SpringDataElasticsearch的API用法
SpringDataElasticsearch
需要注意的是,SpringDataElasticsearch底层使用的不是Elasticsearch提供的RestHighLevelClient,而是TransportClient,并不采用Http协议通信,而是访问elasticsearch对外开放的tcp端口,我们之前集群配置中,设置的分别是:9300
SDE的索引数据CRUD并没有封装在ElasticsearchTemplate中,而是有一个叫做ElasticsearchRepository的接口: 这个接口操作没有高亮显示
public interface GoodsRepository extends ElasticsearchRepository<Goods, Long> {
}
//就可以注入使用了
@Autowired
private GoodsRepository goodsRepository;
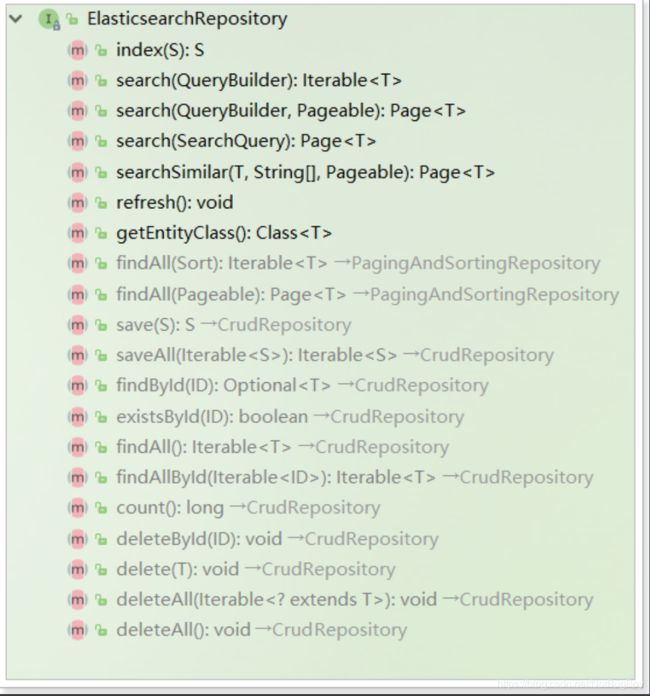
find save findall delete : 操作索引数据的增删改查
search : 搜索
//查询条件构建器
NativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder();
//查询
searchQueryBuilder.withQuery(QueryBuilders.matchAllQuery());
//排序
searchQueryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
//分页
searchQueryBuilder.withPageable(PageRequest.of(0, 5));
//高亮
searchQueryBuilder.withHighlightFields(new HighlightBuilder.Field("title"));
searchQueryBuilder.withHighlightBuilder(new HighlightBuilder().preTags("").postTags(""));
//聚合
searchQueryBuilder.addAggregation(AggregationBuilders.terms("brandAgg").field("brand"));
//条件查询的结果 需要 手动强转成page的实现类AggregatedPage, 因为AggregatedPage里面有聚合 高亮
AggregatedPage<Goods> result = (AggregatedPage<Goods>) goodsRepository.search(searchQueryBuilder.build());
//总条数
long totalElements = result.getTotalElements();
System.out.println("totalElements = " + totalElements);
//总页数
int totalPages = result.getTotalPages();
System.out.println("totalPages = " + totalPages);
//当前页结果
List<Goods> goods = result.getContent();
goods.forEach(System.out::println);
//获取到聚合aggregations
Aggregations aggs = result.getAggregations();
//根据聚合名字 获取到 聚合对象
Terms brandAgg = aggs.get("brandAgg");
//获取到桶
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
//把桶中的聚合结果取出来打印
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString() + bucket.getDocCount());
}
ElasticsearchRepository这个接口 没有提供高亮
因为高亮需要自定义结果, 然而这个接口没有给我们自定义结果的机会,都是封装好的.
所以高亮需要使用下面的 ElasticsearchTemplate模板
如果觉得上述接口依然不符合你的需求,SDE也支持原生查询,这个时候还是使用ElasticsearchTemplate : spring已经整合了
@Autowired
private ElasticsearchTemplate esTemplate;
高亮显示:
@Autowired
private ElasticsearchTemplate esTemplate;
@Test
public void search() {
//查询条件构建器
NativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder();
//查询
searchQueryBuilder.withQuery(QueryBuilders.matchQuery("title","小米手机"));
//排序
searchQueryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.ASC));
//分页
searchQueryBuilder.withPageable(PageRequest.of(0, 5));
//高亮
searchQueryBuilder.withHighlightFields(new HighlightBuilder.Field("title"));
searchQueryBuilder.withHighlightBuilder(new HighlightBuilder().preTags("").postTags(""));
//聚合
searchQueryBuilder.addAggregation(AggregationBuilders.terms("brandAgg").field("brand"));
//搜索结果 高亮显示
AggregatedPage<Goods> result = esTemplate.queryForPage(searchQueryBuilder.build(), Goods.class, new MySearchResultMapper());
//总条数
long totalElements = result.getTotalElements();
System.out.println("totalElements = " + totalElements);
//总页数
int totalPages = result.getTotalPages();
System.out.println("totalPages = " + totalPages);
//当前页结果
List<Goods> goods = result.getContent();
goods.forEach(System.out::println);
//获取到聚合aggregations
Aggregations aggs = result.getAggregations();
//根据聚合名字 获取到 聚合对象
Terms brandAgg = aggs.get("brandAgg");
//获取到桶
List<? extends Terms.Bucket> buckets = brandAgg.getBuckets();
//把桶中的聚合结果取出来打印
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKeyAsString() + bucket.getDocCount());
}
}
@Autowired
private Gson gson;
//自定义接口 用于解析高亮
class MySearchResultMapper implements SearchResultMapper{
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
String scrollId = response.getScrollId();
Aggregations aggregations = response.getAggregations();
//获取命中
SearchHits searchHits = response.getHits();
float maxScore = searchHits.getMaxScore();
long total = searchHits.getTotalHits();
//获取到命中里的每一个hits
SearchHit[] hits = searchHits.getHits();
ArrayList<T> content = new ArrayList<>();
for (SearchHit hit : hits) {
//获取到"_source 里的数据
String json = hit.getSourceAsString();
T t = gson.fromJson(json, clazz);
//每一个hit对象 里面 都有高亮
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
Set<Map.Entry<String, HighlightField>> entries = highlightFields.entrySet();
for (Map.Entry<String, HighlightField> entry : entries) {
//获取到高亮的字段
String field = entry.getKey();
//获取到高亮字段的值
HighlightField highlightField = entry.getValue();
String value = StringUtils.join(highlightField.getFragments());
//反射 设置值
try {
BeanUtils.setProperty(t, field, value);
} catch (Exception e) {
e.printStackTrace();
}
}
content.add(t);
}
return new AggregatedPageImpl<>(content, pageable, total, aggregations, scrollId, maxScore);
}
}