Python_美多商城后台管理
项目环境搭建
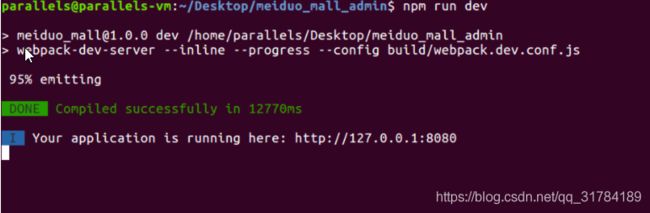
1、前端代码的运行
进入meiduo_mall_admin文件目录下,执行如下指令
npm run dev
出现如下图所示,表示运行成功:
2、后端代码的运行
1、导入虚拟环境文件
pip install -r requeriments.txt
2、进入数据库创建meiduo数据库
mysql -uroot -p
create database meiduo charset=utf8;
3、导入数据
mysql -uroot -p meiduo < dump.sql
4、运行
python manage.py runserver====================================
登录
后台管理中我们首先需要完成登录功能,我们可以通过改写美多表单登录来完成相应的功能。
在后台登录中,由于我们前端服务和后端服务的域名不一样,所以我们首先解决跨域问题。
登后的状态保持我们采用jwt
浏览器的同源策略
1995年,同源政策由 Netscape 公司引入浏览器。目前,所有浏览器都实行这个政策。
同源策略是浏览器的一个安全功能,不同源的客户端脚本(js文件)在没有明确授权的情况下,不能读写对方资源。只有同一个源的脚本赋予dom、读写cookie、session、ajax等操作的权限。
url由协议、域名、端口和路径组成,如果两个url的协议、域名和端口相同,则这两个url是同源的。
举例来说,http://www.example.com/dir/page.html这个网址,协议是http://,域名是www.example.com,端口是80(默认端口可以省略)。它的同源情况如下。
| url | 是否同源 | 原因 |
|---|---|---|
| http://www.example.com/dir2/other.html | 是 | 协议、端口、主机相同 |
| https://example.com/dir/other.html | 否 | 不同的协议(https) |
| http://www.example.com:81 | 否 | 端口不同(81) |
| http://news.example.com/ | 否 | 域名不同 |
同源政策的目的,是为了保证用户信息的安全,防止恶意的网站窃取数据。
设想这样一种情况:A网站是一家银行,用户登录以后,又去浏览其他网站。如果其他网站可以读取A网站的 Cookie,会发生什么?
很显然,如果 Cookie 包含隐私(比如存款总额),这些信息就会泄漏。更可怕的是,Cookie 往往用来保存用户的登录状态,如果用户没有退出登录,其他网站就可以冒充用户,为所欲为。因为浏览器同时还规定,提交表单不受同源政策的限制。
由此可见,"同源政策"是必需的,否则 Cookie 可以共享,互联网就毫无安全可言了。
===========================================
跨域CORS
我们的前端和后端分别是两个不同的端口
| 位置 | 域名 |
|---|---|
| 前端服务 | 127.0.0.1:8080 |
| 后端服务 | 127.0.0.1:8000 |

现在,前端与后端分别是不同的端口,这就涉及到跨域访问数据的问题,因为浏览器的同源策略,默认是不支持两个不同域名间相互访问数据,而我们需要在两个域名间相互传递数据,这时我们就要为后端添加跨域访问的支持。
我们使用django-cors-headers来解决后端对跨域访问的支持。
使用django-cors-headers扩展
参考文档https://github.com/ottoyiu/django-cors-headers/
安装
pip install django-cors-headers
添加应用
INSTALLED_APPS = (
...
'corsheaders',
...
)
中间层设置
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
...
]
添加白名单
# CORS
CORS_ORIGIN_WHITELIST = (
'127.0.0.1:8080',
'localhost:8080',
'www.meiduo.site:8080',
'api.meiduo.site:8000'
)
CORS_ALLOW_CREDENTIALS = True # 允许携带cookie
- 凡是出现在白名单中的域名,都可以访问后端接口
- CORS_ALLOW_CREDENTIALS 指明在跨域访问中,后端是否支持对cookie的操作。
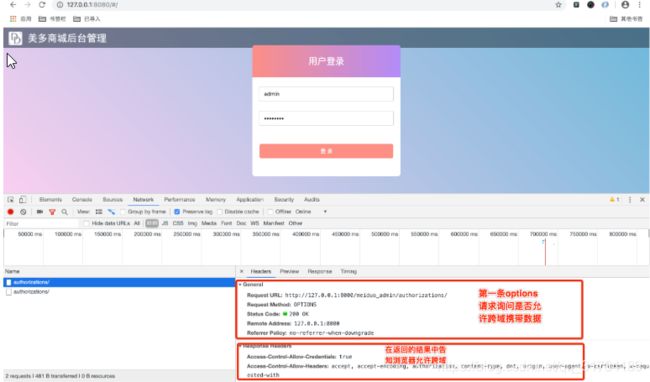
跨域实现流程为
1、浏览器会第一次先发送options请求询问后端是否允许跨域,后端查询白名单中是否有这两个域名
2、如过域名在白名单中则在响应结果中告知浏览器允许跨域
3、浏览器第二次发送post请求,携带用户登录数据到后端,完成登录验证操作
options请求
post请求

JWT
在用户注册或登录后,我们想记录用户的登录状态,或者为用户创建身份认证的凭证。我们不再使用Session认证机制,而使用Json Web Token认证机制。
什么是JWT
Json web token (JWT), 是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准((RFC 7519).该token被设计为紧凑且安全的,特别适用于分布式站点的单点登录(SSO)场景。JWT的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源,也可以增加一些额外的其它业务逻辑所必须的声明信息,该token也可直接被用于认证,也可被加密。
起源
说起JWT,我们应该来谈一谈基于token的认证和传统的session认证的区别。
传统的session认证
我们知道,http协议本身是一种无状态的协议,而这就意味着如果用户向我们的应用提供了用户名和密码来进行用户认证,那么下一次请求时,用户还要再一次进行用户认证才行,因为根据http协议,我们并不能知道是哪个用户发出的请求,所以为了让我们的应用能识别是哪个用户发出的请求,我们只能在服务器存储一份用户登录的信息,这份登录信息会在响应时传递给浏览器,告诉其保存为cookie,以便下次请求时发送给我们的应用,这样我们的应用就能识别请求来自哪个用户了,这就是传统的基于session认证。
但是这种基于session的认证使应用本身很难得到扩展,随着不同客户端用户的增加,独立的服务器已无法承载更多的用户,而这时候基于session认证应用的问题就会暴露出来.
基于session认证所显露的问题
Session: 每个用户经过我们的应用认证之后,我们的应用都要在服务端做一次记录,以方便用户下次请求的鉴别,通常而言session都是保存在内存中,而随着认证用户的增多,服务端的开销会明显增大。
扩展性: 用户认证之后,服务端做认证记录,如果认证的记录被保存在内存中的话,这意味着用户下次请求还必须要请求在这台服务器上,这样才能拿到授权的资源,这样在分布式的应用上,相应的限制了负载均衡器的能力。这也意味着限制了应用的扩展能力。
CSRF: 因为是基于cookie来进行用户识别的, cookie如果被截获,用户就会很容易受到跨站请求伪造的攻击。
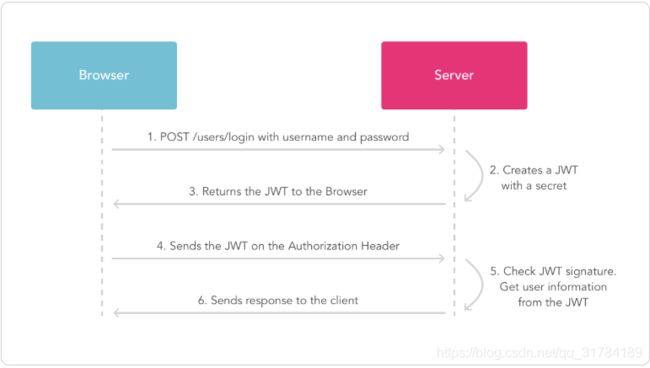
基于token的鉴权机制
基于token的鉴权机制类似于http协议也是无状态的,它不需要在服务端去保留用户的认证信息或者会话信息。这就意味着基于token认证机制的应用不需要去考虑用户在哪一台服务器登录了,这就为应用的扩展提供了便利。
流程上是这样的:
- 用户使用用户名密码来请求服务器
- 服务器进行验证用户的信息
- 服务器通过验证发送给用户一个token
- 客户端存储token,并在每次请求时附送上这个token值
- 服务端验证token值,并返回数据
这个token必须要在每次请求时传递给服务端,它应该保存在请求头里, 另外,服务端要支持CORS(跨来源资源共享)策略,一般我们在服务端这么做就可以了Access-Control-Allow-Origin: *。
那么我们现在回到JWT的主题上。
JWT长什么样?
JWT是由三段信息构成的,将这三段信息文本用.链接一起就构成了Jwt字符串。就像这样:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
JWT的构成
第一部分我们称它为头部(header),第二部分我们称其为载荷(payload, 类似于飞机上承载的物品),第三部分是签证(signature).
header
jwt的头部承载两部分信息:
- 声明类型,这里是jwt
- 声明加密的算法 通常直接使用 HMAC SHA256
完整的头部就像下面这样的JSON:
{
'typ': 'JWT',
'alg': 'HS256'
}
然后将头部进行base64加密(该加密是可以对称解密的),构成了第一部分.
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
payload
载荷就是存放有效信息的地方。这个名字像是特指飞机上承载的货品,这些有效信息包含三个部分
- 标准中注册的声明
- 公共的声明
- 私有的声明
标准中注册的声明 (建议但不强制使用) :
- iss: jwt签发者
- sub: jwt所面向的用户
- aud: 接收jwt的一方
- exp: jwt的过期时间,这个过期时间必须要大于签发时间
- nbf: 定义在什么时间之前,该jwt都是不可用的.
- iat: jwt的签发时间
- jti: jwt的唯一身份标识,主要用来作为一次性token,从而回避重放攻击。
公共的声明 : 公共的声明可以添加任何的信息,一般添加用户的相关信息或其他业务需要的必要信息.但不建议添加敏感信息,因为该部分在客户端可解密.
