逻辑回归——用来做分类的回归模型
目录
回归模型做分类
逻辑回归的目标函数
实例及代码实现
LR 处理多分类问题
回归模型做分类
LR 却是用来做分类的。它的模型函数为:
![]()
设置z = 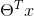
![]()
在二维坐标中形成 S 形曲线:
上图中,z 是自变量(横轴),最终计算出的因变量 y(纵轴),则是一个 [0,1] 区间之内的实数值。
一般而言,当 y>0.5时,z 被归类为真(True)或阳性(Positive),否则当 y<=0.5 时,z 被归类为假(False)或阴性(Negative)。所以,在模型输出预测结果时,不必输出 y 的具体取值,而是根据上述判别标准,输出1(真)或0(假)。
因此,LR 典型的应用是二分类问题上,也就是说,把所有的数据只分为两个类。
此模型函数在 y=0.5 附近非常敏感,自变量取值稍有不同,因变量取值就会有很大差异,所以不用担心出现大量因细微特征差异而被归错类的情况——这也正是逻辑回归的“神奇”之处。
逻辑回归的目标函数
有了模型函数,来看看逻辑回归的目标函数。
是我们要通过训练得出来的最终结果。在最开始的时候,我们不知道其中的参数 θ 的取值,我们所有的只是若干的 x 和与其对应的 y(训练集合)。训练 LR 的过程,就是求 θ 的过程。
首先要设定一个目标:我们希望这个最终得出的 θ 达到一个什么样的效果——我们当然是希望得出来的这个 θ,能够让训练数据中被归为阳性的数据预测结果都为阳,本来被分为阴性的预测结果都为阴。
而从公式本身的角度来看,h(x) 实际上是 x 为阳性的分布概率,所以,才会在 h(x)>0.5 时将 x 归于阳性。也就是说 h(x)=P(y=1)。反之,样例是阴性的概率 P(y=0)=1−h(x)。
当我们把测试数据带入其中的时候,P(y=1)和 P(y=0) 就都有了先决条件,它们为训练数据的 x 所限定。因此:
![]()
根据二项分布公式,可得出
![]()
假设我们的训练集一共有 m 个数据,那么这 m 个数据的联合概率就是:
我们求取 θ 的结果,就是让这个 L(θ) 达到最大。
我们求取 θ 的结果,就是让这个 L(θ) 达到最大。
L(θ) 就是 LR 的似然函数。我们要让它达到最大,也就是对其进行“极大估计”。因此,求解 LR 目标函数的过程,就是对 LR 模型函数进行极大似然估计的过程。我们要求出让 l(θ) 能够得到最大值的 θ。
为了好计算,我们对它求对数。得到对数似然函数:
![]()
我们要求出让 l(θ) 能够得到最大值的 θ。
l(θ) 其实可以作为 LR 的目标函数。前面讲过,我们需要目标函数是一个凸函数,具备最小值。因此我们设定:J(θ)=−l(θ)。
![]()
这样,求 l(θ) 的最大值就成了求 J(θ) 的最小值。J(θ) 又叫做负对数似然函数。它就是 LR 的目标函数。
我们已经得到了 LR 的目标函数 J(θ),并且优化目标是最小化它。
如何求解 θ呢?具体方法其实有很多。此处我们仍然运用之前已经学习过的,最常见最基础的梯度下降算法。
实例及代码实现
我们来看一个例子,比如某位老师想用学生上学期考试的成绩(Last Score)和本学期在学习上花费的时间(Hours Spent)来预期本学期的成绩:
用逻辑回归的时候,我们就不再是预测具体分数,而是预测这个学生本次能否及格了。
这样我们就需要对数据先做一下转换,把具体分数转变成是否合格,合格标志为1,不合格为0,然后再进行逻辑回归:
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LinearRegression
import pandas as pd
# Importing dataset
data = pd.read_csv('quiz.csv', delimiter=',')
used_features = ["Last Score", "Hours Spent"]
X = data[used_features].values
scores = data["Score"].values
X_train = X[:11]
X_test = X[11:]
# Logistic Regression – Binary Classification
passed = []
for i in range(len(scores)):
if (scores[i] >= 60):
passed.append(1)
else:
passed.append(0)
y_train = passed[:11]
y_test = passed[11:]
classifier = LogisticRegression(C=1e5)
classifier.fit(X_train, y_train)
y_predict = classifier.predict(X_test)
print(y_predict)
[1 0 1]
Process finished with exit code 0LR 处理多分类问题
假设你一共有 n 个标签(类别),也就是说可能的分类一共有 n 个。那么就构造 n 个 LR 分类模型,第一个模型用来区分 label_1和 non-label _1(即所有不属于 label_1 的都归属到一类),第二个模型用来区分 label_2 和 non-label _2……, 第 n 个模型用来区分 label_n 和 non-label _n。
使用的时候,每一个输入数据都被这 n 个模型同时预测。最后哪个模型得出了 Positive 结果,就是该数据最终的结果。
如果有多个模型都得出了 Positive,那也没有关系。因为 LR 是一个回归模型,它直接预测的输出不仅是一个标签,还包括该标签正确的概率。那么对比几个 Positive 结果的概率,选最高的一个就是了。
比如还是上面的例子,现在我们需要区分:学生的本次成绩是优秀(>=85),及格,还是不及格。我们就在处理 y 的时候给它设置三个值:0 (不及格)、1(及格)和2(优秀),然后再做 LR 分类就可以了。代码如下:
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LinearRegression
import pandas as pd
# Importing dataset
data = pd.read_csv('quiz.csv', delimiter=',')
used_features = [ "Last Score", "Hours Spent"]
X = data[used_features].values
scores = data["Score"].values
X_train = X[:11]
X_test = X[11:]
# Logistic Regression - Multiple Classification
level = []
for i in range(len(scores)):
if(scores[i] >= 85):
level.append(2)
elif(scores[i] >= 60):
level.append(1)
else:
level.append(0)
y_train = level[:11]
y_test = level[11:]
classifier = LogisticRegression(C=1e5)
classifier.fit(X_train, y_train)
y_predict = classifier.predict(X_test)
print(y_predict)