python3爬虫系列02之urllib库:根据关键词自动爬取下载百度图片
python3爬虫系列02之urllib库:根据关键词自动爬取下载百度图片
上一篇文章介绍了整个 爬虫的基本架构 一文,后面的文章就开始实战环节了。
【其实中间应该还可以说两篇,关于抓包的,一个是浏览器的F12审查元素,一个是使用Fiddler软件抓App的包。但是过于基础,后面有需要再写吧。】
实战系列呢,会从最初代的爬虫方式一直写到现在的分布式爬虫框架scrapy,而且源码都会给出。
当然,这个系列也是作为本人入门爬虫的记录,因此文中有很多不足之处,欢迎补充。
废话不多说,开始搞起。
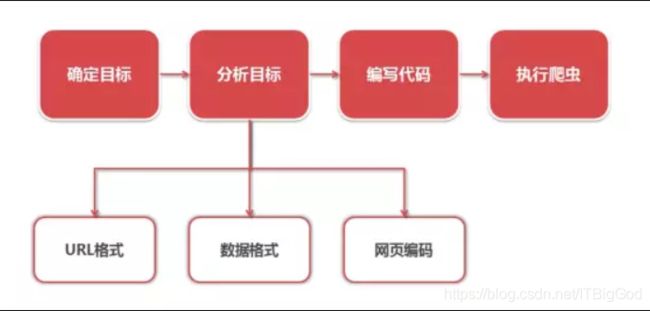
开发爬虫的步骤大概就是这样的:

这也是以后我们开发实战中的步骤。
1.网页下载器—urllib库
爬虫开始肯定得从简单到难,我们先从简单说起。在第一篇中说过,爬虫最重要的三步——URL管理器 -> 网页下载器() -> 网页解析器()。
其中,URL管理器,就是一个URL的python类,自己写的。因为在使用中,它不是必须要有的,所不需要单独介绍。
那么就是网页下载器了的介绍了。
什么是Urllib?
怎么用 python 写各种请求呢?答案就是urllib。
urllib是python内置的HTTP请求库,其主要作用就是可以通过代码模拟浏览器发送请求。
图示:

其中urllib库里面最常用的模块是:
request:用它来发起请求。
error:遇到错了异常处理。
parse:解析 URL 地址。
robotparser:用得少,用来解析网站的 robot.txt文件的。
【值得注意:在Python2中是urllib和urllib2被在Python3中urllib.request和urllib.parse替代。】
图示:
记住——urllib在爬虫的时候,属于网页下载器的工具!
了解了 urllib 之后,我们就用 python 代码来模拟请求吧。
2.实战:基于urllib实现根据关键词图片自动下载器
百度图片自动下载器就是一个爬虫,批量爬取百度的相关图片,然后下载到本地的程序。
要用的技术点:
- python3
- pycharm
- urllib库
- re 正则表达式
1.确定目标(需求分析)
目标地址: http://image.baidu.com/
"我想要图片,我又不想上网搜“,“最好还能自动下载”?
假设这就是用户需求吧。所以我们开始分析需求,至少要实现两个功能吧,一个是搜索图片,二个是自动下载。
打开百度图片,看看

我们试着搜一个东西,我打一个 “蘑菇头”,出来一系列搜索结果,回车:
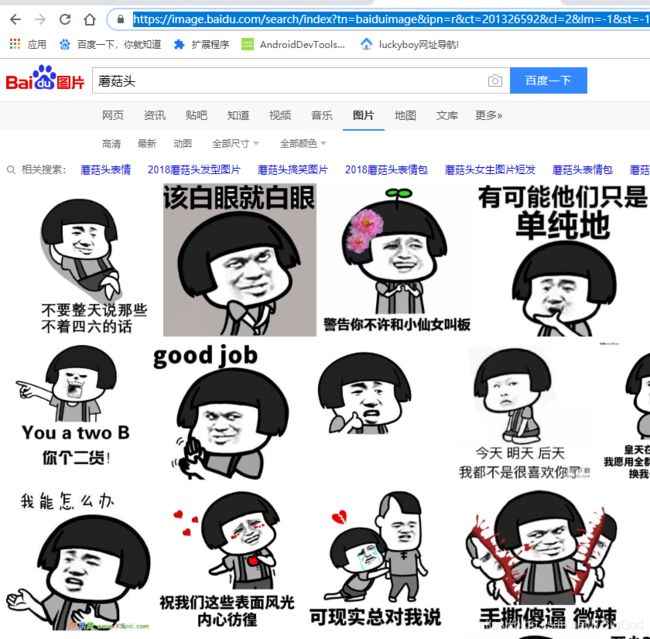
好了,我们已经看到了很多图片了,如果我们能把这里面的图片都爬下来就好了。
我们看见网址里有关键词信息:

URL分析:
(在这里你会看到,明明在浏览器URL栏看到的是中文,但是复制url,粘贴到记事本或代码里面,就会变成如下这样???)