私有的声明 : 私有声明是提供者和消费者所共同定义的声明,一般不建议存放敏感信息,因为base64是对称解密的,意味着该部分信息可以归类为明文信息。
定义一个payload:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
然后将其进行base64加密,得到JWT的第二部分。
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
signature
JWT的第三部分是一个签证信息,这个签证信息由三部分组成:
- header (base64后的)
- payload (base64后的)
- secret
这个部分需要base64加密后的header和base64加密后的payload使用.连接组成的字符串,然后通过header中声明的加密方式进行加盐secret组合加密,然后就构成了jwt的第三部分。
// javascript
var encodedString = base64UrlEncode(header) + '.' + base64UrlEncode(payload);
var signature = HMACSHA256(encodedString, 'secret'); // TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
将这三部分用.连接成一个完整的字符串,构成了最终的jwt:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.TJVA95OrM7E2cBab30RMHrHDcEfxjoYZgeFONFh7HgQ
注意:secret是保存在服务器端的,jwt的签发生成也是在服务器端的,secret就是用来进行jwt的签发和jwt的验证,所以,它就是你服务端的私钥,在任何场景都不应该流露出去。一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。
如何应用
一般是在请求头里加入Authorization,并加上Bearer标注:
fetch('api/user/1', {
headers: {
'Authorization': 'Bearer ' + token
}
})
服务端会验证token,如果验证通过就会返回相应的资源。整个流程就是这样的:
总结
优点
- 因为json的通用性,所以JWT是可以进行跨语言支持的,像JAVA,JavaScript,NodeJS,PHP等很多语言都可以使用。
- 因为有了payload部分,所以JWT可以在自身存储一些其他业务逻辑所必要的非敏感信息。
- 便于传输,jwt的构成非常简单,字节占用很小,所以它是非常便于传输的。
- 它不需要在服务端保存会话信息, 所以它易于应用的扩展
安全相关
- 不应该在jwt的payload部分存放敏感信息,因为该部分是客户端可解密的部分。
- 保护好secret私钥,该私钥非常重要。
- 如果可以,请使用https协议
==============================================
Django REST framework JWT
我们在验证完用户的身份后(检验用户名和密码),需要向用户签发JWT,在需要用到用户身份信息的时候,还需核验用户的JWT。
关于签发和核验JWT,我们可以使用Django REST framework JWT扩展来完成。
文档网站http://getblimp.github.io/django-rest-framework-jwt/
安装配置
安装
pip install djangorestframework-jwt
配置
REST_FRAMEWORK = {
'DEFAULT_AUTHENTICATION_CLASSES': (
'rest_framework_jwt.authentication.JSONWebTokenAuthentication',
'rest_framework.authentication.SessionAuthentication',
'rest_framework.authentication.BasicAuthentication',
),
}
JWT_AUTH = {
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
}
- JWT_EXPIRATION_DELTA 指明token的有效期
账号登录
1. 业务说明
验证用户名和密码,验证成功后,为用户签发JWT,前端将签发的JWT保存下来。
2. 后端接口设计
请求方式: POST meiduo_admin/authorizations/
请求参数: JSON 或 表单
| 参数名 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| password | str | 是 | 密码 |
返回数据: JSON
{
"username": "python",
"user_id": 1,
"token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyX2lkIjo5LCJ1c2VybmFtZSI6InB5dGhvbjgiLCJleHAiOjE1MjgxODI2MzQsImVtYWlsIjoiIn0.ejjVvEWxrBvbp18QIjQbL1TFE0c0ejQgizui_AROlAU"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| id | int | 是 | 用户id |
| token | str | 是 | 身份认证凭据 |
3. 后端实现
Django REST framework JWT提供了登录签发JWT的视图,可以直接使用
from rest_framework_jwt.views import obtain_jwt_token
urlpatterns = [
url(r'^authorizations/$', obtain_jwt_token),
]
但是默认的返回值仅有token,我们还需在返回值中增加username和user_id。
通过修改该视图的返回值可以完成我们的需求。
在users/utils.py 中,创建
def jwt_response_payload_handler(token, user=None, request=None):
"""
自定义jwt认证成功返回数据
"""
return {
'token': token,
'id': user.id,
'username': user.username
}
修改配置文件
# JWT配置
JWT_AUTH = {
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=1),
'JWT_RESPONSE_PAYLOAD_HANDLER': 'meiduo_admin.utils.jwt_response.jwt_response_payload_handler',
}
4. 增加支持管理员用户登录账号
JWT扩展的登录视图,在收到用户名与密码时,也是调用Django的认证系统中提供的authenticate()来检查用户名与密码是否正确。
我们可以通过修改Django认证系统的认证后端(主要是authenticate方法)来支持登录账号既可以是用户名也可以是手机号。
修改Django认证系统的认证后端需要继承django.contrib.auth.backends.ModelBackend,并重写authenticate方法。
authenticate(self, request, username=None, password=None, **kwargs)方法的参数说明:
- request 本次认证的请求对象
- username 本次认证提供的用户账号
- password 本次认证提供的密码
我们想要让管理员用户才能登录我们的admin后台,这时我们就要修改django原有的用户验证方法。
重写authenticate方法的思路:
- 根据username参数查找用户User对象,在查询条件中在加上is_staff=True的条件
- 若查找到User对象,调用User对象的check_password方法检查密码是否正确
在meiduo_mall/utils/authenticate.py中编写:
from django.contrib.auth.backends import ModelBackend
import re
from users.models import User
class MeiduoModelBackend(ModelBackend):
def authenticate(self, request, username=None, password=None, **kwargs):
# 判断是否通过vue组件发送请求
if request is None:
try:
user = User.objects.get(username=username, is_staff=True)
except:
return None
# 判断密码
if user.check_password(password):
return user
else:
# 变量username的值,可以是用户名,也可以是手机号,需要判断,再查询
try:
# if re.match(r'^1[3-9]\d{9}$', username):
# user = User.objects.get(mobile=username)
# else:
# user = User.objects.get(username=username)
user = User.objects.get(username=username)
except:
# 如果未查到数据,则返回None,用于后续判断
try:
user = User.objects.get(mobile=username)
except:
return None
# return None
# 判断密码
if user.check_password(password):
return user
else:
return None
在配置文件中告知Django使用我们自定义的认证后端
前端保存token
我们可以将JWT保存在cookie中,也可以保存在浏览器的本地存储里,我们保存在浏览器本地存储中
浏览器的本地存储提供了sessionStorage 和 localStorage 两种:
- sessionStorage 浏览器关闭即失效
- localStorage 长期有效
使用方法
sessionStorage.变量名 = 变量值 // 保存数据
sessionStorage.变量名 // 读取数据
sessionStorage.clear() // 清除所有sessionStorage保存的数据
localStorage.变量名 = 变量值 // 保存数据
localStorage.变量名 // 读取数据
localStorage.clear() // 清除所有localStorage保存的数据
var vm = new Vue({
...
methods: {
...
on_submit: function(){
axios.post(...)
.then(response => {
// 记录用户的登录状态
sessionStorage.clear();
localStorage.clear();
localStorage.token = response.data.token;
localStorage.username = response.data.username;
localStorage.user_id = response.data.id;
location.href = '/index.html';
})
.catch(...)
}
}
})===========================================
数据统计

在进入到后台页面后,首先我们需要完成如下功能:
1、用户总数统计
2、日增用户统计
3、日活用户统计
4、下单用户统计
5、月新增用户统计
6、商品访问量统计
========================================
用户总量统计
接口分析
请求方式: GET /meiduo_admin/statistical/total_count/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"count": "总用户量",
"date": "日期"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 总用户量 |
| date | date | 是 | 日期 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
class UserTotalCountView(APIView):
# 指定管理员权限
permission_classes = [IsAdminUser]
def get(self,request):
# 获取当前日期
now_date=date.today()
# 获取所有用户总数
count= User.objects.all().count()
return Response({
'count':count,
'date':now_date
})--------------------------------------------
日增用户统计
接口分析
请求方式: GET /meiduo_admin/statistical/day_increment/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"count": "新增用户量",
"date": "日期"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 新增用户量 |
| date | date | 是 | 日期 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
class UserDayCountView(APIView):
# 指定管理员权限
permission_classes = [IsAdminUser]
def get(self,request):
# 获取当前日期
now_date=date.today()
# 获取当日注册用户数量 date_joined 记录创建账户时间
count=User.objects.filter(date_joined__gte=now_date).count()
return Response({
"count":count,
"date" : now_date
})---------------------------------------------
日活跃用户统计
接口分析
请求方式:GET /meiduo_admin/statistical/day_active/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"count": "活跃用户量",
"date": "日期"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 活跃用户量 |
| date | date | 是 | 日期 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
class UserActiveCountView(APIView):
# 指定管理员权限
permission_classes = [IsAdminUser]
def get(self,request):
# 获取当前日期
now_date=date.today()
# 获取当日登录用户数量 last_login记录最后登录时间
count=User.objects.filter(last_login__gte=now_date).count()
return Response({
"count":count,
"date" : now_date
})----------------------------------------------
日下单用户量统计
接口分析
请求方式:GET /meiduo_admin/statistical/day_orders/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"count": "下单用户量",
"date": "日期"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 下单用户量 |
| date | date | 是 | 日期 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
class UserOrderCountView(APIView):
# 指定管理员权限
permission_classes = [IsAdminUser]
def get(self,request):
# 获取当前日期
now_date=date.today()
# 获取当日下单用户数量 orders__create_time 订单创建时间
count=User.objects.filter(orders__create_time__gte=now_date).count()
return Response({
"count":count,
"date" : now_date
})=======================================
日分类商品访问量月增用户统计
接口分析
请求方式:GET /meiduo_admin/statistical/month_increment/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"count": "用户量",
"date": "日期"
},
{
"count": "用户量",
"date": "日期"
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 新增用户量 |
| date | date | 是 | 日期 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
class UserMonthCountView(APIView):
# 指定管理员权限
permission_classes = [IsAdminUser]
def get(self, request):
# 获取当前日期
now_date = date.today()
# 获取一个月前日期
start_date = now_date - timedelta(29)
# 创建空列表保存每天的用户量
date_list = []
for i in range(30):
# 循环遍历获取当天日期
index_date = start_date + timedelta(days=i)
# 指定下一天日期
cur_date = start_date + timedelta(days=i + 1)
# 查询条件是大于当前日期index_date,小于明天日期的用户cur_date,得到当天用户量
count = User.objects.filter(date_joined__gte=index_date, date_joined__lt=cur_date).count()
date_list.append({
'count': count,
'date': index_date
})
return Response(date_list)=============================
日分类商品访问量
接口分析
请求方式: GET /meiduo_admin/statistical/goods_day_views/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"category": "分类名称",
"count": "访问量"
},
{
"category": "分类名称",
"count": "访问量"
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| category | int | 是 | 分类名称 |
| count | int | 是 | 访问量 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
from goods.models import GoodsVisitCount
class GoodsDayView(APIView):
def get(self,request):
# 获取当天日期
now_date=date.today()
# 获取当天访问的商品分类数量信息
data=GoodsVisitCount.objects.filter(date=now_date)
# 序列化返回分类数量
ser=GoodsSerializer(data,many=True)
return Response(ser.data)
序列化器的定义
class GoodsSerializer(serializers.ModelSerializer):
# 指定返回分类名称
category=serializers.StringRelatedField(read_only=True)
class Meta:
model=GoodsVisitCount
fields=('count','category')================================
用户管理

在用户页面我们需要完成两个功能:
1、用户信息的查询获取
2、增加用户
======================================
用户的查询获取
接口分析
请求方式:GET /meiduo_admin/users/?keyword=<搜索内容>&page=<页码>&pagesize=<页容量>
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| keyword | str | 否 | 搜索用户名 |
| page | int | 否 | 页码 |
| pagesize | int | 否 | 页容量 |
返回数据: JSON
{
"counts": "用户总量",
"lists": [
{
"id": "用户id",
"username": "用户名",
"mobile": "手机号",
"email": "邮箱"
},
...
