第一章 Kubernetes基础笔记
一、Kubernetes概述
1、背景
kubernetes(简称k8s)是google基于Blog进行改进后,开源出来的一款“容器管理应用”。由于近几年来容器技术的火爆,许许多多的服务都不会直接部署在linux主机或各大云厂商的虚拟机上;利用Docker,将每个服务做成一个image,把他们跑在各自的Container中。
这样做的好处有非常多,比如环境配置隔离、服务启动快、移植便捷等等。但是使用的Container多到一定程度,就会带来容器管理上的问题:使用docker ps命令之后有一大堆Container,如果标识的不清楚也很容易混淆;某些分布式服务,需要将Docker部署到许多不同的机器上,这也会增加我们运维的难度。因此,我们现在需要一款“专门管理容器”的平台,为我们提供可视化界面,方便我们对各个容器进行管理。
k8s就是这样一款辅助我们管理容器的平台,支持管理在分布式环境(即多台服务器上)启动的 Container。
2、基础概念
2.1、Master
Cluster的大脑,主要职责是调度,可以运行多个master来保证高可用。
2.2、Node
职责是运行容器应用,Node由Master管理,负责监控并汇报容器的状态,同时根据Master的要求管理容器的生命周期。 ·
2.3、Pod
1)Pod是K8s的最小工作单元,每个Pod包含一个或多个容器。
- ·有些容器天生就是需要紧密联系,一起工作。Pod提供了比容器更高层次的抽象,K8s以Pod为最小单位进行调度、扩展、共享资源、管理生命周期。
- ·Pod中的所有容器使用同一个网络的namespace,即相同的IP地址和Port空间。它们可以直接用localhost通信。同样的,这些容器可以共享存储,当K8s挂载Volume到Pod上,本质上是将volume挂载到Pod中的每一个容器。
2)Pod 控制器
K8s通常不直接创建Pod,而是通过Controller来管理Pod。Controller中定义了pod的部署属性,比如几个副本、在什么样的Node上运行等。
K8s提供了多种Controller,包括Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job等。
- ·ReplicationController:副本控制器,确保Pod的数量始终保持设定的个数。也支持Pod的滚动更新。
- ·ReplicaSet:副本集,它不直接使用,有一个声明式更新的控制器叫Deployment来负责管理。但是Deployment只能负责管理那些无状态的应用。
- ·StatefulSet:有状态副本集,负责管理有状态的应用。
- ·DaemonSet,如果需要在每一个Node上只运行一个副本,而不是随意运行,就需要DaemonSet。
- ·Job:运行作业,对于时间不固定的操作,比如某个应用生成了一大堆数据集,现在需要临时启动一个Pod去清理这些数据集,清理完成后, 这个Pod就可以结束了。 这些不需要一直处于运行状态的应用,就用Job这个类型的控制器去控制。如果Pod运行过程中意外中止了,Job负责重启Pod。如果Pod任务执行完了,就不需要再启动了。
- ·Cronjob:周期性作业。
2.4、Service
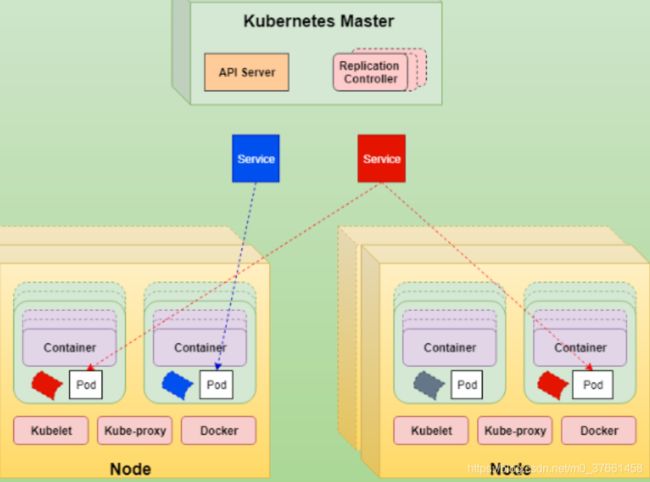
Deployement可以部署多个副本,每个Pod都有自己的副IP,外界如何访问这些副本。Pod会被频繁的销毁和重启,IP实时变化,不能用IP, 答案是通过service。K8s service定义了外界访问一组特定Pod的方式。service有自己的IP和端口,service为Pod提供了负载均衡。
2.5、Namespace:
Namespace将物理的Cluster逻辑上划分成多个虚拟Cluster,每个Cluster就是一个Namespace。不同的Namespace里的资源是完全隔离的。
- ·default:默认的namespace
- ·kube-system: K8s自己创建的的系统资源放到这个namespace
2.6、Cluster
Cluster 是计算、存储和网络资源的集合,Kubernetes利用这些资源运行各种基于容器的应用。
2.7、Node
工作节点,职责是运行容器应用。Node由Master管理,Node负责监控并汇报容器的状态,并根据Master的要求管理容器的生命周期。Node运行在Linux操作系统,可以是物理机或者是虚拟机。
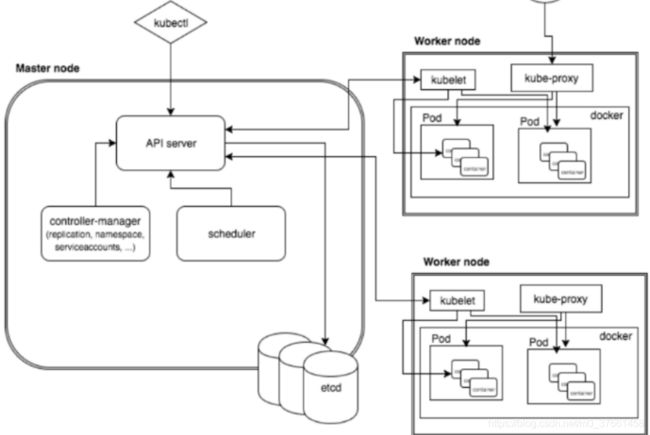