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E8%98%91%E8%8F%87%E5%A4%B4&oq=%E8%98%91%E8%8F%87%E5%A4%B4&rsp=-1
所以!这里要补课了~~
在很多网站的URL中对一些get的参数或关键字进行编码,所以我们复制出来的时候,会出现问题。
URL的编码与解码(*重要)
源码:
import urllib
from urllib import parse
import urllib.request
data = {'word': '蘑菇头'}
# Python3的urlencode需要从parse中调用,可以看到urlencode()接受的是一个字典
print(urllib.parse.urlencode(data))
# 通过urllib.request.unquote()方法,把URL编码字符串,转换回原先字符串
print(urllib.request.unquote('word=%E8%98%91%E8%8F%87%E5%A4%B4'))
运行结果:
好了,知道这个原理以后,我们在原来的URL上,直接换下关键词,跳转了有没有?
猫啊
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1572606236097_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E7%8C%AB
狗啊
https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1572606314984_R&pv=&ic=0&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&ctd=1572606314985%5E00_1903X937&sid=&word=%E7%8B%97
直接这么改的:
所以可以看出通过这个网址查找特定的关键词的图片,所以理论上,我们可以不用打开网页就能搜索特定的图片了。
下个问题就是如何实现自动下载,其实利用之前的知识,我们知道可以用爬虫,获取图片的网址,然后把它爬下来,保存成.jpg就行了。
2.分析目标(分析网页源代码)
好了,我们开始做下一步,目前百度图片采用的是瀑布流模式,动态加载图片,处理起来还是比一期麻烦。
F12或者页面上右键审查元素。打开以后,定位到图片的位置、。
复制这个地址:
https://ss1.bdstatic.com/70cFvXSh_Q1YnxGkpoWK1HF6hhy/it/u=4227600235,3494152792&fm=26&gp=0.jpg
然后在当前网页的空白地方右键:查看网页源代码
在这一堆源代码中查找当刚才复制的那个图片的地址: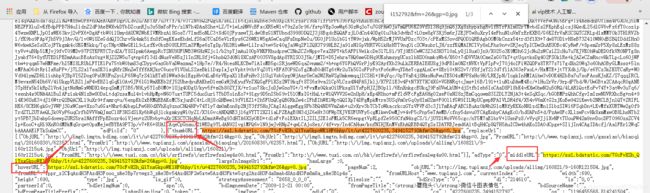 这个图片怎么有这么多地址,到底用哪个呢?我们可以看到有thumbURL,middleURL,hoverURL,objURL等等。
这个图片怎么有这么多地址,到底用哪个呢?我们可以看到有thumbURL,middleURL,hoverURL,objURL等等。
通过分析可以知道,前面两个是缩小的版本,hover是鼠标移动过后显示的版本,objURL对应的那个地址,应该是我们需要的,不信可以打开这几个网址看看,发现obj那个最大最清晰。
好了,找到了图片位置,我们就开始分析它的代码。我看看是不是所有的objURL全是图片。
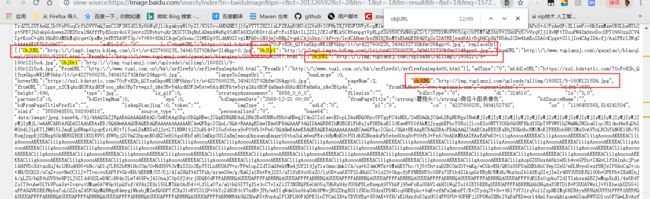
貌似都是以.jpg格式结尾。
3.编写代码(编写正则表达式或者XPath表达式)
pic_url = re.findall(’“objURL”:"(.*?)",’,html,re.S)
不难理解吧?就是objurl后面的,全匹配。
4.执行爬虫
因为我们要根据关键词来搜索图片,然后进行爬虫,下载。所以必须拼接url。
word = input('关键词:')
