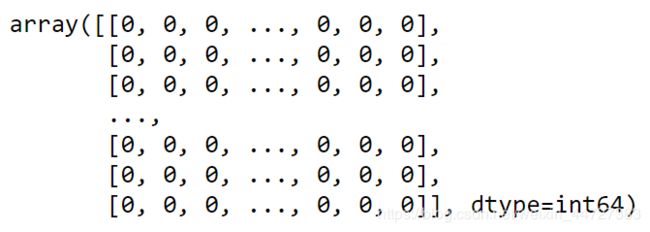
count = CountVectorizer()
count.fit(data.values.tolist())
count.transform(data.values.tolist()).toarray()
data = sms.loc[:,1]
target = sms.loc[:,0]
tf_idf = TfidfVectorizer()
tf_idf.fit(data.values.tolist())
# 这个稀疏矩阵对象是不能直接放到机器学习算法中训练的.需要使用toarray()转化成ndarray才行
data_converted = tf_idf.transform(data.values.tolist()).toarray()
ga_nb = GaussianNB()
ga_nb.fit(data_converted, target)
ga_nb.score(data_converted, target)
0.9414931801866475
mu_nb = MultinomialNB()
mu_nb.fit(data_converted, target).score(data_converted, target)
0.9761306532663316
be_nb = BernoulliNB()
be_nb.fit(data_converted, target).score(data_converted, target)
0.9881550610193827
自己创建文本进行预测
messages = [
'how are you .fine, thank you and you?',
"Good News, You'v won a big prize, please call 00861888888888 for more information",
'are you ok',
'not at all',
'WINNER, You have won a 1 week FREE membership in our £100,000 Prize Jackpot!',
'winner winner chicken dinner',
'Congratulations on your invitation to join Honor Society!',
'I love you guys.',
'Extra large discount, three bamboo rats and three 10 yuan',
'good good study day day up'
]
x_test = tf_idf.transform(messages).toarray()
ga_nb.predict(x_test)
array([‘ham’, ‘spam’, ‘spam’, ‘spam’, ‘spam’, ‘spam’, ‘ham’, ‘spam’,
‘ham’, ‘ham’], dtype=’