MHA + keepalived
1.keepalived
通过VRRP协议来保证高可用性
- VRRP是一种容错协议,它通过把几台路由设备联合组成一台虚拟的路由设备,并通过一定的机制来保证当主机的下一跳设备出现故障时,可以及时将业务切换到其它设备,从而保持通讯的连续性和可靠性。
- VRRP是一种容错协议,它通过把几台路由设备联合组成一台虚拟的路由设备,并通过一定的机制来保证当主机的下一跳设备出现故障时,可以及时将业务切换到其它设备,从而保持通讯的连续性和可靠性。
- VRRP将局域网内的一组路由器划分在一起,称为一个备份组。备份组由一个Master路由器和多个Backup路由器组成,功能上相当于一台虚拟路由器。局域网内的主机只需要知道这个虚拟路由器的IP地址,并不需知道具体某台设备的IP地址,将网络内主机的缺省网关设置为该虚拟路由器的IP地址,主机就可以利用该虚拟网关与外部网络进行通信。
- VRRP将该虚拟路由器动态关联到承担传输业务的物理路由器上,当该物理路由器出现故障时,再次选择新路由器来接替业务传输工作,整个过程对用户完全透明,实现了内部网络和外部网络不间断通信。
- VRRP可以将两台或者多台物理路由器设备虚拟成一个虚拟路由,这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,这台物理路由设备被成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等,而且其它的物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为“BACKUP的角色”,当主路由器失败时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色,继续提供对外服务,整个切换对用户来说是完全透明的。
- 每个虚拟路由器都有一个唯一的标识号,称为VRID,一个VRID与一组IP地址构成一个虚拟路由器,在VRRP协议中,所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一一般不会发生BACKUP抢占的情况,除非它的优先级更高,而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
Master路由的选举
- 备份组中路由器的优先级:VRRP根据优先级来确定备份组中每台路由器的角色(Master路由器或Backup路由器)。优先级越高,则越有可能成为Master路由器。当两台优先级相同的路由器同时竞争Master时,比较接口IP地址大小。接口地址大者当选为Master。IP地址所有者自动具有最高优先级:255。因此,当备份组内存在IP地址拥有者时,只要其工作正常,则为Master路由器。
- 备份组中路由器的工作方式:抢占方式与非抢占方式
VRRP的工作过程为:
- 路由器使能VRRP功能后,会根据优先级确定自己在备份组中的角色。优先级高的路由器成为Master路由器,优先级低的成为Backup路由器。Master路由器定期发送VRRP通告报文,通知备份组内的其他路由器自己工作正常;Backup路由器则启动定时器等待通告报文的到来。
- 在抢占方式下,当Backup路由器收到VRRP通告报文后,会将自己的优先级与通告报文中的优先级进行比较。如果大于通告报文中的优先级,则成为Master路由器;否则将保持Backup状态。
在非抢占方式下,只要Master路由器没有出现故障,备份组中的路由器始终保持Master或Backup状态,Backup路由器即使随后被配置了更高的优先级也不会成为Master路由器。 - 如果Backup路由器的定时器超时后仍未收到Master路由器发送来的VRRP通告报文,则认为Master路由器已经无法正常工作,此时Backup路由器会认为自己是Master路由器,并对外发送VRRP通告报文。备份组内的路由器根据优先级选举出Master路由器,承担报文的转发功能。
keepalived原理:
- keepalived安装在两台物理服务器上 并互相监控对方是否正常运行
- 当A工作正常的时候 会将VIP对应的MAC地址为节点A网卡的MAC地址
- 当A发生故障的时候 节点B上的keepalived会检测到 并将VIP的MAC等于B的MAC地址
- Keepalived的部署比较容易,直接可以yum 安装,主要的就是他的参数文件,参数文件是如何控制主备的。
vrrp_script chk_port_3306 {
script"/opt/dtstack/dtagent/agent/mysqlha_check_alive.py 3306"
interval 11# check every 2 seconds
fall 3# require 2 failures for KO
rise 3# require 2 successes for OK
timeout 11
}
- 第一部分,检测系统上3306端口,监控的途径是通过/opt/dtstack/dtagent/agent/mysqlha_check_alive.py 3306这条命令来判断的,就是判断系统3306端口是否存在,如果你的MySQL是别的端口,那么就需要作下更改,脚本是一大神写的,就不贴出来了。