],
"page": "页码",
"pages": "总页数",
"pagesize": "页容量"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 用户总量 |
| Lists | 数组 | 是 | 用户信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
from rest_framework.generics import ListAPIView
from meiduo_admin.serializers.user import UserSerializer
from meiduo_admin.utils.pagenum import PageNum
from users.models import User
class UserView(ListAPIView):
# 指定使用的序列化器
serializer_class = UserSerializer
# 指定分页器
pagination_class = PageNum
# 重写get_queryset方法,根据前端是否传递keyword值返回不同查询结果
def get_queryset(self):
# 获取前端传递的keyword值
keyword = self.request.query_params.get('keyword')
# 如果keyword是空字符,则说明要获取所有用户数据
if keyword is '' or keyword is None:
return User.objects.all()
else:
return User.objects.filter(username=keyword)
指定序列化器:
from rest_framework import serializers
from users.models import User
class UserSerializer(serializers.ModelSerializer):
class Meta:
model=User
fields=('id','username','mobile','email')
指定分页器:
class UserPageNum(PageNumberPagination):
page_size = 5 # 后端指定每页显示数量
page_size_query_param = 'pagesize'
max_page_size = 10
# 重写分页返回方法,按照指定的字段进行分页数据返回
def get_paginated_response(self, data):
return Response({
'count': self.page.paginator.count, # 总数量
'lists': data, # 用户数据
'page' : self.page.number, # 当前页数
'pages' : self.page.paginator.num_pages, # 总页数
'pagesize':self.page_size # 后端指定的页容量
})================================
增加用户
接口分析
请求方式:POST /meiduo_admin/users/
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| password | int | 是 | 密码 |
| str | 否 | 邮箱 |
返回数据: JSON
{
"id": "用户id",
"username": "用户名",
"mobile": "手机号",
"email": "邮箱"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | int | 是 | 用户id |
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| str | 是 | 邮箱 |
后端实现
from rest_framework.generics import ListCreateAPIView
from meiduo_admin.serializers.user import UserSerializer, UserAddSerializer
from meiduo_admin.utils.pagenum import PageNum
from users.models import User
class UserView(ListCreateAPIView):
pagination_class = PageNum
# 根据不同的请求方式返回不同序列化器
def get_serializer_class(self):
# 请求方式是GET,则是获取用户数据返回UserSerializer
if self.request.method == 'GET':
return UserSerializer
else:
# POST请求,完成保存用户,返回UserAddSerializer
return UserAddSerializer
def get_queryset(self):
keyword = self.request.query_params.get('keyword')
if keyword is '':
return User.objects.all()
else:
return User.objects.filter(username=keyword)
注意:
在获取和保存用户是,请求路径是一样的,所以我们在一个UserView类视图中完成两个功能,所以我们需要对原有的类视图进行改写,继承ListCreateAPIView,同时重写get_serializer_class方法
指定序列化器:
from rest_framework import serializers
from users.models import User
class UserAddSerializer(serializers.ModelSerializer):
class Meta:
model = User
fields = ('id', 'username', 'mobile', 'email', 'password')
# username字段增加长度限制,password字段只参与保存,不在返回给前端,增加write_only选项参数
extra_kwargs = {
'username': {
'max_length': 20,
'min_length': 5
},
'password': {
'max_length': 20,
'min_length': 8,
'write_only': True
},
}
# 重写create方法
def create(self, validated_data):
# 保存用户数据并对密码加密
user = User.objects.create_user(**validated_data)
return user============商品管理==================
规格表管理
在规格表中我们需要对规格表数据进行增删改查操作,这时候我们可以借助于视图集中的ModelViewset来完成相应的操作
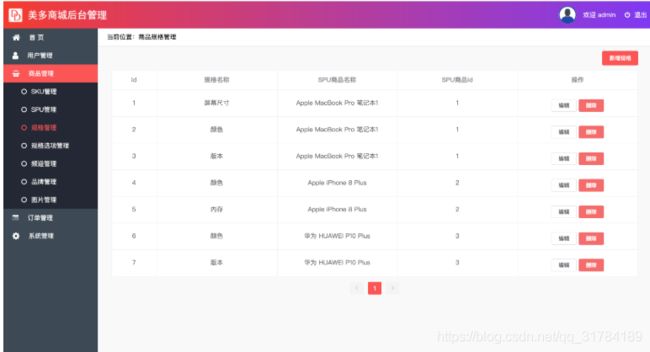
查询获取规格表列表数据
接口分析
请求方式: GET /meiduo_admin/goods/specs/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"counts": "SPU商品规格总数量",
"lists": [
{
"id": "规格id",
"name": "规格名称",
"spu": "SPU商品名称",
"spu_id": "SPU商品id"
},
...
],
"page": "页码",
"pages": "总页数",
"pagesize": "页容量"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 总量 |
| lists | 数组 | 是 | 规格表信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
class SpecsView(ModelViewSet):
serializer_class = SPUSpecificationSerializer
queryset = SPUSpecification.objects.all()
pagination_class = PageNum
序列化器的定义
class SPUSpecificationSerializer(serializers.ModelSerializer):
# 关联嵌套返回spu表的商品名
spu=serializers.StringRelatedField(read_only=True)
# 返回关联spu的id值
spu_id=serializers.IntegerField()
class Meta:
model = SPUSpecification # 商品规格表关联了spu表的外键spu
fields='__all__'保存规格表数据表数据
接口分析
请求方式:POST /meiduo_admin/goods/specs/
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 规格名称 |
| spu_id | int | 是 | SPU商品id |
返回数据: JSON
{
"id": "规格id",
"name": "规格名称",
"spu": "SPU商品名称",
"spu_id": "SPU商品id"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 规格id |
| name | Str | 是 | 规格名称 |
| spu | str | 是 | SPU商品名称 |
| spu_id | Int | 是 | spu商品id |
后端实现
# SpecsView继承的是ModelViewSet 所以保存逻辑还是使用同一个类视图
class SpecsView(ModelViewSet):
serializer_class =SPUSpecificationSerializer
queryset = SPUSpecification.objects.all()
pagination_class = PageNum更新规格表数据
1、 获取要修改规格表的详情信息
点就修改按钮时,我们需要先获取要修改的规格详情信息
接口分析
请求方式: GET /meiduo_admin/goods/specs/(?P
请求参数: 通过请求头传递jwt token数据。
在头部中携带要获取的规格ID
返回数据: JSON
{
"id": "规格id",
"name": "规格名称",
"spu": "SPU商品名称",
"spu_id": "SPU商品id"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | int | 是 | 规格 ID |
| name | str | 是 | 规格名称 |
| spu | str | 是 | SPU商品名称 |
| spu_id | int | 是 | SPU商品id |
后端实现
# SpecsView继承的是ModelViewSet 所以获取单一规格逻辑还是使用同一个类视图
class SpecsView(ModelViewSet):
serializer_class =SPUSpecificationSerializer
queryset = SPUSpecification.objects.all()
pagination_class = PageNum
2、修改规格表数据
接口分析
请求方式: PUT /meiduo_admin/goods/specs/(?P
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 规格名称 |
| spu_id | int | 是 | 商品SPU ID |
返回数据: JSON
{
"id": "规格id",
"name": "规格名称",
"goods": "SPU商品名称",
"goods_id": "SPU商品id"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | int | 是 | 规格 ID |
| name | str | 是 | 规格名称 |
| spu | str | 是 | SPU商品名称 |
| spu_id | int | 是 | SPU商品id |
后端实现
# SpecsView继承的是ModelViewSet 所以修改逻辑还是使用同一个类视图
class SpecsView(ModelViewSet):
"""
规格表视图
"""
serializer_class =SPUSpecificationSerializer
queryset = SPUSpecification.objects.all()
pagination_class = PageNum删除规格表数据
接口分析
请求方式: Delte /meiduo_admin/goods/specs/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中携带删除的规格的id值
返回数据: JSON
返回空
后端实现
# SpecsView继承的是ModelViewSet 所以删除逻辑还是使用同一个类视图
class SpecsView(ModelViewSet):
"""
规格表视图
"""
serializer_class =SPUSpecificationSerializer
queryset = SPUSpecification.objects.all()
pagination_class = PageNum图片管理
在图片表中我们需要对图片数据进行增删改查操作,这时候我们可以借助于视图集中的ModelViewset来完成相应的操作
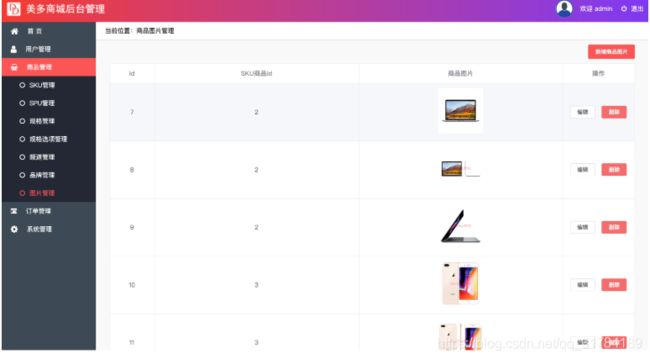
获取图片列表数据
接口分析
请求方式: GET /meiduo_admin/skus/images/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"counts": "图片总数量",
"lists": [
{
"id": "图片id",
"sku": "SKU商品id",
"image": "图片地址"
}
...
