sklearn机器学习:高斯朴素贝叶斯GaussianNB
认识高斯朴素贝叶斯
class sklearn.naive_bayes.GaussianNB (priors=None, var_smoothing=1e-09)
如果Xi是连续值,通常Xi的先验概率为高斯分布(也就是正态分布),即在样本类别Ck中,Xi的值符合正态分布。以此来估计每个特征下每个类别上的条件概率。对于每个特征下的取值,高斯朴素贝叶斯有如下公式:
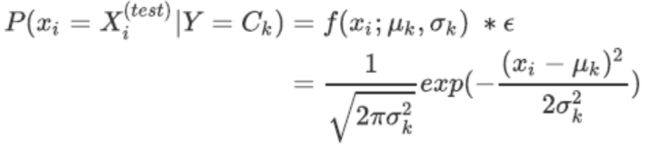
其中, μ k \mu_k μk和 σ k 2 \sigma_k^2 σk2是正态分布的期望和方差,可通过极大似然估计求得。
对于任意一个Y的取值,贝叶斯都以求解最大化P(xi=Xi(test)|Y=Ck)为目标,这样才能够比较在不同标签下的样本究竟更更靠近哪一个取值。
μ k \mu_k μk为样本类别Ck中,所有Xi的平均值。 σ k 2 \sigma_k^2 σk2为在样本类别Ck中,所有Xi的方差。对于一个连续的样本值,带入正态分布的公式,就能够得到一个P(xi=Xi(test)|Y=Ck)的概率取值。
这个类包含两个参数:
prior
可输入任何类数组结构,形状为(n_classes,)
表示类的先验概率。如果指定,则不根据数据调整先验,如果不指定,则自行根据数据计算先验概率P(Y)。
var_smoothing
浮点数,可不填(默认值= 1e-9)
在估计方差时,为了追求估计的稳定性,将所有特征的方差中最⼤大的方差以某个比例添加到估计的方差中。这个比例,由var_smoothing参数控制。
但在实例化的时候,不需要对高斯朴素贝叶斯类输入任何参数,调用的接口也全部是sklearn中比较标准的一些搭配,可以说是一个非常轻量量级的类,操作非常容易。但过于简单也意味着贝叶斯没有太多的参数可以调整,因此贝叶斯算法的成长空间并不是太大,如果贝叶斯算法的效果不是太理想,一般都会考虑换模型。
无论如何,先来进行一次预测试吧:
#高斯朴素贝叶斯
'''手写数字识别,数据是标记过的手写数字的图片,
即采集足够多的手写样本,选择合适模型,进行模型训练,
最后验证手写识别程序的正确性'''
#导入需要的库和数据
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_digits #load_digits手写数字数据集
from sklearn.model_selection import train_test_split
#定义数据集
digits = load_digits()
#数据集赋值
X, y = digits.data, digits.target
#切分数据集
Xtrain,Xtest,Ytrain,Ytest = train_test_split(X,y,test_size=0.3,random_state=420)
#把数据所代表的图片显示出来
images_and_labels = list(zip(digits.images,digits.target))
plt.figure(figsize=(4,3.5),dpi=100) #宽高,单位是inches, 分辨率
for index, (image,label) in enumerate(images_and_labels[:12]):
plt.subplot(3,4,index+1) #行数,列数(从1开始),第几张图(按行数)
plt.axis("off") #关闭坐标轴
plt.imshow(image,cmap=plt.cm.gray_r,interpolation="nearest")
# cmap设置色图到灰色 interpolation 像素间颜色连接方法
plt.title("Digit: %i" % label, fontsize=6)

'''图片数据一般使用像素点作为特征,
由于图片的特殊性,相邻像素点间的数值(RGB三通道色)往往是接近的,
故可以采用矩阵变换的方法压缩矩阵,得到相对较少的特征数
数据总共包含1797张图片,每张图片的尺寸是8×8
像素大小,共有十个分类(0-9),每个分类约180个样本.