vrrp_instance mysql_3306 {
state MASTER
interface eth0 #检测eth0
garp_master_delay 5
virtual_router_id 231 #路由组
priority 251 #权重
advert_int 1
- 第二部分,这一部分主要决定的你这台机器上的3306端口是否是主库,而且这台机器的外网是不是eth0网卡上。virtual_router_id这个参数主库跟备库必须要一样,这样告知Keepalived他需要看到是那一个路由组的机器。priority权重约大,那么主库的方向就越往哪台机器上偏。
authentication {
auth_type PASS
auth_pass PASS3306
}
virtual_ipaddress {
192.168.40.231/24 dev eth0 # vip是192.168.40.231/24 起在eth0上
}
track_script {
chk_port_3306 # 检测3306端口
}
- 第三部分,这一部分就是实现2变1的地方,起一个vip到eth0网卡上,当某台数据库为主库的时候,那么这个vip就会票到这个台机器的eth0网卡上。
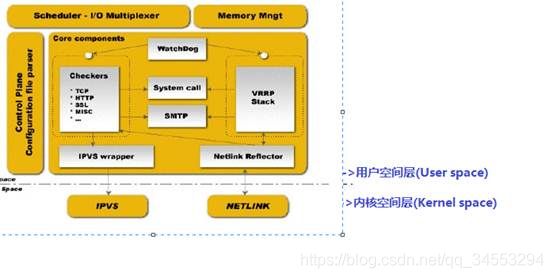
Keepalived体系结构
脑裂问题出现原因
- 两个服务器端的keepalived之间的心跳获得另一个服务器的信息。当slave无法获取master的信息时,slave会对外提供服务,此时就会出现脑裂的问题(两个服务器使用同一ip对外提供服务)。
脑裂问题处理
- 设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
- 可以通过在slave库增加检测脚本,若检测到VIP漂移到了当前服务器上,则kill掉原master库的mysql进程。
keepalived安装与配置
| IP | 主机名 | 角色 | mha角色 |
|---|---|---|---|
| 192.168.2.61 | node1 | 主库 | node |
| 192.168.2.62 | node2 | 从库1 | node |
| 192.168.2.63 | node3 | 从库2 | node , mha-master |
1.安装keepalived
yum -y install keepalived
2.配置keepalived
node1修改keepalived配置文件
[root@node1 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MySQL-HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.6.66/24
}
}
node2修改keepalived配置文件
[root@node2 ~]# cat /etc/keepalived/keepalived.conf
global_defs {
notification_email {
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id MySQL-HA
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.6.66/24
}
}
2.MHA
原理
- 1.一主两从架构,主库挂了,但主库能被从库ssh上去的情况下,MHA从三个从库中选择同步最接近的作为新主,然后新主和s2都ssh到原主上通过binlog补上还没有同步的数据,io_thread读取到binlog位置,传到save_binary_logs,然后回放,达到s1,s2和原主一致。
- 2.主库无法ssh上去的情况下,即主库的系统无法连接,假设有binlog server ,利用binlog补数据,和前面情况一样;如果没有binlog server,假设s1靠前,s2会通过relay-log和s1同步(所以从库的relay不能自动清除参数relay_log_purge = 0) ,提升s1为主,把s2作为s1的从;
- 5.6之后,如果有一主两从的架构,使用GTID复制,keepalived+一主两从,并且其中一个从库使用半同步复制,这样完全可以取代MHA,这就是为什么MHA代码为什么不更新,out的原因。
MHA切换步骤
- 从宕机的master中保存二进制文件
- 检测含有最新日至更新的slave
- 应用差异的中继日至(relay log)到其他的slave
- 应用从master中保存的二进制日至事件到其他的slave中
- 提升一个slave为master
- 使其他的slave指向最新的master进行复制。
manager的工具
- masterha_check_ssh 检查MHA的SSH配置状况
- masterha_check_repl 检查MySQL复制状况
- masterha_manger 启动MHA