],
"page": "页码",
"pages": "总页数",
"pagesize": "页容量"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 图片总量 |
| lists | 数组 | 是 | 图片信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
class ImageView(ModelViewSet):
# 图片序列化器
serializer_class = ImageSeriazlier
# 图片查询集
queryset = SKUImage.objects.all()
# 分页
pagination_class = PageNum
序列化器的定义
class ImageSeriazlier(serializers.ModelSerializer):
# 返回图片关联的sku的id值
sku=serializers.PrimaryKeyRelatedField(read_only=True)
class Meta:
model=SKUImage
fields=('sku','image','id')保存图片数据
在保存数据之前我们需要先获取图片关联的sku的id
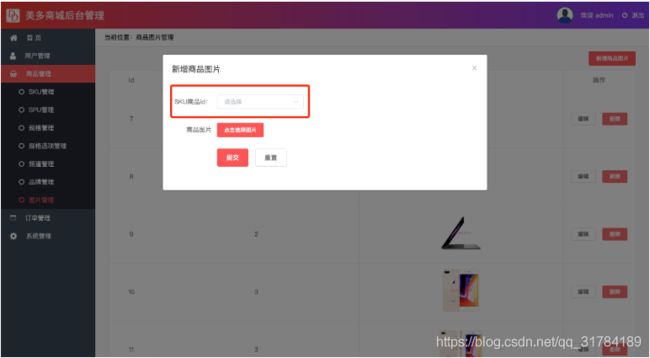
1、获取sku表id
接口分析
请求方式: GET /meiduo_admin/skus/simple/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"id": 1,
"name": "Apple MacBook Pro 13.3英寸笔记本 银色"
},
{
"id": 2,
"name": "Apple MacBook Pro 13.3英寸笔记本 深灰色"
},
......
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | sku商品id |
| name | 数组 | 是 | Sku商品名称 |
后端实现
class ImageView(ModelViewSet):
serializer_class = ImageSeriazlier
queryset = SKUImage.objects.all()
pagination_class = PageNum
# 获取sku商品信息
def simple(self,request):
data = SKU.objects.all()
ser = SKUSeriazlier(data,many=True)
return Response(ser.data)
序列化器的定义
class SKUSeriazlier(serializers.ModelSerializer):
class Meta:
model=SKU
fields=('id','name')
2、保存图片数据
接口分析
请求方式:POST /meiduo_admin/skus/images/
请求参数: 通过请求头传递jwt token数据。
表单提交数据:
"sku": "SKU商品id",
"image": "SKU商品图片"
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| sku | str | 是 | SKU商品id |
| image | Fiel | 是 | SKU商品图片 |
返回数据: JSON
{
"id": "图片id",
"sku": "SKU商品id",
"image": "图片地址"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 图片id |
| sku | int | 是 | SKU商品id |
| image | str | 是 | 图片地址 |
后端实现
在保存图片的同时,我们还需要异步生成新的详情页页面,这是我们需要定义异步任务
import os
from django.conf import settings
from django.shortcuts import render
from goods.models import SKU
from meiduo_mall.utils.breadcrumb import get_breadcrumb
from meiduo_mall.utils.categories import get_categories
from celery_tasks.main import app
@app.task(name='get_detail_html')
def get_detail_html(sku_id):
# 获取当前sku对象
sku=SKU.objects.get(id=sku_id)
# 分类数据
categories = get_categories()
# 获取面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 获取spu
spu = sku.spu
# 获取规格信息:sku===>spu==>specs
specs = spu.specs.order_by('id')
# 查询所有的sku,如华为P10的所有库存商品
skus = spu.skus.order_by('id')
'''
{
选项:sku_id
}
说明:键的元组中,规格的索引是固定的
示例数据如下:
{
(1,3):1,
(2,3):2,
(1,4):3,
(2,4):4
}
'''
sku_options = {}
sku_option = []
for sku1 in skus:
infos = sku1.specs.order_by('spec_id')
option_key = []
for info in infos:
option_key.append(info.option_id)
# 获取当前商品的规格信息
if sku.id == sku1.id:
sku_option.append(info.option_id)
sku_options[tuple(option_key)] = sku1.id
# 遍历当前spu所有的规格
specs_list = []
for index, spec in enumerate(specs):
option_list = []
for option in spec.options.all():
# 如果当前商品为蓝、64,则列表为[2,3]
sku_option_temp = sku_option[:]
# 替换对应索引的元素:规格的索引是固定的[1,3]
sku_option_temp[index] = option.id
# 为选项添加sku_id属性,用于在html中输出链接
option.sku_id = sku_options.get(tuple(sku_option_temp), 0)
# 添加选项对象
option_list.append(option)
# 为规格对象添加选项列表
spec.option_list = option_list
# 重新构造规格数据
specs_list.append(spec)
context = {
'sku': sku,
'categories': categories,
'breadcrumb': breadcrumb,
'category_id': sku.category_id,
'spu': spu,
'specs': specs_list
}
response = render(None, 'detail.html', context)
file_name = os.path.join(settings.BASE_DIR, 'static/detail/%d.html' % sku.id)
# 写文件
with open(file_name, 'w') as f1:
f1.write(response.content.decode())
视图代码
class ImageView(ModelViewSet):
serializer_class = ImageSeriazlier
queryset = SKUImage.objects.all()
pagination_class = PageNum
# 获取关联的sku表数据
def simple(self, request):
data = SKU.objects.all()
ser = SKUSeriazlier(data, many=True)
return Response(ser.data)
# 重写拓展类的保存业务逻辑
def create(self, request, *args, **kwargs):
# 创建FastDFS连接对象
client = Fdfs_client(settings.FASTDFS_PATH)
# 获取前端传递的image文件
data = request.FILES.get('image')
# 上传图片到fastDFS
res = client.upload_by_buffer(data.read())
# 判断是否上传成功
if res['Status'] != 'Upload successed.':
return Response(status=403)
# 获取上传后的路径
image_url = res['Remote file_id']
# 获取sku_id
sku_id = request.data.get('sku')[0]
# 保存图片
img = SKUImage.objects.create(sku_id=sku_id, image=image_url)
# 生成新的详情页页面
get_detail_html.delay(img.sku.id)
# 返回结果
return Response(
{
'id': img.id,
'sku': sku_id,
'image': img.image.url
},
status=201 # 前端需要接受201状态
)更新SKU表数据
1、 获取修改图片的详情信息
点就修改按钮时,我们需要先获取要修改的图片详情信息
接口分析
请求方式: GET /meiduo_admin/skus/images/(?P
请求参数: 通过请求头传递jwt token数据。
在头部中携带要获取的图片商品ID
返回数据: JSON
{
"id": "图片id",
"sku": "SKU商品id",
"image": "图片地址"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | int | 是 | "图片id" |
| sku | int | 是 | SKU商品id |
| iamge | str | 是 | 图片地址 |
后端实现
# ImageView继承的是ModelViewSet 所以还是使用同一个类视图
class ImageView(ModelViewSet):
serializer_class = ImageSeriazlier
queryset = SKUImage.objects.all()
pagination_class = PageNum
# 获取关联的sku表数据
def simple(self, request):
data = SKU.objects.all()
ser = SKUSeriazlier(data, many=True)
return Response(ser.data)
# 重写拓展类的保存业务逻辑
def create(self, request, *args, **kwargs):
# 创建FastDFS连接对象
client = Fdfs_client(settings.FASTDFS_PATH)
# 获取前端传递的image文件
data = request.FILES.get('image')
# 上传图片到fastDFS
res = client.upload_by_buffer(data.read())
# 判断是否上传成功
if res['Status'] != 'Upload successed.':
return Response(status=403)
# 获取上传后的路径
image_url = res['Remote file_id']
# 获取sku_id
sku_id = request.data.get('sku')[0]
# 保存图片
image = SKUImage.objects.create(sku_id=sku_id, image=image_url)
# 返回结果
return Response(
{
'id': image.id,
'sku': sku_id,
'image': image.image.url
},
status=201 # 前端需要接受201状态码
)
2、更新图片
接口分析
请求方式: PUT /meiduo_admin/skus/images/(?P
请求参数: 通过请求头传递jwt token数据。
表单提交数据:
"sku": "SKU商品id",
"image": "SKU商品图片"
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| sku | str | 是 | SKU商品id |
| image | Fiel | 是 | SKU商品图片 |
返回数据: JSON
{
"id": "图片id",
"sku": "SKU商品id",
"image": "图片地址"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 图片id |
| sku | int | 是 | SKU商品id |
| image | str | 是 | 图片地址 |
后端实现
from django.conf import settings
from rest_framework.viewsets import ModelViewSet
from rest_framework.response import Response
from fdfs_client.client import Fdfs_client
from meiduo_admin.serializers.image import ImageSeriazlier, SKUSeriazlier
from meiduo_admin.utils.pagenum import PageNum
from goods.models import SKUImage, SKU
class ImageView(ModelViewSet):
serializer_class = ImageSeriazlier
queryset = SKUImage.objects.all()
pagination_class = PageNum
def simple(self, request):
data = SKU.objects.all()
ser = SKUSeriazlier(data, many=True)
return Response(ser.data)
# 重写拓展类的保存业务逻辑
def create(self, request, *args, **kwargs):
client = Fdfs_client(settings.FASTDFS_PATH)
data = request.FILES.get('image')
res = client.upload_by_buffer(data.read())
if res['Status'] != 'Upload successed.':
return Response(status=403)
image_url = res['Remote file_id']
sku_id = request.data.get('sku')[0]
image = SKUImage.objects.create(sku_id=sku_id, image=image_url)
return Response(
{
'id': image.id,
'sku': sku_id,
'image': image.image.url
},
status=201
)
# 重写拓展类的更新业务逻辑
def update(self, request, *args, **kwargs):
# 创建FastDFS连接对象
client = Fdfs_client(settings.FASTDFS_PATH)
# 获取前端传递的image文件
data = request.FILES.get('image')
# 上传图片到fastDFS
res = client.upload_by_buffer(data.read())
# 判断是否上传成功
if res['Status'] != 'Upload successed.':
return Response(status=403)
# 获取上传后的路径
image_url = res['Remote file_id']
# 获取sku_id
sku_id = request.data.get('sku')[0]
# 查询图片对象
img=SKUImage.objects.get(id=kwargs['pk'])
# 更新图片
img.image=image_url
img.save()
# 生成新的详情页页面
get_detail_html.delay(img.sku.id)
# 返回结果
return Response(
{
'id': img.id,
'sku': sku_id,
'image': img.image.url
},
status=201 # 前端需要接受201状态码
)删除SKU表数据
接口分析
请求方式: Delte /meiduo_admin/skus/images/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中携带删除的图片的id值
返回数据: JSON
返回空
后端实现
#ImageView继承的是ModelViewSet 所以删除逻辑还是使用同一个类视图
class ImageView(ModelViewSet):
# 图片序列化器
serializer_class = ImageSeriazlier
# 图片查询集
queryset = SKUImage.objects.all()
# 分页
pagination_class = PageNumSKU表管理
在sku表中我们需要对SKU表数据进行增删改查操作,这时候我们可以借助于视图集中的ModelViewset来完成相应的操作

查询获取sku表列表数据
在获取sku数据时,我们在请求中包含了查询关键keyword,这时我么就需要对keyword进行判断,来返回不同的查询数据
接口分析
请求方式: GET /meiduo_admin/skus/?keyword=<名称|副标题>&page=<页码>&page_size=<页容量>
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"counts": "商品SPU总数量",
"lists": [
{
"id": "商品SKU ID",
"name": "商品SKU名称",
"spu": "商品SPU名称",
"spu_id": "商品SPU ID",
"caption": "商品副标题",
"category_id": "三级分类id",
"category": "三级分类名称",
"price": "价格",
"cost_price": "进价",
"market_price": "市场价格",
"stock": "库存",
"sales": "销量",
"is_launched": "上下架",
"specs": [
{
"spec_id": "规格id",
"option_id": "选项id"
},
...