3、K8S的架构
Kubernetes集群包含有节点代理Kubelet和Master组件(APIs、scheduler、etc),下面是K8S的架构图。
Master节点包含API Server、Scheduler调度器、ControllerManager控制器管理器这三个核心的组件。
Node节点包含的核心组件有Kubelet、Docker容器引擎、Kube-proxy
3.1、API Server(kube-apiserver)
提供了HTTP/HTTPS RESTful API,即Kubernetes API。 API server是Kubernetes Cluster的前端接口。其他客户端工具(CLI或UI)以及K8S其它组件可以通过它管理Cluster资源。
3.2、Scheduler(kube-scheduler)
调度器,它负责决定将Pod放在哪个Node上运行。调度时候考虑Cluster拓扑,各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
3.3、Controller-Manager
负责监控每一个Controller(控制器)的健康状态,并确保控制器是健康的。而控制器是确保Pod健康的组件。
3.4、etcd
负责保存K8s Cluster的配置信息和各种资源的状态信息。当数据发生变化时,etcd可以快速的通知K8s组件。
3.5、Pod网络
Pod能通信,k8s cluster必须部署Pod网络(比如flannel是其中一个方案)
3.6、Kubelet
是Node的agent,当scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image、volume等)发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行状态。
3.7、Kube-proxy
service在逻辑上代表了后端的多个Pod,外界通过service访问Pod。service接收到的请求是如何转发到Pod的呢?这就是kube-proxy要完成的工作。每个node都运行kube-proxy服务,它负责将访问service的TCP/UDP数据流转发到后端容器。如果有多个副本,kube-proxy实现负载均衡。
二、Kubernetes集群搭建
1、环境准备
本次使用docker 18.09.9和kubelet-1.16.4,要求centos7.6以上版本
[root@localhost ~]# cat /etc/centos-release
CentOS Linux release 7.6.1810 (Core)
1.1 关闭selinux
查看selinux是否关闭
[root@localhost ~]# getenforce
Disabled
先设置临时关闭:setenforce 0
永久关闭:vi /etc/sysconfig/selinux
设置SELINUX=disabled
1.2 、关闭swap
k8s要求系统关闭,否则安装过程会报错,查看系统是否关闭了swap

临时禁用:swapoff -a
永久禁用:sed -i.bak '/swap/s/^/#/' /etc/fstab ##注释掉swap那一行
作用就是修改/etc/fstab配置为如下:
vi /etc/fstab
注释掉代码:
#/dev/mapper/centos-swap swap swap defaults 0 0
1.3、配置ip_forward转发
ip_forward配置文件当前内容为0,表示禁止数据包转发,将其修改为1表示允许
命令:echo "1" > /proc/sys/net/ipv4/ip_forward
1.4、更新docker源与k8s的yum源
为了一次性配置好下载源,我们一次性修改好centos7软件源,docker源,k8s源
先清除掉系统自带配置 cd /etc/yum.repos.d/
[root@bogon ~]# cd /etc/yum.repos.d/
[root@bogon yum.repos.d]# ll
total 36
-rw-r--r--. 1 root root 1664 Nov 23 2018 CentOS-Base.repo
-rw-r--r--. 1 root root 1309 Nov 23 2018 CentOS-CR.repo
-rw-r--r--. 1 root root 649 Nov 23 2018 CentOS-Debuginfo.repo