- masterha_check_status 检测当前MHA运行状态
- masterha_master_monitor 检测master是否宕机
- masterha_master_switch 控制故障转移(自动或者手动)
- masterha_conf_host 添加或删除配置的server信息、
node的工具
- save_binary_logs 保存和复制master的二进制日志
- apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave
- filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
- purge_relay_logs 清除中继日志(不会阻塞SQL线程)
MHA自动切换流程
- 检测master的状态,方法是一秒一次“ SELECT 1 As Value”,发现没有响应后会重复3次检查,如果还没有响应,shutdown并再重复一次SELECT 1 As Value确认master关闭
- 确认SSH到master所在的机器是否可达
- 给出消息:Connecting to a master server failed,并开始读取配置文件masterha_default.conf和app1.conf,确认复制切换模式: [info] GTID failover mode = 1
- 报告整个架构中的机器存活情况
Fri Jul 1 13:35:33 2016 - [info] Dead Servers:
Fri Jul 1 13:35:33 2016 - [info] 192.168.118.63(192.168.118.63:3306)
Fri Jul 1 13:35:33 2016 - [info] Alive Servers:
Fri Jul 1 13:35:33 2016 - [info] 192.168.118.62(192.168.118.62:3306)
Fri Jul 1 13:35:33 2016 - [info] 192.168.118.64(192.168.118.64:3306)
- 检查存活的实例版本、GTID开启情况、是否开启read_only以及复制过滤情况
Fri Jul 1 13:35:33 2016 - [info] Alive Slaves:
Fri Jul 1 13:35:33 2016 - [info] 192.168.118.62(192.168.118.62:3306) Version=5.6.28-log (oldest major version between slaves) log-bin:enabled
Fri Jul 1 13:35:33 2016 - [info] GTID ON
Fri Jul 1 13:35:33 2016 - [info] Replicating from 192.168.118.63(192.168.118.63:3306)
Fri Jul 1 13:35:33 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Jul 1 13:35:33 2016 - [info] 192.168.118.64(192.168.118.64:3306) Version=5.6.28-log (oldest major version between slaves) log-bin:enabled
Fri Jul 1 13:35:33 2016 - [info] GTID ON
Fri Jul 1 13:35:33 2016 - [info] Replicating from 192.168.118.63(192.168.118.63:3306)
Fri Jul 1 13:35:33 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Jul 1 13:35:33 2016 - [info] Checking slave configurations..
Fri Jul 1 13:35:33 2016 - [info] read_only=1 is not set on slave 192.168.118.62(192.168.118.62:3306).
Fri Jul 1 13:35:33 2016 - [info] read_only=1 is not set on slave 192.168.118.64(192.168.118.64:3306).
Fri Jul 1 13:35:33 2016 - [info] Checking replication filtering settings..
Fri Jul 1 13:35:33 2016 - [info] Replication filtering check ok.
- 在GTID复制基础上的切换过程
- (1) 配置检查阶段,具体检查如下
[info] ** Phase 1: Configuration Check Phase completed.