]
},
...
],
"page": "页码",
"pages": "总页数",
"pagesize": "页容量"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | SKUs商总量 |
| lists | 数组 | 是 | SKU信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.permissions import IsAdminUser
from datetime import date
from users.models import User
from goods.models import GoodsVisitCount
class SKUGoodsView(ModelViewSet):
# 指定序列化器
serializer_class =SKUGoodsSerializer
# 指定分页器 进行分页返回
pagination_class = PageNum
# 重写get_queryset方法,判断是否传递keyword查询参数
def get_queryset(self):
# 提取keyword
keyword=self.request.query_params.get('keyword')
if keyword == '' or keyword is None:
return SKU.objects.all()
else:
return SKU.objects.filter(name=keyword)
序列化器的定义
class SKUSpecificationSerialzier(serializers.ModelSerializer):
"""
SKU规格表序列化器
"""
spec_id = serializers.IntegerField(read_only=True)
option_id = serializers.IntegerField(read_only=True)
class Meta:
model = SKUSpecification # SKUSpecification中sku外键关联了SKU表
fields=("spec_id",'option_id')
class SKUGoodsSerializer(serializers.ModelSerializer):
"""
获取sku表信息的序列化器
"""
# 指定所关联的选项信息 关联嵌套返回
specs = SKUSpecificationSerialzier(read_only=True,many=True)
# 指定分类信息
category_id = serializers.IntegerField()
# 关联嵌套返回
category = serializers.StringRelatedField(read_only=True)
# 指定所关联的spu表信息
spu_id = serializers.IntegerField()
# 关联嵌套返回
spu = serializers.StringRelatedField(read_only=True)
class Meta:
model = SKU # SKU表中category外键关联了GoodsCategory分类表。spu外键关联了SPU商品表
fields='__all__'保存SKU表数据
在保存数据之前我们需要先获取三级分类信息、SPU表的名称信息、当前SPU商品的规格选项信息加载到页面中
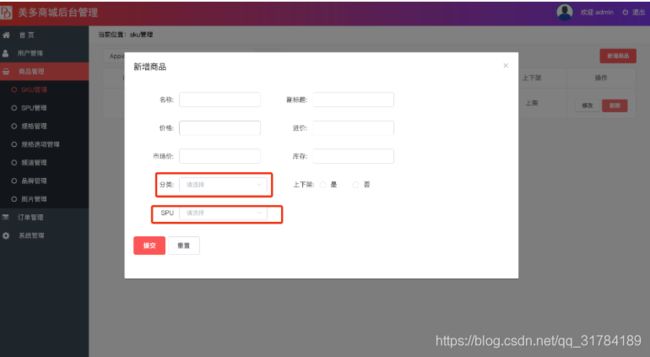
1、获取三级分类信息
接口分析
请求方式: GET /meiduo_admin/skus/categories/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"id": "商品分类id",
"name": "商品分类名称"
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | 商品分类id |
| name | 数组 | 是 | 商品分类名称 |
后端实现
from rest_framework.viewsets import ModelViewSet
from rest_framework.generics import ListAPIView
from meiduo_admin.serializers.goods import SKUGoodsSerializer, SKUCategorieSerializer
from meiduo_admin.utils.pagenum import PageNum
from goods.models import SKU,GoodsCategory
class SKUCategorieView(ListAPIView):
serializer_class = SKUCategorieSerializer
# 根据数据存储规律parent_id大于37为三级分类信息,查询条件为parent_id__gt=37
queryset = GoodsCategory.objects.filter(parent_id__gt=37)
序列化器的定义
from rest_framework import serializers
from goods.models import SKU,GoodsCategory
from goods.models import SKUSpecification
class SKUCategorieSerializer(serializers.ModelSerializer):
"""
商品分类序列化器
"""
class Meta:
model = GoodsCategory
fields = "__all__"
2、获取spu表名称数据
接口分析
请求方式: GET /meiduo_admin/goods/simple/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"id": "商品SPU ID",
"name": "SPU名称"
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | 商品SPU ID |
| name | 数组 | 是 | SPU名称 |
后端实现
class SPUSimpleView(ListAPIView):
serializer_class = SPUSimpleSerializer
queryset = SPU.objects.all()
定义序列化器
class SPUSimpleSerializer(serializers.ModelSerializer):
"""
商品SPU表序列化器
"""
class Meta:
model=GoodsCategory
fields = ('id','name')
3、获取SPU商品规格信息
接口分析
请求方式: GET meiduo_admin/goods/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中传递当前SPU商品id
返回数据: JSON
[
{
"id": "规格id",
"name": "规格名称",
"spu": "SPU商品名称",
"spu_id": "SPU商品id",
"options": [
{
"id": "选项id",
"name": "选项名称"
},
...
]
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | 规格id |
| name | Str | 是 | 规格名称 |
| Sup | str | 是 | Spu商品名称 |
| Spu_id | Int | 是 | spu商品id |
| options | 是 | 关联的规格选项 |
后端实现
class SPUSpecView(ListAPIView):
serializer_class = SPUSpecSerialzier
# 因为我们继承的是ListAPIView,在拓展类中是通过get_queryset获取数据,但是我们现在要获取的是规格信息,所以重写get_queryset
def get_queryset(self):
# 获取spuid值
pk=self.kwargs['pk']
# 根据spu的id值关联过滤查询出规格信息
return SPUSpecification.objects.filter(spu_id=self.kwargs['pk'])
定义序列化器
class SPUOptineSerializer(serializers.ModelSerializer):
"""
规格选项序列化器
"""
class Meta:
model = SpecificationOption
fields=('id','value')
class SPUSpecSerialzier(serializers.ModelSerializer):
"""
规格序列化器
"""
# 关联序列化返回SPU表数据
spu = serializers.StringRelatedField(read_only=True)
spu_id = serializers.IntegerField(read_only=True)
# 关联序列化返回 规格选项信息
options = SPUOptineSerializer(read_only=True,many=True) # 使用规格选项序列化器
class Meta:
model = SPUSpecification # SPUSpecification中的外键spu关联了SPU商品表
fields="__all__"
4、保存SKU数据
接口分析
请求方式: POST meiduo_admin/skus/
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 商品SKU名称 |
| spu_id | int | 是 | 商品SPU ID |
| caption | str | 是 | 商品副标题 |
| category_id | int | 是 | 三级分类ID |
| price | int | 是 | 价格 |
| cost_price | int | 是 | 进价 |
| market_price | int | 是 | 市场价 |
| stock | int | 是 | 库存 |
| is_launched | boole | 是 | 上下架 |
返回数据: JSON
{
"id": "商品SKU ID",
"name": "商品SKU名称",
"goods": "商品SPU名称",
"goods_id": "商品SPU ID",
"caption": "商品副标题",
"category_id": "三级分类id",
"category": "三级分类名称",
"price": "价格",
"cost_price": "进价",
"market_price": "市场价",
"stock": "库存",
"sales": "销量",
"is_launched": "上下架",
"specs": [
{
"spec_id": "规格id",
"option_id": "选项id"
},
...
]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 商品SKU名称 |
| spu_id | int | 商品SPU ID | |
| caption | str | 商品副标题 | |
| category_id | int | 三级分类ID | |
| price | int | 价格 | |
| cost_price | int | 进价 | |
| market_price | int | 市场价 | |
| stock | int | 库存 | |
| is_launched | boole | 上下架 |
后端实现:
在后端实现中,我们需要异步生成详情页静态页面,同时涉及到多张表操作,我们还需要使用事务
# SKUGoodsView继承的是ModelViewSet 所以保存逻辑还是使用同一个类视图
class SKUGoodsView(ModelViewSet):
serializer_class =SKUGoodsSerializer
pagination_class = PageNum
def get_queryset(self):
keyword=self.request.query_params.get('keyword')
if keyword == '' or keyword is None:
return SKU.objects.all()
else:
return SKU.objects.filter(name=keyword)
序列化器的定义
class SKUSerializer(serializers.ModelSerializer):
"""
SKU表数据
"""
# 返回关联spu表的名称和关联的分类表的名称
spu = serializers.StringRelatedField(read_only=True)
category = serializers.StringRelatedField(read_only=True)
# 返回模型类类的spu_id和category_id
spu_id = serializers.IntegerField()
category_id = serializers.IntegerField()
# 返回商品的规格信息 ,在商品规格详情表(SKUSpecification)中有个外键sku关了当前的SKU表
specs = SKUSpecificationSerializer(many=True)
class Meta:
model = SKU
fields = "__all__"
def create(self, validated_data):
# self指的是当前序列化器对象,在self下面有个context属性保存了请求对象
specs=self.context['request'].data.get('specs')
# specs = validated_data['specs']
# 因为sku表中没有specs字段,所以在保存的时候需要删除validated_data中specs数据
del validated_data['specs']
with transaction.atomic():
# 开启事务
sid = transaction.savepoint()
try:
# 1、保存sku表
sku = SKU.objects.create(**validated_data)
# 2、保存SKU具体规格
for spec in specs:
SKUSpecification.objects.create(sku=sku, spec_id=spec['spec_id'], option_id=spec['option_id'])
except:
# 捕获异常,说明数据库操作失败,进行回滚
transaction.savepoint_rollback(sid)
return serializers.ValidationError('数据库错误')
else:
# 没有捕获异常,数据库操作成功,进行提交
transaction.savepoint_commit(sid)
# 执行异步任务生成新的静态页面
get_detail_html.delay(sku.id)
return sku
异步任务:
import os
from django.conf import settings
from django.shortcuts import render
from goods.models import SKU
from meiduo_mall.utils.breadcrumb import get_breadcrumb
from meiduo_mall.utils.categories import get_categories
from celery_tasks.main import app
@app.task(name='get_detail_html')
def get_detail_html(sku_id):
# 获取当前sku对象
sku=SKU.objects.get(id=sku_id)
# 分类数据
categories = get_categories()
# 获取面包屑导航
breadcrumb = get_breadcrumb(sku.category)
# 获取spu
spu = sku.spu
# 获取规格信息:sku===>spu==>specs
specs = spu.specs.order_by('id')
# 查询所有的sku,如华为P10的所有库存商品
skus = spu.skus.order_by('id')
'''
{
选项:sku_id
}
说明:键的元组中,规格的索引是固定的
示例数据如下:
{
(1,3):1,
(2,3):2,
(1,4):3,
(2,4):4
}
'''
sku_options = {}
sku_option = []
for sku1 in skus:
infos = sku1.specs.order_by('spec_id')
option_key = []
for info in infos:
option_key.append(info.option_id)
# 获取当前商品的规格信息
if sku.id == sku1.id:
sku_option.append(info.option_id)
sku_options[tuple(option_key)] = sku1.id
# 遍历当前spu所有的规格
specs_list = []
for index, spec in enumerate(specs):
option_list = []
for option in spec.options.all():
# 如果当前商品为蓝、64,则列表为[2,3]
sku_option_temp = sku_option[:]
# 替换对应索引的元素:规格的索引是固定的[1,3]
sku_option_temp[index] = option.id
# 为选项添加sku_id属性,用于在html中输出链接
option.sku_id = sku_options.get(tuple(sku_option_temp), 0)
# 添加选项对象
option_list.append(option)
# 为规格对象添加选项列表
spec.option_list = option_list
# 重新构造规格数据
specs_list.append(spec)
context = {
'sku': sku,
'categories': categories,
'breadcrumb': breadcrumb,
'category_id': sku.category_id,
'spu': spu,
'specs': specs_list
}
response = render(None, 'detail.html', context)
file_name = os.path.join(settings.BASE_DIR, 'static/detail/%d.html' % sku.id)
# 写文件
with open(file_name, 'w') as f1:
f1.write(response.content.decode())更新SKU表数据
1、 获取修改商品的详情信息
点就修改按钮时,我们需要先获取要修改的商品详情信息
接口分析
请求方式: GET /meiduo_admin/skus/(?P
请求参数: 通过请求头传递jwt token数据。
在头部中携带要获取的spu商品ID
返回数据: JSON
{
"id": "商品SKU ID",
"name": "商品SKU名称",
"goods": "商品SPU名称",
"goods_id": "商品SPU ID",
"caption": "商品副标题",
"category_id": "三级分类id",
"category": "三级分类名称",
"price": "价格",
"cost_price": "进价",
"market_price": "市场价",
"stock": "库存",
"sales": "销量",
"is_launched": "上下架",
"specs": [
{
"spec_id": "规格id",
"option_id": "选项id"
},
...