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
(事先在当前项目建立一个pic/01/的文件夹目录,方便爬虫出来以后把图片都放进去。)
源码:
可以输入关键词直接自动下载相关图片。
import re
from urllib import request
word = input('关键词:')
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
url_request=request.Request(url)
url_response = request.urlopen(url_request) # 请求数据,可以和上一句合并
html = url_response.read().decode('utf-8') # 加编码,重要!转换为字符串编码,read()得到的是byte格式的。
jpglist = re.findall('"objURL":"(.*?)",',html,re.S) #re.S将字符串作为整体,在整体中进行匹配。
n = 1
for each in jpglist:
print(each)
try:
request.urlretrieve(each,'pic/01/%s.jpg' %n) #pic/代表下载的图片放置在提前建好的文件夹pic里
except Exception as e:
print(e)
finally:
print('下载完成。')
n+=1
运行成功如图:
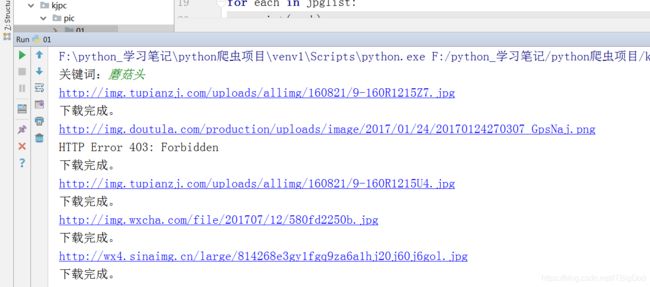
效果:
麻麻再也不用担心我斗图了~~~
 如果有一些下载失败的HTTP Error 403: Forbidden,那是因为百度自己都已经丢了这些资源的URL。没关系的
如果有一些下载失败的HTTP Error 403: Forbidden,那是因为百度自己都已经丢了这些资源的URL。没关系的
其次讲解一下:urlopen函数:
urlopen函数原型:
urllib.request.urlopen(url, data=None, timeout=
在上述案例中我们只使用了该函数中的第一个参数url。在日常开发中,我们能用的只有url和data这两个参数。
url参数:指定向哪个url发起请求
data参数:可以将post请求中携带的参数封装成字典的形式传递给该参数(暂时不需要理解,后期会讲)
urlopen函数返回的响应对象,相关函数调用介绍:
- response.headers():获取响应头信息
- response.getcode():获取响应状态码
- response.geturl():获取请求的url
- response.read():获取响应中的数据值(字节类型)
如果你运行代码的时候,出现了如下报错:
UnicodeEncodeError: ‘ascii’ codec can’t encode characters in position 45-47: ordinal not in range(128)
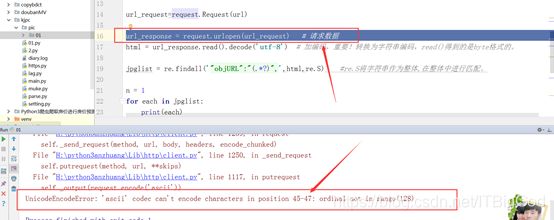
(因为我公司电脑运行没问题,在家运行居然出错。所以贴出来给大家未雨绸缪。)
解决链接:爬虫报错UnicodeEncodeError: ‘ascii’ codec 解决
好了,上述就是今天的python爬虫系列02之 urllib使用:根据关键词自动爬取下载百度图片。
当然不只能下载百度的图片拉,依葫芦画瓢,应该做很多事情了,比如爬取头像,爬淘宝展示图,或美女图片。当然,作为爬虫的第一个实例,虽然纯用urilib.request已经能解决很多问题了,但是效率还是不够高,如果想要高效爬取大量数据,还是用其他的,后面一篇介绍requests库的爬取方式requests库。
参考地址:
https://www.jianshu.com/p/9ddb2f89ec7c
https://www.jianshu.com/p/19c846daccb3