所有的图片数据保存在digits.image里,
数据分析的时候需要转换成单一表格,即行为样本列为特征(类似的还有文档词矩阵),
此案例中这个表格已经在digits.data里,可以通过digits.data.shape查看数据格式'''
print("shape of raw image data: {0}".format(digits.images.shape))
print("shape of data: {0}".format(digits.data.shape))
shape of raw image data: (1797, 8, 8)
shape of data: (1797, 64)
#建模,探索建模结果
gnb = GaussianNB().fit(Xtrain,Ytrain)
#查看分数
acc_score = gnb.score(Xtest,Ytest)
acc_score
0.8592592592592593
#查看预测结果
Y_pred = gnb.predict(Xtest)
Y_pred
array([6, 1, 3, 0, 4, 5, 0, 8, 3, 8, 6, 8, 7, 8, 8, 8, 5, 9, 5, 6, 5, 4,
7, 4, 8, 2, 7, 2, 8, 9, 2, 8, 3, 6, 0, 3, 8, 8, 1, 5, 2, 8, 8, 9,
2, 2, 0, 7, 3, 6, 7, 2, 8, 0, 5, 4, 1, 9, 4, 0, 5, 8, 9, 1, 7, 8,
7, 5, 8, 2, 4, 4, 8, 2, 6, 1, 2, 1, 7, 8, 8, 5, 9, 4, 3, 6, 9, 7,
4, 2, 4, 8, 0, 5, 7, 7, 7, 4, 7, 8, 8, 7, 0, 7, 2, 1, 9, 9, 8, 7,
1, 5, 1, 8, 0, 4, 8, 9, 5, 6, 4, 8, 3, 8, 0, 6, 8, 6, 7, 6, 1, 8,
5, 0, 8, 2, 1, 8, 8, 6, 6, 0, 2, 4, 7, 8, 9, 5, 9, 4, 7, 8, 8, 6,
7, 0, 8, 4, 7, 2, 2, 6, 4, 4, 1, 0, 3, 4, 3, 8, 7, 0, 6, 9, 7, 5,
5, 3, 6, 1, 6, 6, 2, 3, 8, 2, 7, 3, 1, 1, 6, 8, 8, 8, 7, 7, 2, 5,
0, 0, 8, 6, 6, 7, 6, 0, 7, 5, 5, 8, 4, 6, 5, 1, 5, 1, 9, 6, 8, 8,
8, 2, 4, 8, 6, 5, 9, 9, 3, 1, 9, 1, 3, 3, 5, 5, 7, 7, 4, 0, 9, 0,
9, 9, 6, 4, 3, 4, 8, 1, 0, 2, 9, 7, 6, 8, 8, 0, 6, 0, 1, 7, 1, 9,
5, 4, 6, 8, 1, 5, 7, 7, 5, 1, 0, 0, 9, 3, 9, 1, 6, 3, 7, 2, 7, 1,
9, 9, 8, 3, 3, 5, 7, 7, 7, 3, 9, 5, 0, 7, 5, 5, 1, 4, 9, 2, 0, 6,
3, 0, 8, 7, 2, 8, 1, 6, 4, 1, 2, 5, 7, 1, 4, 9, 5, 4, 2, 3, 5, 9,
8, 0, 0, 0, 0, 4, 2, 0, 6, 6, 8, 7, 1, 1, 8, 1, 1, 7, 8, 7, 8, 3,
1, 4, 6, 1, 8, 1, 6, 6, 7, 2, 8, 5, 3, 2, 1, 8, 7, 8, 5, 1, 7, 2,
1, 1, 7, 8, 9, 5, 0, 4, 7, 8, 8, 9, 5, 5, 8, 5, 5, 8, 1, 0, 4, 3,
8, 2, 8, 5, 7, 6, 9, 9, 5, 8, 9, 9, 1, 8, 6, 4, 3, 3, 3, 3, 0, 8,
0, 7, 7, 6, 0, 8, 9, 8, 3, 6, 6, 8, 7, 5, 8, 4, 5, 8, 6, 7, 6, 7,
7, 8, 0, 8, 2, 2, 0, 5, 7, 3, 0, 2, 8, 2, 0, 2, 3, 6, 8, 1, 7, 5,
7, 1, 7, 7, 2, 7, 5, 2, 6, 5, 8, 0, 0, 8, 1, 3, 7, 6, 1, 5, 6, 2,
0, 1, 5, 7, 8, 0, 3, 5, 0, 7, 5, 4, 4, 1, 5, 9, 5, 3, 7, 1, 7, 3,
5, 8, 5, 8, 5, 6, 1, 6, 7, 4, 3, 7, 0, 5, 4, 9, 3, 3, 6, 3, 5, 2,
9, 8, 9, 3, 9, 7, 3, 4, 9, 4, 3, 1])
#查看预测的概率结果
prob = gnb.predict_proba(Xtest) #每⼀列对应⼀个标签下的概率
prob
array([[0.00000000e+000, 4.69391744e-052, 1.74871280e-098, ...,
0.00000000e+000, 4.19588993e-033, 1.51751459e-119],