]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 商品SKU名称 |
| spu_id | int | 是 | 商品SPU ID |
| caption | str | 是 | 商品副标题 |
| category_id | int | 是 | 三级分类ID |
| price | int | 是 | 价格 |
| cost_price | int | 是 | 进价 |
| market_price | int | 是 | 市场价 |
| stock | int | 是 | 库存 |
| is_launched | boole | 是 | 上下架 |
后端实现
# SKUGoodsView继承的是ModelViewSet 所以获取单一spu商品逻辑还是使用同一个类视图
class SKUGoodsView(ModelViewSet):
serializer_class =SKUGoodsSerializer
pagination_class = PageNum
def get_queryset(self):
keyword=self.request.query_params.get('keyword')
if keyword == '' or keyword is None:
return SKU.objects.all()
else:
return SKU.objects.filter(name=keyword)
接口分析
请求方式: PUT meiduo_admin/skus/(?P
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 商品SKU名称 |
| spu_id | int | 是 | 商品SPU ID |
| caption | str | 是 | 商品副标题 |
| category_id | int | 是 | 三级分类ID |
| price | int | 是 | 价格 |
| cost_price | int | 是 | 进价 |
| market_price | int | 是 | 市场价 |
| stock | int | 是 | 库存 |
| is_launched | boole | 是 | 上下架 |
返回数据: JSON
{
"id": "商品SKU ID",
"name": "商品SKU名称",
"goods": "商品SPU名称",
"goods_id": "商品SPU ID",
"caption": "商品副标题",
"category_id": "三级分类id",
"category": "三级分类名称",
"price": "价格",
"cost_price": "进价",
"market_price": "市场价",
"stock": "库存",
"sales": "销量",
"is_launched": "上下架",
"specs": [
{
"spec_id": "规格id",
"option_id": "选项id"
},
...
]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 商品SKU名称 |
| spu_id | int | 是 | 商品SPU ID |
| caption | str | 是 | 商品副标题 |
| category_id | int | 是 | 三级分类ID |
| price | int | 是 | 价格 |
| cost_price | int | 是 | 进价 |
| market_price | int | 是 | 市场价 |
| stock | int | 是 | 库存 |
| is_launched | boole | 是 | 上下架 |
后端实现
# SKUGoodsView继承的是ModelViewSet 所以更新逻辑还是使用同一个类视图
class SKUGoodsView(ModelViewSet):
serializer_class =SKUGoodsSerializer
pagination_class = PageNum
def get_queryset(self):
keyword=self.request.query_params.get('keyword')
if keyword == '':
return SKU.objects.all()
else:
return SKU.objects.filter(name=keyword)
序列化器定义:
class SKUSerializer(serializers.ModelSerializer):
"""
SKU表数据
"""
# 返回关联spu表的名称和关联的分类表的名称
spu = serializers.StringRelatedField(read_only=True)
category = serializers.StringRelatedField(read_only=True)
# 返回模型类类的spu_id和category_id
spu_id = serializers.IntegerField()
category_id = serializers.IntegerField()
# 返回商品的规格信息 ,在商品规格详情表(SKUSpecification)中有个外键sku关了当前的SKU表
specs = SKUSpecificationSerializer(many=True)
class Meta:
model = SKU
fields = "__all__"
def create(self, validated_data):
# self指的是当前序列化器对象,在self下面有个context属性保存了请求对象
specs=self.context['request'].data.get('specs')
# specs = validated_data['specs']
# 因为sku表中没有specs字段,所以在保存的时候需要删除validated_data中specs数据
del validated_data['specs']
with transaction.atomic():
# 开启事务
sid = transaction.savepoint()
try:
# 1、保存sku表
sku = SKU.objects.create(**validated_data)
# 2、保存SKU具体规格
for spec in specs:
SKUSpecification.objects.create(sku=sku, spec_id=spec['spec_id'], option_id=spec['option_id'])
except:
# 捕获异常,说明数据库操作失败,进行回滚
transaction.savepoint_rollback(sid)
return serializers.ValidationError('数据库错误')
else:
# 没有捕获异常,数据库操作成功,进行提交
transaction.savepoint_commit(sid)
# 执行异步任务生成新的静态页面
get_detail_html.delay(sku.id)
return sku
def update(self, instance, validated_data):
# 获取规格信息
specs = self.context['request'].data.get('specs')
# 因为sku表中没有specs字段,所以在保存的时候需要删除validated_data中specs数据
del validated_data['specs']
with transaction.atomic():
# 开启事务
sid = transaction.savepoint()
try:
# 1、更新sku表
SKU.objects.filter(id=instance.id).update(**validated_data)
# 2、更新SKU具体规格表
for spec in specs:
SKUSpecification.objects.create(sku=instance, spec_id=spec['spec_id'], option_id=spec['option_id'])
except:
# 捕获异常,说明数据库操作失败,进行回滚
transaction.savepoint_rollback(sid)
return serializers.ValidationError('数据库错误')
else:
# 没有捕获异常,数据库操作成功,进行提交
transaction.savepoint_commit(sid)
# 执行异步任务生成新的静态页面
get_detail_html.delay(instance.id)
return instance删除SKU表数据
接口分析
请求方式: Delte meiduo_admin/skus/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中携带删除的spu的id值
返回数据: JSON
返回空
后端实现
# SKUGoodsView继承的是ModelViewSet 所以删除逻辑还是使用同一个类视图
class SKUGoodsView(ModelViewSet):
serializer_class =SKUGoodsSerializer
pagination_class = PageNum
def get_queryset(self):
keyword=self.request.query_params.get('keyword')
if keyword == '':
return SKU.objects.all()
else:
return SKU.objects.filter(name=keyword)==============订单管理=====================
获取订单表表列表数据
接口分析
请求方式: GET /meiduo_admin/orders/?keyword=<搜索内容>&page=<页码>&pagesize=<页容量>
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"counts": 39,
"list": [
{
"order_id": "20181126102807000000004",
"create_time": "2018-11-26T18:28:07.470959+08:00"
},
{
"order_id": "20181126103035000000004",
"create_time": "2018-11-26T18:30:35.854982+08:00"
},
......
],
"page": 1,
"pages": 8,
"pagesize": 5
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| count | int | 是 | 订单数据总量 |
| lists | 数组 | 是 | 订单表信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
class OrdersView(ModelViewSet):
serializer_class = OrderSeriazlier
queryset = OrderInfo.objects.all()
pagination_class = PageNum
序列化器的定义
class OrderSeriazlier(serializers.ModelSerializer):
class Meta:
model = OrderInfo
fields = '__all__'获取订单表详情数据数据
当点击订单详情时,我们需要获取订单详情数据

接口分析
请求方式: GET /meiduo_admin/orders/(?P
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"order_id": "20181126102807000000004",
"user": "zxc000",
"total_count": 5,
"total_amount": "52061.00",
"freight": "10.00",
"pay_method": 2,
"status": 1,
"create_time": "2018-11-26T18:28:07.470959+08:00",
"skus": [
{
"count": 1,
"price": "6499.00",
"sku": {
"name": "Apple iPhone 8 Plus (A1864) 64GB 金色 移动联通电信4G手机",
"default_image_url": "http://image.meiduo.site:8888/group1/M00/00/02/CtM3BVrRZCqAUxp9AAFti6upbx41220032"
}
},
......