-rw-r--r--. 1 root root 314 Nov 23 2018 CentOS-fasttrack.repo
-rw-r--r--. 1 root root 630 Nov 23 2018 CentOS-Media.repo
-rw-r--r--. 1 root root 1331 Nov 23 2018 CentOS-Sources.repo
-rw-r--r--. 1 root root 5701 Nov 23 2018 CentOS-Vault.repo
-rw-r--r-- 1 root root 2640 Dec 4 15:58 docker-ce.repo
[root@bogon yum.repos.d]# rm -rf *
[root@bogon yum.repos.d]# ll
total 01)下载centos7的源和docker源:
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -P /etc/yum.repos.d/ http://mirrors.aliyun.com/repo/epel-7.repo
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
结果如下:
[root@bogon yum.repos.d]# ll
total 12
-rw-r--r-- 1 root root 2523 Jun 16 2018 CentOS-Base.repo
-rw-r--r-- 1 root root 2640 Mar 16 18:38 docker-ce.repo
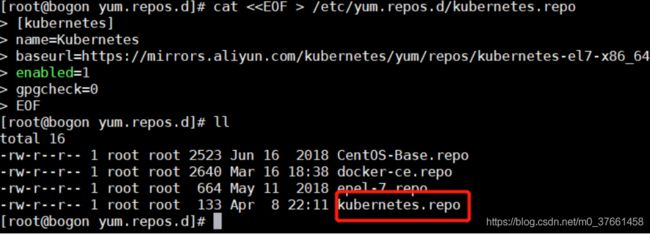
-rw-r--r-- 1 root root 664 May 11 2018 epel-7.repo2)配置k8s源
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
EOF
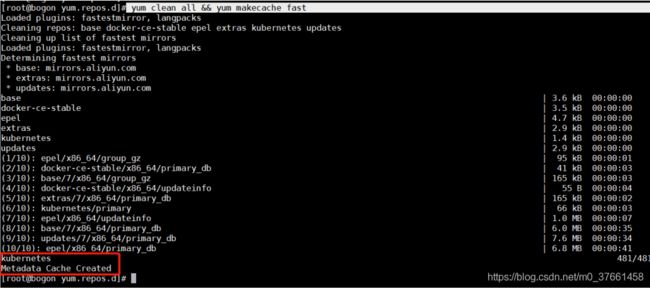
3)刷新yum缓存
命令:yum clean all && yum makecache fast
1.5、安装docker
docker使用版本18.09.9
命令:yum install docker-ce-18.09.9 docker-ce-cli-18.09.9 containerd.io -y
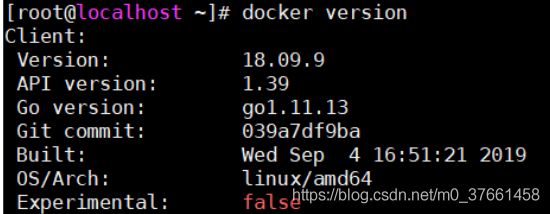
k8s运行要求docker的--cgroup-driver=systemd
cat /etc/docker/daemon.json
[root@bogon yum.repos.d]# cat /etc/docker/daemon.json
{
"registry-mirrors": ["https://registry.docker-cn.com","http://hub-mirror.c.163.com"],
"insecure-registries":["192.168.30.161:5000"]
}启动docker并设置开机启动:
命令:systemctl enable docker && systemctl start docker
1.6、安装k8s组件
命令:yum install -y kubelet-1.16.4 kubeadm-1.16.4 kubectl-1.16.4

设置开机启动:
systemctl enable kubelet && systemctl start kubelet
添加kubectl上下文到环境中:
echo "source <(kubectl completion bash)" >> ~/.bash_profile
source .bash_profile
在家目录中,配置生效:
[root@bogon ~]# echo "source <(kubectl completion bash)" >> ~/.bash_profile
[root@bogon ~]# source .bash_profile
1.7、内核参数修改
k8s网络一般使用flannel,该网络需要设置内核参数bridge-nf-call-iptables=1
添加参数配置文件:vi /etc/sysctl.d/k8s.conf
[root@bogon ~]# cat /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