[0.00000000e+000, 1.00000000e+000, 9.26742456e-013, ...,
0.00000000e+000, 0.00000000e+000, 0.00000000e+000],
[0.00000000e+000, 0.00000000e+000, 3.73608152e-026, ...,
0.00000000e+000, 1.29541754e-039, 5.54684869e-077],
...,
[0.00000000e+000, 2.43314963e-047, 4.82483668e-305, ...,
2.31612692e-008, 1.23891596e-126, 2.87896140e-257],
[0.00000000e+000, 8.26462929e-129, 4.99150558e-012, ...,
0.00000000e+000, 4.01802372e-003, 6.19000712e-013],
[0.00000000e+000, 9.99929965e-001, 1.45462767e-013, ...,
5.05856094e-005, 1.94498169e-005, 3.42317317e-042]])
prob.shape
(540, 10)
prob[1,:].sum() #每一行的和都是一
1.000000000000003
prob.sum(axis=1)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
#使⽤混淆矩阵查看贝叶斯的分类结果
from sklearn.metrics import confusion_matrix as CM
CM(Ytest,Y_pred)
# 多分类状况下最佳的模型评估指标是混淆矩阵和整体的准确度
array([[47, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[ 0, 46, 2, 0, 0, 0, 0, 3, 6, 2],
[ 0, 2, 35, 0, 0, 0, 1, 0, 16, 0],
[ 0, 0, 1, 40, 0, 1, 0, 3, 4, 0],
[ 0, 0, 1, 0, 39, 0, 1, 4, 0, 0],
[ 0, 0, 0, 2, 0, 58, 1, 1, 1, 0],
[ 0, 0, 1, 0, 0, 1, 49, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 54, 0, 0],
[ 0, 3, 0, 1, 0, 0, 0, 2, 55, 0],
[ 1, 1, 0, 1, 2, 0, 0, 3, 7, 41]], dtype=int64)
探索贝叶斯:高斯朴素贝叶斯的拟合效果与运算速度
高斯朴素贝叶斯属于分类效果不算顶尖的模型,这个算法在拟合的时候还有哪些特性呢?比如,决策树是天生过拟合的模型,而支持向量机是不调参数的情况下就非常接近极限的模型。通过绘制高斯朴素贝叶斯的学习曲线与分类树,随机森林和支持向量机的学习曲线的对比,来探索高斯朴素贝叶斯算法在拟合上的性质。过去绘制学习曲线都是以算法类的某个参数的取值为横坐标,今天来使用sklearn中自带的绘制学习曲线的类learning_curve,在这个类
中执行交叉验证并从中获得不同样本量下的训练和测试的准确度。
#首先导入需要的模块和库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.tree import DecisionTreeClassifier as DTC
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
from time import time
import datetime
#定义绘制学习曲线的函数
def plot_learning_curve(estimator,title, X, y,
ax, #选择⼦子图
ylim=None, #设置纵坐标的取值范围
cv=None, #交叉验证
n_jobs=None #设定所要使用的线程
):
train_sizes, train_scores, test_scores = learning_curve(estimator, X, y,cv=cv,n_jobs=n_jobs)
ax.set_title(title)
if ylim is not None:
ax.set_ylim(*ylim)
ax.set_xlabel("Training examples")
ax.set_ylabel("Score")
ax.grid() #显示网格作为背景,不是必须的
ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-'
, color="r",label="Training score")
ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-'
, color="g",label="Test score")
ax.legend(loc="best")
return ax
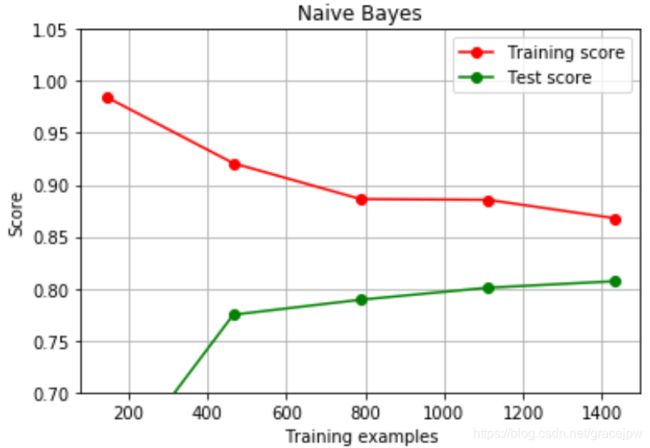
#这种学习曲线长什么样?