]
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| order_id | int | 是 | 订单id |
| user | str | 是 | 用户名 |
| total_count | int | 是 | 商品总量 |
| total_amount | int | 是 | 总价 |
| freight | int | 是 | 运费 |
| pay_method | int | 是 | 支付方式 |
| status | int | 是 | 订单状态 |
| create_time | date | 是 | 订单日期 |
| skus | 数组 | 是 | 订单商品信息 |
后端实现
class OrdersView(ModelViewSet):
serializer_class = OrderSeriazlier
queryset = OrderInfo.objects.all()
pagination_class = PageNum
序列化器的定义,在返回数据时涉及到三张表的嵌套返回,订单基本信息表,订单商品表,商品sku表
class SKUSerialzier(serializers.ModelSerializer):
"""
商品sku表序列化器
"""
class Meta:
model=SKU
fields=('name','default_image')
class OrderGoodsSerialziers(serializers.ModelSerializer):
"""
订单商品序列化器
"""
# 嵌套返回sku表数据
sku=SKUGoodsSerializer(read_only=True)
class Meta:
model=OrderGoods
fields=('count','price','sku')
class OrderSeriazlier(serializers.ModelSerializer):
"""
订单序列化器
"""
# 关联嵌套返回 用户表数据和订单商品表数据
user=serializers.StringRelatedField(read_only=True)
skus=OrderGoodsSerialziers(many=True,read_only=True)
class Meta:
model = OrderInfo
fields = '__all__'更新订单表状态数据
点击修改状态,完成订单表状态的修改操作
接口分析
请求方式: PUT /meiduo_admin/orders/(?P
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| status | str | 是 | 订单状态 |
返回数据: JSON
{
"order_id": "20181126102807000000004",
"status": 1
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| order_id | str | 是 | d订单id |
| status | int | 是 | 订单状态 |
后端实现
class OrdersView(ModelViewSet):
serializer_class = OrderSeriazlier
queryset = OrderInfo.objects.all()
pagination_class = PageNum
# 在视图中定义status方法修改订单状态
@action(methods=['put'], detail=True)
def status(self, request, pk):
# 获取订单对象
order = self.get_object()
# 获取要修改的状态值
status = request.data.get('status')
# 修改订单状态
order.status = status
order.save()
# 返回结果
ser = self.get_serializer(order)
return Response({
'order_id': order.order_id,
'status': status
})用户权限控制说明
在产品运营平台中,是需要对用户进行权限控制的。Django实现了用户权限的控制
- 消费者用户与公司内部运营用户使用一个用户数据库来存储
- 通过is_staff 来区分是运营用户还是消费者用户
- 对于运营用户通过is_superuser 来区分是运营平台的管理员还是运营平台的普通用户
- 对于运营平台的普通用户,通过权限、组和组外权限来控制这个用户在平台上可以操作的数据。
- 对于权限,Django会为每个数据库表提供增、删、改、查四种权限
- 用户最终的权限为 组权限 + 用户特有权限
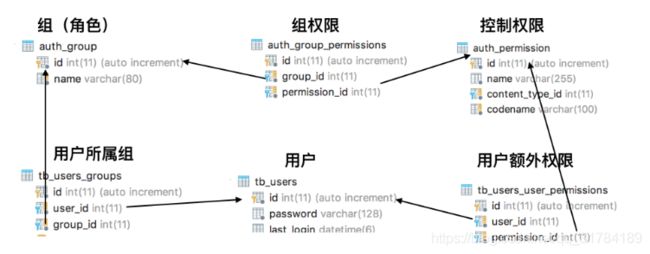

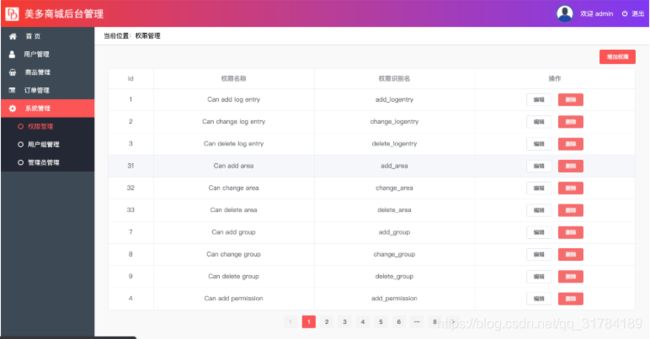
权限表管理
在权限表中我们需要对权限表数据进行增删改查操作,这时候我们可以借助于视图集中的ModelViewset来完成相应的操作
获取用户权限表列表数据
接口分析
请求方式: GET /meiduo_admin/permission/perms/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"counts": "权限总数量",
"list": [
{
"id": "权限id",
"name": "权限名称",
"codename": "权限识别名",
"content_type": "权限类型"
},
...
],
"page": "当前页码",
"pages": "总页码",
"pagesize": "页容量"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| counts | int | 是 | 权限总数量 |
| lists | 数组 | 是 | 权限表信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
from django.contrib.auth.models import Permission, ContentType
class PermissionView(ModelViewSet):
serializer_class = PermissionSerialzier
queryset = Permission.objects.all()
pagination_class = PageNum
序列化器的定义
from django.contrib.auth.models import Permission, ContentType
class PermissionSerialzier(serializers.ModelSerializer):
"""
用户权限表序列化器
"""
class Meta:
model=Permission
fields="__all__"保存权限表数据
在保存数据之前我们需要权限类表数据内容

1、获取权限类型列表数据
接口分析
请求方式: GET /meiduo_admin/permission/content_types/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"id": "权限类型id",
"name": "权限类型名称"
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | 权限类型id |
| name | 数组 | 是 | 权限类型名称 |
后端实现
from django.contrib.auth.models import Permission, ContentType
class PermissionView(ModelViewSet):
serializer_class = PermissionSerialzier
queryset = Permission.objects.all()
pagination_class = PageNum
# 获取权限类型数据
def content_types(self,request):
# 查询全选分类
content=ContentType.objects.all()
# 返回结果
ser=ContentTypeSerialzier(content,many=True)
return Response(ser.data)
序列化器的定义
from django.contrib.auth.models import Permission, ContentType
class ContentTypeSerialzier(serializers.ModelSerializer):
"""
权限类型序列化器
"""
class Meta:
model=ContentType
fields=('id','name')
2、保存权限表数据
接口分析
请求方式:POST /meiduo_admin/permission/perms/
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 权限名称 |
| codename | str | 是 | 权限识别名 |
| content_type | str | 是 | 权限类型 |
返回数据: JSON
{
"id": "权限id",
"name": "权限名称",
"codename": "权限识别名",
"content_type": "权限类型"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 权限id |
| name | Str | 是 | 权限名称 |
| codename | str | 是 | 限识别名 |
| content_type | int | 是 | 权限类型 |
后端实现
from django.contrib.auth.models import Permission, ContentType
# PermissionView继承的是ModelViewSet 所以保存逻辑还是使用同一个类视图
class PermissionView(ModelViewSet):
serializer_class = PermissionSerialzier
queryset = Permission.objects.all()
pagination_class = PageNum
def content_types(self,request):
# 查询全选分类
content=ContentType.objects.all()
# 返回结果
ser=ContentTypeSerialzier(content,many=True)
return Response(ser.data)更新权限表数据
1、 获取修改权限表的详情信息
点就修改按钮时,我们需要先获取要修改的商品详情信息
接口分析
请求方式: GET /meiduo_admin/permission/perms/(?P
请求参数: 通过请求头传递jwt token数据。
在头部中携带要获取的权限商品ID
返回数据: JSON
{
"id": "权限id",
"name": "权限名称",
"codename": "权限识别名",
"content_type": "权限类型"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 权限id |
| name | Str | 是 | 权限名称 |
| codename | str | 是 | 限识别名 |
| content_type | int | 是 | 权限类型 |
后端实现
from django.contrib.auth.models import Permission, ContentType
# PermissionView继承的是ModelViewSet 所以获取详情逻辑还是使用同一个类视图
class PermissionView(ModelViewSet):
serializer_class = PermissionSerialzier
queryset = Permission.objects.all()
pagination_class = PageNum
def content_types(self,request):
# 查询全选分类
content=ContentType.objects.all()
# 返回结果
ser=ContentTypeSerialzier(content,many=True)
return Response(ser.data)
2、修改权限表
接口分析
请求方式: PUT /meiduo_admin/goods/(?P
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 权限名称 |
| codename | str | 是 | 权限识别名 |
| content_type | str | 是 | 权限类型 |
返回数据: JSON
{
"id": "权限id",
"name": "权限名称",
"codename": "权限识别名",
"content_type": "权限类型"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 权限id |
| name | Str | 是 | 权限名称 |
| codename | str | 是 | 限识别名 |
| content_type | int | 是 | 权限类型 |
后端实现
from django.contrib.auth.models import Permission, ContentType
# PermissionView继承的是ModelViewSet 所以更新逻辑还是使用同一个类视图
class PermissionView(ModelViewSet):
serializer_class = PermissionSerialzier
queryset = Permission.objects.all()
pagination_class = PageNum
def content_types(self,request):
# 查询全选分类
content=ContentType.objects.all()
# 返回结果
ser=ContentTypeSerialzier(content,many=True)
return Response(ser.data)删除权限表数据
接口分析
请求方式: Delte /meiduo_admin/permission/perms/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中携带删除的权限表的id值
返回数据: JSON
返回空
后端实现
from django.contrib.auth.models import Permission, ContentType
# PermissionView继承的是ModelViewSet 所以删除逻辑还是使用同一个类视图
class PermissionView(ModelViewSet):
serializer_class = PermissionSerialzier
queryset = Permission.objects.all()
pagination_class = PageNum
def content_types(self,request):
# 查询全选分类
content=ContentType.objects.all()
# 返回结果
ser=ContentTypeSerialzier(content,many=True)
return Response(ser.data)分组表管理
在系统管理中我们需要完成用户组表的增删改查,这时候我们可以借助于视图集中的ModelViewset来完成相应的操作

获取用户组表列表数据
接口分析
请求方式: GET /meiduo_admin/permission/groups/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"counts": "用户组总数量",
"list": [
{
"id": "组id",
"name": "组名称",
},
...
],
"page": "当前页码",
"pages": "总页码",
"pagesize": "页容量"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| counts | int | 是 | 用户组总数量 |
| lists | 数组 | 是 | 用户组表信息 |
| page | int | 是 | 页码 |
| pages | int | 是 | 总页数 |
| pagesize | int | 是 | 页容量 |
后端实现
from django.contrib.auth.models import Permission, ContentType, Group
class GroupView(ModelViewSet):
serializer_class = GroupSerialzier
queryset = Group.objects.all()
pagination_class = PageNum
序列化器的定义
class GroupSerialzier(serializers.ModelSerializer):
class Meta:
model=Group
fields="__all__"保存分组表数据
在保存数据之前我们需要权限表的数据内容展示在权限中
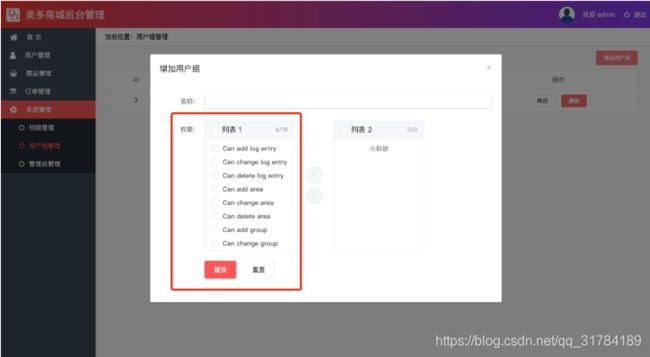
1、获取权限表数据
接口分析
请求方式: GET /meiduo_admin/permission/simple/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"id": "权限类型id",
"name": "权限类型名称"
},
...
