线段树详解(非递归版)
接上篇:https://blog.csdn.net/hpu2022/article/details/81946151
转自: https://blog.csdn.net/zearot/article/details/48299459
四:非递归原理
非递归的思路很巧妙,思路以及部分代码实现 来自 清华大学 张昆玮 《统计的力量》 ,有兴趣可以去找来看。
非递归的实现,代码简单(尤其是点修改和区间查询),速度快,建树简单,遍历元素简单。总之能非递归就非递归吧。
不过,要支持区间修改的话,代码会变得复杂,所以区间修改的时候还是要取舍。有个特例,如果区间修改,但是只需要
在所有操作结束之后,一次性下推所有标记,然后求结果,这样的话,非递归写起来也是很方便的。
下面先讲思路,再讲实现。
点修改:
非递归的思想总的来说就是自底向上进行各种操作。回忆递归线段树的点修改,首先由根节点1向下递归,找到对应的叶
节点,然后,修改叶节点的值,再向上返回,在函数返回的过程中,更新路径上的节点的统计信息。而非递归线段树的思路是,
如果可以直接找到叶节点,那么就可以直接从叶节点向上更新,而一个节点找父节点是很容易的,编号除以2再下取整就行了。
那么,如何可以直接找到叶节点呢?非递归线段树扩充了普通线段树(假设元素数量为n),使得所有非叶结点都有两个子结点且叶子结点都在同一层。
来观察一下扩充后的性质:

可以注意到红色和黑色数字的差是固定的,如果事先算出这个差值,就可以直接找到叶节点。
注意:区分3个概念:原数组下标,线段树中的下标和存储下标。
原数组下标,是指,需要维护统计信息(比如区间求和)的数组的下标,这里都默认下标从1开始(一般用A数组表示)
线段树下标,是指,加入线段树中某个位置的下标,比如,原数组中的第一个数,一般会加入到线段树中的第二个位置,
为什么要这么做,后面会讲。
存储下标,是指该元素所在的叶节点的编号,即实际存储的位置。
【在上面的图片中,红色为原数组下标,黑色为存储下标】
有了这3个概念,下面开始讲区间查询。
点修改下的区间查询:
首先,区间的划分没有变,现在关键是如何直接找到被分成的区间。原来是递归查找,判断左右子区间跟[L,R]是否有交点,
若有交点则向下递归。现在要非递归实现,这就是巧妙之处,见下图,以查询[3,11]为例子。
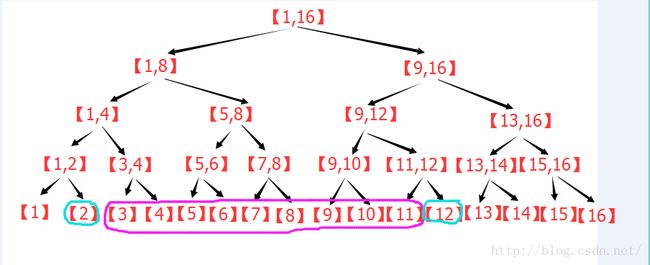
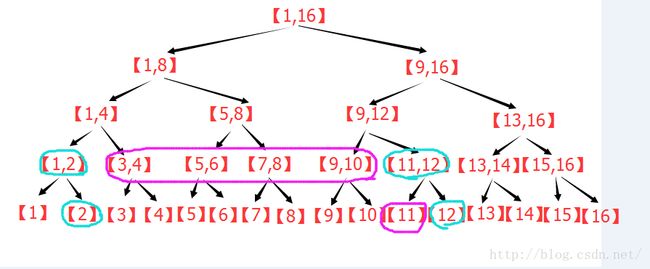
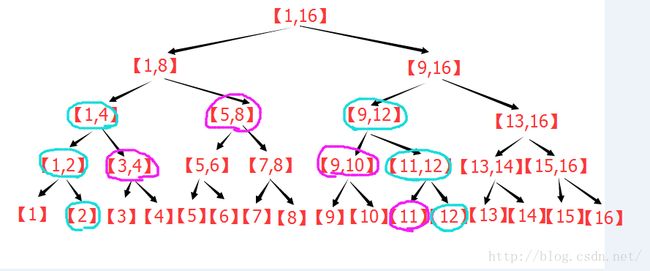
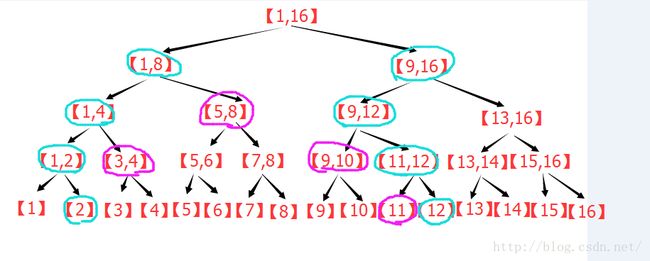
其实,容易发现,紫色部分的变化,跟原来分析线段树的区间分解的时候是一样的规则,图中多的蓝色是什么意思呢?