检查项目如下:
Query SELECT @@global.server_id As Value
Query SELECT VERSION() AS Value #如果是GTID模式,版本不得小于5.6,如果是普通模式,版本不得小于5.0.45
Query SELECT @@global.gtid_mode As Value #MHA0.56版本开始支持GTID,之前的版本不支持
Query SHOW GLOBAL VARIABLES LIKE 'log_bin' #binlog必须开启
Query SHOW MASTER STATUS
Query SELECT @@global.datadir AS Value
Query SELECT @@global.slave_parallel_workers AS Value #确定slave是不是多线程并行复制,这个参数的影响还没整明白,再研究下
Query SHOW SLAVE STATUS
Query SELECT @@global.read_only As Value #确定read_only的设置,如果要转为新的master,这个值要设为0
Query SELECT @@global.relay_log_purge As Value #确定relay_log是否可自动删除,默认是可以
Query SELECT @@global.relay_log_info_repository AS Value #确定relay_log是以file还是table格式存放的,默认是file
Query SELECT @@global.datadir AS Value #确定数据存放位置
Query SELECT @@global.relay_log_info_file AS Value #确定relay_log的文件名,为后面slave之间的relay_log应用做准备
备注:1. 默认情况下,从服务器上的中继日志在SQL线程执行完后会被自动删除的。但是这些中继日志在恢复其他从服务器时候可能会被用到,因此需要禁用中继日志的自动清除和定期清除旧的中继日志
2. binlog-do-db和replicate-ignore-db设置必须相同。MHA在启动时候会检测过滤规则,如果过滤规则不同,MHA不启动监控和故障转移
- (2)彻底关闭master连接的阶段,避免master未关闭导致的脑裂
[info] * Phase 2: Dead Master Shutdown Phase..
具体关闭命令是:
/etc/masterha/master_ip_failover --orig_master_host=192.168.118.3 --orig_master_ip=192.168.118.3 --orig_master_port=3306 --command=stopssh --ssh_user=root
关闭完成后给出报告
[info] * Phase 2: Dead Master Shutdown Phase completed.
- (3)master恢复阶段:
[info] * Phase 3: Master Recovery Phase..
- 确认新的master后,会选取含有最新relay log 的slave,在该slave上设置sql_log_bin=0并在其余slaves上应用该最新relay log,最终获得这个层次的数据一致性,之后再set sql_log_bin=1使恢复日志写入。可以通过半同步复制来解决无法ssh到master所在机器所造成的事务丢失问题,待全部数据一致后,通过show master status确定新master的日志位置并在其他slave上执行change master语句创建新的主从连接:
Fri Jul 1 13:35:33 2016 - [info] Getting new master's binlog name and position..
Fri Jul 1 13:35:33 2016 - [info] mysql-bin.000004:191
Fri Jul 1 13:35:33 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.118.2', MASTER_PORT=3306, MAST
ER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='xxx';
- 执行该切换的具体语句是
/etc/masterha/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.118.3 --orig_master_ip=192.168.118.3 --orig_master_port=3306 --new_master_host=192.168.118.2 --new_master_ip=192.168.118.2 --new_master_port=3306 --new_master_user='user' --new_master_password='password'
- 该阶段成果后给出报告
Fri Jul 1 13:35:33 2016 - [info] ** Finished master recovery successfully.
Fri Jul 1 13:35:33 2016 - [info] * Phase 3: Master Recovery Phase completed.
- (4)slaves恢复阶段
[info] * Phase 4: Slaves Recovery Phase..
- 先停止IO线程,等待SQL线程执行完成后,stop slave,清除原slave信息,重新change master指向新的master,start slave ,over
Query SHOW SLAVE STATUS
Query STOP SLAVE IO_THREAD
Query SHOW SLAVE STATUS
Query SHOW SLAVE STATUS
Query STOP SLAVE
Query SHOW SLAVE STATUS
Query RESET SLAVE
Query CHANGE MASTER TO MASTER_HOST = '192.168.118.62' MASTER_USER = 'repl' MASTER_PASSWORD = MASTER_PORT = 3306
Query START SLAVE
Connect Out [email protected]:3306
Query SHOW SLAVE STATUS
- (5)清除新选出的master上的slave信息
reset slave all;
安装过程参考网页
https://blog.csdn.net/Mryiyi/article/details/73822952