JS——正则表达式
目录
- 一、什么是正则?
- 二、创建正则表达式
- 三、修饰符
- 四、元字符
- 五、方法
- 1、test()
- 2、search()
- 3、match
- 4、replace
- 六、括号
- 1、小括号
- 2、中括号
- 3、大括号
- 七、常用的正则表达式
- 1、用户名
- 2、密码强度
- 3、Email
- 4、手机号码
- 5、身份证号
- 6、URL
- 7、ipv4地址
- 8、十六进制颜色
- 9、日期
- 10、QQ号
- 11、微信号
- 12、车牌号
一、什么是正则?
正则表达式实际上就是规定了一系列的字符串规则,例如说我们看到188 xxxx 8888就能知道这是一个手机号,看到[email protected]就知道这是一个邮箱。那么,我们怎么让计算机知道这一切呢?
我们人类之所以能分辨出来是因为我们心里有一个模型,我们知道十一位的数字很有可能就是一个手机号,@+邮箱品牌+.com的组合很有可能是一个邮箱。正则正式提供一种语法,让我们把自己心中的那种识别模式告诉计算机,让计算机能像我们人类一样去识别特定的字符串。
二、创建正则表达式
1、构造函数:new RegExp()
2、字面量 两/之间写入表达式:/表达式/
var re01 = new RegExp('a'); //这种形式创建,可以往正则中传入变量
var re02 = /a/; // 简写形式不可以传入变量,且不能加引号
注意: 构造函数写法可以传入变量,而字面量写法不能传入变量,也不能加引号。
三、修饰符
| 项目 | Value |
|---|---|
| g | global 全文搜索,不添加,则搜索到第一个匹配就停止 |
| i | ignoreCase 忽略大小写,不添加,默认为大小写敏感 |
| m | multiple lines 多行搜索 |
| l | laseIndex 是当前表达式匹配内容的最后一个字符的下一个位置 |
| s | source 正则表达式的文本字符串 |
四、元字符
正则表达式由两种基本字符类型组成:原义文本字符和元字符。
原义文本字符:表示本来意思的字符,例如a表示a,1表示1;
元字符:是正则表达式中有特殊含义的非字母字符,如下:
| 元字符 | 描述 |
|---|---|
| \ | 例如,‘n’ 匹配字符 “n”。而加了元字符后,’\n’ 匹配一个换行符。序列 '\\ ’ 匹配 ‘\’,"\( " 则匹配 “(”。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。* 等价于{0,} 。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 。? 等价于 {0,1}。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 “oooo”,‘o+?’ 将匹配单个 “o”,而 ‘o+’ 将匹配所有 ‘o’。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像"(.|\n)"的模式。 |
| 元字符 | 描述 |
|---|---|
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,“o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
| 元字符 | 描述 |
|---|---|
| x|y | 匹配 x 或 y。例如,‘z|food’ 能匹配 “z” 或 “food”。’(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,’[a-z]’ 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,’[^a-z]’ 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符。 |
简记:[^] 为取反
注意:^[] 是开始位置,而[^] 是取反
| 元字符 | 描述 |
|---|---|
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配字母、数字、下划线。等价于’[A-Za-z0-9_]’。 |
| \W | 匹配非字母、数字、下划线。等价于 ‘[^A-Za-z0-9_]’。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,’\x41’ 匹配 “A”。’\x041’ 则等价于 ‘\x04’ & “1”。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
| [\u4E00-\u9FA5] | 汉字 |
简记:大写是小写的反义。
五、方法
1、test()
test()方法是正则对象上的一个方法,接受一个字符串作为参数,如果字符串中有符合正则的部分,则返回true,反之则返回false。
var str = 'abcd';
var re = /a/;
re.test(str) // true
2、search()
查找字符串中是否有符合正则的部分,如果有,返回第一个匹配项的位置,否则返回-1;
var str = 'bbcasa';
var re = /a/;
str.search(re) // 4
3、match
寻找字符串中符合正则的匹配项,并将这些匹配项以数组的形式返回,否则返回null。
var str = 'abcaadaefaa';
var re = /a+/g;
// "+" 是一个量词表示出现一次或更多,"g"表示全局搜索,正则默认匹配到一个匹配项后就不会继续查找了。
str.match(re) // ["a", "aa", "a", "aa"]
4、replace
str.replace(re, newStr | callback) 该方法首先匹配字符串中符合正则的部分然后替换成newStr或者callback的返回值。
这里的callback = function(str,str1,str2…){return res},参数str表示匹配到的匹配项,str1,str2…分别表示正则匹配项中的第一个,第二个子项。
var str = "我爱吃饭,我爱睡觉,我爱打豆豆";
var re = /(吃饭)|(睡觉)|(打豆豆)/g ;
str.replace(re, ($0) => {
return $0.split("").map(() => {return "*"}).join("")
})
![]()
六、括号
1、小括号
(1)分组操作:小括号内的部分作为一个整体进行操作,找到则以下一字符为起点继续找,匹配则当成一个整体,不匹配则进行下一次匹配。
var str1 = '2020-8-4'
var re01 = /\d-+/g
var re02 = /(\d-)+/g
str1.match(re01) // ['0-', '8-']
str1.match(re02) // ['0-8-']
var str2 = '2020-8-04-' // 与str1不同
var re03 = /\d-+/g
var re04 = /(\d-)+/g
str2.match(re03) // ['0-', '8-', '4-']
str2.match(re04) // ['0-8-', '4-']
// 04-不是8-的下一字符匹配,因此进行下一次匹配。
(2)匹配子项:整个正则匹配到的匹配项我们暂且成为父项,然后就容易理解,被小括号括起来的各个部分就是父项下面的一个一个的子项。
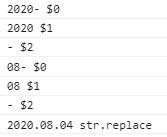
这里$0代表的是匹配到的父项:[‘2020-’, ‘08-’]
而$1代表父项的第一个子项:‘2020’和’08’,简记:第一个小括号
$2代表父项的第二个子项: ‘-‘和’-’,简记:第二个小括号
var str = '2020-08-04'
var re = /(\d+)(-)/g
console.log(str.replace(re, ($0, $1, $2) => {
console.log($0, '$0')
console.log($1, '$1')
console.log($2, '$2')
return $1 + "."