首先注意到,蓝色节点刚好在紫色节点的两端。
回忆一下,原来线段树在区间逐层被替代的过程中,哪些节点被留了下来?最左侧的节点,若为其父节点的右子节点,则留下。
最右侧的节点,若为其父节点的左子节点则留下。那么对于包裹着紫色的蓝色节点来看,刚好相反。
比如,以左侧的的蓝色为例,若该节点是其父节点的右子节点,就证明它右侧的那个紫色节点不会留下,会被其父替代,所以没必要在这一步计算,若该节点是其父节点的左子节点,就证明它右侧的那个紫色节点会留在这一层,所以必须在此刻计算,否则以后都不会再计算这个节点了。这样逐层上去,容易发现,对于左侧的蓝色节点来说,只要它是左子节点,那么就要计算对应的右子节点。同理,对于右侧的蓝色节点,只要它是右子节点,就需要计算它对应的左子节点。这个计算一直持续到左右蓝色节点的父亲为同一个的时候,才停止。于是,区间查询,其实就是两个蓝色节点一路向上走,在路径上更新答案。这样,区间修改就变成了两条同时向根走的链,明显复杂度O(log2(n))。并且可以非递归实现。
至此,区间查询也解决了,可以直接找到所有分解成的区间。
但是有一个问题,如果要查询[1,5]怎么办?[1]左边可是没地方可以放置蓝色节点了。
问题的解决办法简单粗暴,原数组的1到n就不存在线段树的1到n了,而是存在线段树的2到n+1,
而开始要建立一颗有n+2个元素的树,空出第一个和最后一个元素的空间。
现在来讲如何对线段树进行扩充。
再来看这个二叉树,令N=8;注意到,该树可以存8个元素,并且[1..7]是非叶节点,[8..15]是叶节点。
也就是说,左下角为N的二叉树,可以存N个元素,并且[1..N-1]是非叶节点,[N..2N-1]是叶节点。
并且,线段树下标+N-1=存储下标 (还记不记得原来对三个下标的定义)
这时,这个线段树存在两段坐标映射:
原数组下标+1=线段树下标
线段树下标+N-1=存储下标
联立方程得到:原数组下标+N=存储下标
于是从原数组下标到存储下标的转换及其简单。
下一个问题:N怎么确定?
上面提到了,N的含义之一是,这棵树可以存N个元素,也就是说N必须大于等于n+2
于是,N的定义,N是大于等于n+2的,某个2的次方。
区间修改下的区间查询:
方法之一:如果题目许可,可以直接打上标记,最后一次下推所有标记,然后就可以遍历叶节点来获取信息。
方法之二:如果题目查询跟修改混在一起,那么,采用标记永久化思想。也就是,不下推标记。
递归线段树是在查询区间的时候下推标记,使得到达每个子区间的时候,Sum已经是正确值。
非递归没法这么做,非递归是从下往上,遇到标记就更新答案。
这题是Add标记,一个区间Add标记表示这个区间所有元素都需要增加Add
Add含义不变,Add仍然表示本节点的Sum已经更新完毕,但是子节点的Sum仍需要更新.
现在就是如何在查询的时候根据标记更新答案。
观察下图:
左边的蓝色节点从下往上走,在蓝色节点到达[1,4]时,注意到,左边蓝色节点之前计算过的所有节点(即[3,4])都是目前蓝色节点的子节点也就是说,当前蓝色节点的Add是要影响这个节点已经计算过的所有数。多用一个变量来记录这个蓝色节点已经计算过多少个数,根据个数以及当前蓝色节点的Add,来更新最终答案。
更新完答案之后,再加上[5,8]的答案,同时当前蓝色节点计算过的个数要+4(因为[5,8]里有4个数)
然后当这个节点到达[1,8]节点时,可以更新[1,8]的Add.