执行命令:
sysctl -p /etc/sysctl.d/k8s.conf
至此,环境准备工作完毕。
1.8、内核参数修改失败常见问题
有些系统执行sysctl -p /etc/sysctl.d/k8s.conf会报异常,一般是因为修改这个参数需要系统有br_netfilter 模块,使用lsmod |grep br_netfilter命令,查看系统里是否有br_netfilter模块。
没有则新增br_netfilter模块:modprobe br_netfilter
上述方式重启后无效。需要配置系统启动加载脚本使其永久生效:
1)先加开机启动动作:
vi /etc/rc.sysinit
# !/bin/bash
for file in /etc/sysconfig/modules/*.modules;
do[-x $file] && $file
done
2)再做加载模块动作:
[root@bogon ~]# vi /etc/sysconfig/modules/br_netfilter.modules
添加内容:modprobe br_netfilter
3)再增加执行权限:
[root@bogon ~]# chmod 755 /etc/sysconfig/modules/br_netfilter.modules
2、Master节点配置
2.1、Master节点初始化
命令:kubeadm init --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.16.4 --pod-network-cidr=10.244.0.0/16
这一步,如果出现下面错误,则是前面的1.6节点内核没有配置,正常情况如下:
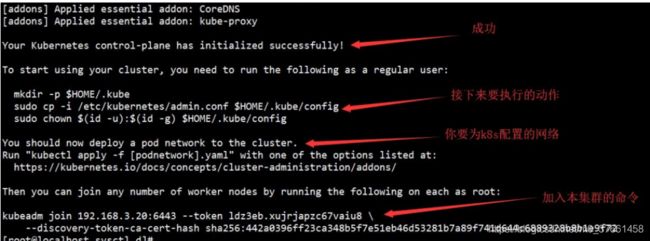
出现这一步,恭喜你,已经成功一大半了!,复制加入节点的命令。
这里本地安装的信息如下:
命令:kubeadm join 192.168.30.161:6443 --token k1pe7l.tqze8jxrltk9elds --discovery-token-ca-cert-hash sha256:865e1169ec58773850b496678c1b3ab252683b014ef899e68ccf4ac826528412
接下来,我们按它的提示执行操作:
mkdir -p $HOME/.kube
执行提示操作:
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config

备注:
kubernetes 坑人的错误!!!Unable to connect to the server: x509: certificate signed by unknown authority
问题复现:
昨天按照教程搭建了一个集群,今天想重新实验下,于是执行kubeadm reset命令清除集群所有的配置。
接着按照部署的常规流程执行:kubeadm init --kubernetes-version=v1.14.3 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=0.0.0.0命令创建集群。然后执行以下几个命令:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config接着当我执行kubectl get nodes等命令时,所有的命令都会打印出错误:Unable to connect to the server: x509: certificate signed by unknown authority (possibly because of “crypto/rsa: verification error” while trying to verify candidate authority certificate “kubernetes”)
当在这些 kubectl 命令后加入 --insecure-skip-tls-verify 参数时,就会报如下错误:error: You must be logged in to the server (Unauthorized)
问题解决:mkdir -p $HOME/.kube
这几个命令会创建一个目录,并复制几个配置文件,重新创建集群时,这个目录还是存在的,于是我尝试在执行这几个命令前先执行rm -rf $HOME/.kube命令删除这个目录,最后终于解决了这个问题!!!