}))
(3)match()方法在不加g的情况下,在返回的数组中会展开所有子项;
var str = 'abc'
var re = /(a)(b)(c)/
str.match(re) // ['abc', 'a', 'b', 'c']
2、中括号
[] 整体代表一位,内部关系为或。
比如:
[abc]整体代表一个字符,内部为或的关系。即只能匹配a、b、c之一。
[^abc]整体代表一位,但不能是a、b、c之一
[a-z]: 整体代表一位,只能匹配a到z之一
[a-z]+: 一位或多位,匹配a到z之一
3、大括号
大括号用来表示量词
{4, 7}: 4-7次
{4,}:最少4次
{4}:正好4次
{1,} 相当于+,一次或多次
?相当于{0,1},零次或一次
*相当于{0,},零次或多次
七、常用的正则表达式
1、用户名
4到16位(字母,数字,下划线,减号)
var uPattern = /^[a-zA-Z0-9_-]{4,16}$/
2、密码强度
最少8位,最多16位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
var pPattern = /(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[^a-zA-Z0-9]).{8,16}/
3、Email
邮箱的基本格式为“名称@域名”,需要使用“^”匹配邮箱的开始部分,用“$”匹配邮箱结束部分以保证邮箱前后不能有其他字符
var ePattern = /^[a-zA-Z0-9_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/
但这个是名称只能是a-z、A-Z和0-9组成,而域名是xx.xxx或者xx.xx.xxx等等形式。
比如:
wu123@qq.com //true
wu@123.com //true
wu@123.123 // true
wu@123.123.123 // true
吴@123.123 //false
允许汉字的邮箱名称: 正则[\u4e00-\u9fa5]
即
var ePattern = /^[a-zA-Z0-9\u4e00-\u9fa5_-]+@[a-zA-Z0-9_-]+(\.[a-zA-Z0-9_-]+)+$/
4、手机号码
var mPattern = /^1[34578]\d{9}$/
5、身份证号
var cPattern = /^[1-9]\d{5}(18|19|([23]\d))\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\d{3}[0-9Xx]$/;
6、URL
url= 协议://(ftp的登录信息)[IP|域名](:端口号)(/或?请求参数)
var strRegex = '^((https|http|ftp)://)?(([\\w_!~*\'()\\.&=+$%-]+: )?[\\w_!~*\'()\\.&=+$%-]+@)?(([0-9]{1,3}\\.){3}[0-9]{1,3}|(localhost)|([\\w_!~*\'()-]+\\.)*\\w+\\.[a-zA-Z]{1,6})(:[0-9]{1,5})?((/?)|(/[\\w_!~*\'()\\.;?:@&=+$,%#-]+)+/?)$'
var re = new RegExp(strRegex,'i')
分部分解释:
//url= 协议://(ftp的登录信息)[IP|域名](:端口号)(/或?请求参数)
var strRegex = '^((https|http|ftp)://)?' // (https或http或ftp):// 可有可无
+ '(([\\w_!~*\'()\\.&=+$%-]+: )?[\\w_!~*\'()\\.&=+$%-]+@)?' // ftp的user@ 可有可无
+ '(([0-9]{1,3}\\.){3}[0-9]{1,3}' // IP形式的URL- 3位数字.3位数字.3位数字.3位数字
+ '|' // 允许IP和DOMAIN(域名)
+ '(localhost)|' // 匹配localhost
+ '([\\w_!~*\'()-]+\\.)*' // 域名- 至少一个[英文或数字_!~*\'()-]加上.