这里,本来左右蓝色节点相遇之后就不再需要计算了,但是由于有了Add标记,左右蓝色节点的公共祖先上的Add标记会影响目前的所有数,所以还需要一路向上查询到根,沿路根据Add更新答案。
区间修改:
这里讲完了查询,再来讲讲修改,
修改的时候,给某个区间的Add加上了C,这个区间的子区间向上查询时,会经过这个节点,也就是会计算这个Add,但是
如果路径经过这个区间的父节点,就不会计算这个节点的Add,也就会出错。这里其实跟递归线段树一样,改了某个区间的Add
仍需要向上更新所有包含这个区间的Sum,来保持上面所有节点的正确性。
五:非递归实现
以下以维护数列区间和的线段树为例,演示最基本的非递归线段树代码。
(0)定义:
#define maxn 100007
int A[maxn],n,N;//原数组,n为原数组元素个数 ,N为扩充元素个数
int Sum[maxn<<2];//区间和
int Add[maxn<<2];//懒惰标记
(1)建树:
void Build(int n){
//计算N的值
N=1;while(N < n+2) N <<= 1;
//更新叶节点
for(int i=1;i<=n;++i) Sum[N+i]=A[i];//原数组下标+N=存储下标
//更新非叶节点
for(int i=N-1;i>0;--i){
//更新所有非叶节点的统计信息
Sum[i]=Sum[i<<1]+Sum[i<<1|1];
//清空所有非叶节点的Add标记
Add[i]=0;
}
}
(2)点修改:
A[L]+=C
void Update(int L,int C)
{
for(int s=N+L;s;s>>=1)
Sum[s]+=C;
}
(3)点修改下的区间查询:
求A[L..R]的和(点修改没有使用Add所以不需要考虑)
代码非常简洁,也不难理解,
s和t分别代表之前的论述中的左右蓝色节点,其余的代码根据之前的论述应该很容易看懂了。
s^t^1 在s和t的父亲相同时值为0,终止循环。
两个if是判断s和t分别是左子节点还是右子节点,根据需要来计算Sum
int Query(int L,int R){
int ANS=0;
for(int s=N+L-1,t=N+R+1;s^t^1;s>>=1,t>>=1){
if(~s&1) ANS+=Sum[s^1];
if( t&1) ANS+=Sum[t^1];
}
return ANS;
}
(4)区间修改:
A[L..R]+=C
void Update(int L,int R,int C){
int s,t,Ln=0,Rn=0,x=1;
//Ln: s一路走来已经包含了几个数
//Rn: t一路走来已经包含了几个数
//x: 本层每个节点包含几个数
for(s=N+L-1,t=N+R+1;s^t^1;s>>=1,t>>=1,x<<=1){
//更新Sum
Sum[s]+=C*Ln;
Sum[t]+=C*Rn;
//处理Add
if(~s&1) Add[s^1]+=C,Sum[s^1]+=C*x,Ln+=x;
if( t&1) Add[t^1]+=C,Sum[t^1]+=C*x,Rn+=x;
}
//更新上层Sum
for(;s;s>>=1,t>>=1){
Sum[s]+=C*Ln;
Sum[t]+=C*Rn;
}
}
(5)区间修改下的区间查询:
求A[L..R]的和
int Query(int L,int R){
int s,t,Ln=0,Rn=0,x=1;
int ANS=0;
for(s=N+L-1,t=N+R+1;s^t^1;s>>=1,t>>=1,x<<=1){
//根据标记更新
if(Add[s]) ANS+=Add[s]*Ln;
if(Add[t]) ANS+=Add[t]*Rn;
//常规求和
if(~s&1) ANS+=Sum[s^1],Ln+=x;
if( t&1) ANS+=Sum[t^1],Rn+=x;
}
//处理上层标记
for(;s;s>>=1,t>>=1){
ANS+=Add[s]*Ln;
ANS+=Add[t]*Rn;
}
return ANS;
}