2.2、添加flannel的网络
按照master的提示,我们接下来应该配置一个pod network。但是这里有个大坑,因为国内网络不通的原因,导致该配置文件无法下载,所以此操作无法完成。你只能选择私人定制的下面这个文件来完成。上传文件到你的系统后,使用下面命令:
执行命令:kubectl apply -f hankin-flannel.yml
[root@localhost ~]# kubectl apply -f hankin-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
[root@localhost ~]#至此,大功告成
2.3、查看集群
查看k8s集群:kubectl get nodes

3、work节点初始化
work节点的配置,相对master来说简单许多,只需要规划好节点的名称即可。
注意master节点初始化完成之后会有其他节点加入集群的提示命令。
3.1、设置机器名
设置一个机器名为work1(192.168.30.162)
[root@bogon ~]# hostnamectl set-hostname work1
配置对应的ip:vi /etc/hosts
添加配置:192.168.30.162 work1

3.2、加入集群
在要加入的工作节点机器上,执行master初始化时提示的join语句,即加到master的管辖内。
这里将192.168.30.162(work1)、192.168.30.163(work2)两台机器作为work加入集群。
执行master节点初始化完成后生成的加入集群命令:
kubeadm join 192.168.30.161:6443 --token k1pe7l.tqze8jxrltk9elds --discovery-token-ca-cert-hash sha256:865e1169ec58773850b496678c1b3ab252683b014ef899e68ccf4ac826528412
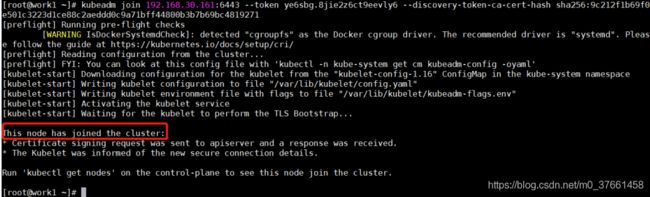
回到master节点再次查看集群:kubectl get nodes

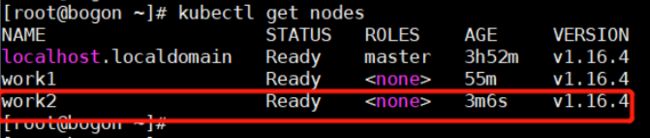
同样的操作将节点work2(192.168.30.163)加入到集群:kubectl get nodes
4、备注:
4.1、加入master节点命令失效问题
master中的节点认证信息24小时会失效,可以重新生成(master端操作)
重新生成用于节点加入集群的认证命令
1)创建token:
[root@master ~]# kubeadm token create
pno0i6.hmhqm0qrf8n4hf4e
2)创建新的sha:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der sha256 -hex | sed 's/^.* //'
3)加入集群(node操作)
kubeadm join 172.16.20.102:6443 --token [token] --discovery-token-ca-cert-hash sha256:[sha值]
4.2、初始化Kubernetes端口占用问题
解决方案:发现杀死进程都没有用,最终重启一下kubeadm就可以了,如下:
kubeadm reset
脱离集群命令也是这个
4.3、重启kubelet:
systemctl daemon-reload
systemctl restart kubelet