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | 权限类型id |
| name | 数组 | 是 | 权限类型名称 |
后端实现
from django.contrib.auth.models import Permission, ContentType, Group
class GroupView(ModelViewSet):
serializer_class = GroupSerialzier
queryset = Group.objects.all()
pagination_class = PageNum
# 获取权限表数据
def simple(self, reqeust):
pers = Permission.objects.all()
ser = PermissionSerialzier(pers, many=True) # 使用以前定义的全选序列化器
return Response(ser.data)
2、保存权限表数据
接口分析
请求方式:POST /meiduo_admin/permission/groups/
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 组名称 |
| permissions | str | 是 | ["权限id", ...] |
返回数据: JSON
{
"id": "组id",
"name": "组名称"
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 组id |
| name | Str | 是 | 组名称 |
后端实现
from django.contrib.auth.models import Permission, ContentType, Group
# GroupView继承的是ModelViewSet 所以保存逻辑还是使用同一个类视图
class GroupView(ModelViewSet):
serializer_class = GroupSerialzier
queryset = Group.objects.all()
pagination_class = PageNum
# 获取权限表数据
def simple(self, reqeust):
pers = Permission.objects.all()
ser = PermissionSerialzier(pers, many=True) # 使用以前定义的全选序列化器
return Response(ser.data)更新分组表数据
1、 获取修改分组表的详情信息
点就修改按钮时,我们需要先获取要修改的分组表详情信息
接口分析
请求方式: GET /meiduo_admin/permission/groups/(?P
请求参数: 通过请求头传递jwt token数据。
在头部中携带要获取的分组ID
返回数据: JSON
{
"id": "组id",
"name": "组名称",
"permissions": [
"权限id",
"权限id",
...
]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 组id |
| name | Str | 是 | 组名称 |
| permissions | str | 是 | 限识id |
后端实现
from django.contrib.auth.models import Permission, ContentType, Group
# GroupView继承的是ModelViewSet 所以获取详情逻辑还是使用同一个类视图
class GroupView(ModelViewSet):
serializer_class = GroupSerialzier
queryset = Group.objects.all()
pagination_class = PageNum
# 获取权限表数据
def simple(self, reqeust):
pers = Permission.objects.all()
ser = PermissionSerialzier(pers, many=True) # 使用以前定义的全选序列化器
return Response(ser.data)
2、修改权限表
接口分析
请求方式: PUT /meiduo_admin/permission/groups/(?P
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| name | str | 是 | 组名称 |
| permissions | str | 是 | 权限id |
返回数据: JSON
{
"id": "组id",
"name": "组名称",
"permissions": [
"权限id",
"权限id",
...
]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | Int | 是 | 组id |
| name | Str | 是 | 组名称 |
| permissions | str | 是 | 限识id |
后端实现
from django.contrib.auth.models import Permission, ContentType, Group
# GroupView继承的是ModelViewSet 所以修改逻辑还是使用同一个类视图
class GroupView(ModelViewSet):
serializer_class = GroupSerialzier
queryset = Group.objects.all()
pagination_class = PageNum
# 获取权限表数据
def simple(self, reqeust):
pers = Permission.objects.all()
ser = PermissionSerialzier(pers, many=True) # 使用以前定义的全选序列化器
return Response(ser.data)删除分组表数据
接口分析
请求方式: Delte /meiduo_admin/permission/groups/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中携带删除的分组表的id值
返回数据: JSON
返回空
后端实现
from django.contrib.auth.models import Permission, ContentType, Group
# GroupView继承的是ModelViewSet 所以删除逻辑还是使用同一个类视图
class GroupView(ModelViewSet):
serializer_class = GroupSerialzier
queryset = Group.objects.all()
pagination_class = PageNum
# 获取权限表数据
def simple(self, reqeust):
pers = Permission.objects.all()
ser = PermissionSerialzier(pers, many=True) # 使用以前定义的全选序列化器
return Response(ser.data)管理员信息管理
在系统管理中我们需要完成管理员表的增删改查,这时候我们可以借助于视图集中的ModelViewset来完成相应的操作
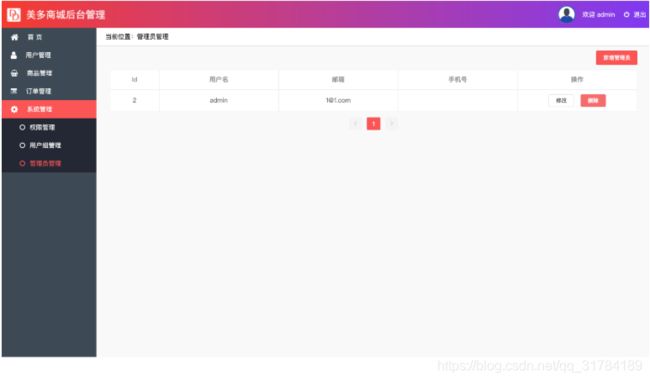
获取管理员用户列表数据
接口分析
请求方式: GET /meiduo_admin/permission/admins/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"id": "用户id",
"username": "用户名",
"email": "邮箱",
"mobile": "手机号"
}
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| id | int | 是 | 用户id |
| username | str | 是 | 用户名 |
| str | 是 | 页码 | |
| mobile | str | 是 | 总页数 |
后端实现
class AdminView(ModelViewSet):
serializer_class = AdminSerializer
# 获取管理员用户
queryset = User.objects.filter(is_staff=True)
pagination_class = PageNum
序列化器的定义
class AdminSerializer(serializers.ModelSerializer):
class Meta:
model=User
fields="__all__"
extra_kwargs={
'password':{
'write_only': True
}
}保存管理员数据
在保存数据之前我们需要获取权限表数据和分组表数据展示,权限表数据的获取接口已经完成,我们只需要获取分组表数据
1、获取分组表数据
接口分析
请求方式: GET /meiduo_admin/permission/groups/simple/
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
[
{
"id": 1,
"name": "广告组"
},
{
"id": 2,
"name": "商品SKU组"
},
......
]
| 返回值 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| Id | int | 是 | 分组id |
| name | 数组 | 是 | 分组名称 |
后端实现
# AdminView继承的是ModelViewSet 所以获取分组逻辑还是使用同一个类视图
class AdminView(ModelViewSet):
serializer_class = AdminSerializer
queryset = User.objects.filter(is_staff=True)
pagination_class = PageNum
# 获取分组数据
def simple(self, reqeust):
pers = Group.objects.all()
ser = GroupSerialzier(pers, many=True)
return Response(ser.data)
2、保存管理员数据
接口分析
请求方式:POST /meiduo_admin/permission/admins/
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| password | int | 是 | 密码 |
| str | 否 | 邮箱 | |
| groups | list | 是 | 用户组id |
| user_permissions | list | 是 | 权限id |
返回数据: JSON
{
"id": "用户id",
"username": "用户名",
"password": "密码",
"mobile": "手机号",
"email": "邮箱",
"groups": ['用户组id', ...],
"user_permissions": ['权限id', ...]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| str | 否 | 邮箱 | |
| groups | list | 是 | 用户组id |
| user_permissions | list | 是 | 权限id |
后端实现
# AdminView继承的是ModelViewSet 所以保存分组逻辑还是使用同一个类视图
class AdminView(ModelViewSet):
serializer_class = AdminSerializer
queryset = User.objects.filter(is_staff=True)
pagination_class = PageNum
# 获取分组数据
def simple(self, reqeust):
pers = Group.objects.all()
ser = GroupSerialzier(pers, many=True)
return Response(ser.data)
序列化器
class AdminSerializer(serializers.ModelSerializer):
class Meta:
model=User
fields="__all__"
extra_kwargs={
'password':{
'write_only': True
}
}
# 重写父类方法,增加管理员权限属性
def create(self, validated_data):
# 添加管理员字段
validated_data['is_staff'] = True
# 调用父类方法创建管理员用户
admin = super().create(validated_data)
# 用户密码加密
password = validated_data['password']
admin.set_password(password)
admin.save()
return admin更新管理员数据
1、 获取修改管理员的详情信息
点就修改按钮时,我们需要先获取要修改的分组表详情信息
接口分析
请求方式: GET /meiduo_admin/permission/admins/(?P
请求参数: 通过请求头传递jwt token数据。
返回数据: JSON
{
"id": "用户id",
"username": "用户名",
"mobile": "手机号",
"email": "邮箱",
"groups": ['用户组id', ...],
"user_permissions": ['权限id', ...]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| str | 否 | 邮箱 | |
| groups | list | 是 | 用户组id |
| user_permissions | list | 是 | 权限id |
后端实现
# AdminView继承的是ModelViewSet 所以管理员详情逻辑还是使用同一个类视图
class AdminView(ModelViewSet):
serializer_class = AdminSerializer
queryset = User.objects.filter(is_staff=True)
pagination_class = PageNum
# 获取分组数据
def simple(self, reqeust):
pers = Group.objects.all()
ser = GroupSerialzier(pers, many=True)
return Response(ser.data)
2、修改管理员
接口分析
请求方式: PUT /meiduo_admin/permission/admins/(?P
请求参数: 通过请求头传递jwt token数据。
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| password | int | 是 | 密码 |
| str | 否 | 邮箱 | |
| groups | list | 是 | 用户组id |
| user_permissions | list | 是 | 权限id |
返回数据: JSON
{
"id": "用户id",
"username": "用户名",
"password": "密码",
"mobile": "手机号",
"email": "邮箱",
"groups": ['用户组id', ...],
"user_permissions": ['权限id', ...]
}
| 参数 | 类型 | 是否必须 | 说明 |
|---|---|---|---|
| username | str | 是 | 用户名 |
| mobile | str | 是 | 手机号 |
| password | int | 是 | 密码 |
| str | 否 | 邮箱 | |
| groups | list | 是 | 用户组id |
| user_permissions | list | 是 | 权限id |
后端实现
# AdminView继承的是ModelViewSet 所以管理员信息修改逻辑还是使用同一个类视图
class AdminView(ModelViewSet):
serializer_class = AdminSerializer
queryset = User.objects.filter(is_staff=True)
pagination_class = PageNum
# 获取分组数据
def simple(self, reqeust):
pers = Group.objects.all()
ser = GroupSerialzier(pers, many=True)
return Response(ser.data)删除管理员信息数据
接口分析
请求方式: Delte /meiduo_admin/permission/admins/(?P
请求参数: 通过请求头传递jwt token数据。
在路径中携带删除的用户id值
返回数据: JSON
返回空
后端实现
# AdminView继承的是ModelViewSet 所以删除逻辑还是使用同一个类视图
class AdminView(ModelViewSet):
serializer_class = AdminSerializer
queryset = User.objects.filter(is_staff=True)
pagination_class = PageNum
# 获取分组数据
def simple(self, reqeust):
pers = Group.objects.all()
ser = GroupSerialzier(pers, many=True)
return Response(ser.data)