+ '\\w+\\.' // 一级域名 -英文或数字 加上.
+ '[a-zA-Z]{1,6})' // 顶级域名- 1-6位英文
+ '(:[0-9]{1,5})?' // 端口- :80 ,1-5位数字
+ '((/?)|' // url无参数结尾 - 斜杆或这没有
+ '(/[\\w_!~*\'()\\.;?:@&=+$,%#-]+)+/?)$' // 请求参数结尾- 英文或数字和[]内的各种字符
验证:
function CHECK_URL(url){
//url= 协议://(ftp的登录信息)[IP|域名](:端口号)(/或?请求参数)
var strRegex = '^((https|http|ftp)://)?(([\\w_!~*\'()\\.&=+$%-]+: )?[\\w_!~*\'()\\.&=+$%-]+@)?(([0-9]{1,3}\\.){3}[0-9]{1,3}|(localhost)|([\\w_!~*\'()-]+\\.)*\\w+\\.[a-zA-Z]{1,6})(:[0-9]{1,5})?((/?)|(/[\\w_!~*\'()\\.;?:@&=+$,%#-]+)+/?)$'
var re = new RegExp(strRegex,'i')
//将url做uri转码后再匹配,解除请求参数中的中文和空字符影响
if (re.test(encodeURI(url))) {
return (true)
} else {
return (false)
}
}
var textArr = ['www.baidu.com','http://www.baidu.com','http://www.baidu.com/','https://www.baidu.com/a/b/c','https://www.baidu.com:80/a/b?t=123','https://www.baidu.com:8080/a/b?t=123&c=吴','https://www.baidu.com:8080?a=吴&b=123','http://192.168.99.111:1212/a/b/c','112.22.12.2','a.b.c','localhost/cc/2/b/5','ftp://192.17.11.22:22/测试.tar','https://m.www.baidu.测试:8080?a=吴&b=123&c=321']
for(var i in textArr){
var a = CHECK_URL(textArr[i])
document.write(textArr[i]+' 结果:'+a+'
')
}

7、ipv4地址
var ipPattern = /^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)(\/(\d|[1-2]\d|3[0-2]))?$/
IPV4地址由4个组数字组成,每组数字之间以.分隔,每组数字的取值范围是0-255。
IPV4必须满足以下四条规则:
(1)任何一个1位或2位数字,即0-99;
(2)任何一个以1开头的3位数字,即100-199;
(3)任何一个以2开头、第2位数字是0-4之间的3位数字,即200-249;
(4)任何一个以25开头,第3位数字在0-5之间的3位数字,即250-255。
构造一个正则表达式的思路:
(1)满足第一二条规则的正则是:[01]?\d\d?)
(2)满足第三条规则的正则是:2[0-4]\d
(3)满足第四条规则的正则是:25[0-5]
则匹配一个0-255的正则表达式为:(25[0-5]|2[0-4]\d|[01]?\d\d?)
IPV4由四组这样的数字组成,中间由.隔开,则有:
/^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)$/
但是这样不能匹配255.255.255.255/1这种形式的
mask的规则为:
(1)以/为分隔符,且最多只有一个mask \/
(2)任何一个1位数字,即0-9;\d
(3)任何一个以1或2开头的2位数字,即10-29;[1-2]\d
(4)任何一个以3开头、第2位数字是0-2之间的2位数字,即30、31、32;3[0-2]
则匹配mask的正则表达式为:(\/(\d|[1-2]\d|3[0-2]))?
/^((25[0-5]|2[0-4]\d|[01]?\d\d?)\.){3}(25[0-5]|2[0-4]\d|[01]?\d\d?)(\/(\d|[1-2]\d|3[0-2]))?$/
8、十六进制颜色
var cPattern = /^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/
9、日期
//日期正则,复杂判定
var dPattern = /^(?:(?!0000)[0-9]{4}-(?:(?:0[1-9]|1[0-2])-(?:0[1-9]|1[0-9]|2[0-8])|(?:0[13-9]|1[0-2])-(?:29|30)|(?:0[13578]|1[02])-31)|(?:[0-9]{2}(?:0[48]|[2468][048]|[13579][26])|(?:0[48]|[2468][048]|[13579][26])00)-02-29)$/
// 输出 true
console.log(dPattern.test("2020-08-04"))
// 输出 false
console.log(dPattern.test("2020-18-04"))
// 输出 false
console.log(dPattern.test("2020-02-30"))
// 输出 true
console.log(dPattern.test("2020-02-29"))
// 输出 false
console.log(dPattern.test("2019-02-29"))
10、QQ号
5至11位
var qqPattern = /^[1-9][0-9]{4,10}$/
11、微信号
6至20位,以字母开头,字母,数字,减号,下划线
var wxPattern = /^[a-zA-Z]([-_a-zA-Z0-9]{5,19})+$/
12、车牌号
var cPattern = /^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领A-Z]{1}[A-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/