estimator = GaussianNB()
plt.figure()
plot_learning_curve(estimator, "Naive Bayes", X, y,
ax=plt.gca(), ylim = [0.7, 1.05],n_jobs=4, cv=5);
#导⼊数据,定义循环
digits = load_digits()
X, y = digits.data, digits.target
X.shape
(1797, 64)
X #是一个稀疏矩阵
array([[ 0., 0., 5., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 10., 0., 0.],
[ 0., 0., 0., ..., 16., 9., 0.],
...,
[ 0., 0., 1., ..., 6., 0., 0.],
[ 0., 0., 2., ..., 12., 0., 0.],
[ 0., 0., 10., ..., 12., 1., 0.]])
title = ["Naive Bayes","DecisionTree","SVM, RBFkernel","RandomForest","Logistic"]
model = [GaussianNB(),DTC(),SVC(gamma=0.001)
,RFC(n_estimators=50),LR(C=.1,solver="lbfgs")]
cv = ShuffleSplit(n_splits=50, test_size=0.2, random_state=0)
#进入循环,绘制学习曲线
fig, axes = plt.subplots(1,5,figsize=(30,6))
for ind,title_,estimator in zip(range(len(title)),title,model):
times = time()
plot_learning_curve(estimator, title_, X, y,
ax=axes[ind], ylim = [0.7, 1.05],n_jobs=4, cv=cv)
print("{}:{}".format(title_,datetime.datetime.fromtimestamp(time()-
times).strftime("%M:%S:%f")))
plt.show()
Naive Bayes:00:03:134390
DecisionTree:00:01:208254
SVM, RBFkernel:00:09:041815
RandomForest:00:08:045525
Logistic:00:18:910432
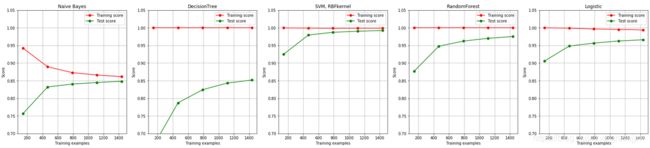
几个模型表现出的状态非常有意思。
首先返回的结果是各个算法的运行时间。可以看到,决策树和贝叶斯不相伯仲(如果你没有发现这个结果,那么可以多运行几次,你会发现贝叶斯和决策树的运行时间逐渐变得差不多)。决策树的运算效率随着样本量逐渐增大会越来越慢,但朴素贝叶斯却可以在很少的样本上获得不错的结果,因此,可以预料,随着样本量的逐渐增大,贝叶斯会逐渐变得比决策树更快。朴素贝叶斯计算速度远胜过SVM,随机森林这样复杂的模型,逻辑回归的运行受到最大迭代次数的强烈影响和输入数据的影响(逻辑回归一般在线性数据上运行都比较快,但在这里应该是受到了稀疏矩阵的影响)。因此在运算时间上,朴素贝叶斯还是十分有优势的。
紧接着,看一下每个算法在训练集上的拟合。手写数字数据集是一个较为简单的数据集,决策树,随机森林,SVC和逻辑回归都成功拟合了100%的准确率,但贝叶斯的最高训练准确率都没有超95%,
这也印证了朴素贝叶斯的分类效果其实不如其他分类器,贝叶斯天生学习能力比较弱。并且,随着训练样本量的逐渐增大,其他模型的训练拟合都保持在100%的水平,但贝叶斯的训练准确率却逐渐下降,这证明样本量量越大,贝叶斯需要学习的东西越多,对训练集的拟合程度也越差。反而比较少量的样本可以让贝叶斯有较高的训练准确率。
再来看看过拟合问题。首先一眼看到,所有模型在样本量量很少的时候都是出于过拟合状态的(训练集上表现好,测试集上表现糟糕),但随着样本的逐渐增多,过拟合问题都逐渐消失了,不过每个模型的处理手段不同。比较强大的分类器,比如SVM,随机森林林和逻辑回归,是依靠快速升高模型在测试集上的表现来减轻过拟合问题。相对的,决策树虽然也是通过提高模型在测试集上的表现来减轻过拟合,但随着训练样本的增加,模型在测试集上的表现改善却非常缓慢。朴素贝叶斯独树一帜,是依赖训练集上的准确率下降,测试集上的准确率上升来逐渐解决过拟合问题。