Linux动态库与静态库(二)
一、ldd指令
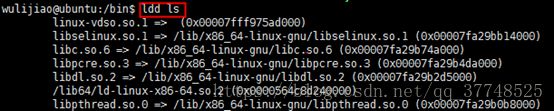
(借鉴来自:https://www.jb51.net/LINUXjishu/179400.html)
1.指令参数
--version 打印ldd版本信息,eg:显示ldd (Ubuntu GLIBC 2.23-0ubuntu9) 2.23....
-v --version 打印所有信息,包括符号版本信息
-d --data-relocs 执行符号重部署,并报告缺少的目标对象(只对ELF格式文件生效)
-r --function-relocs 对目标对象和函数执行重部署,并报告缺少的对象与函数
2.ldd的本质:shell脚本
wulijiao@ubuntu:/$ which ldd
/usr/bin/ldd
wulijiao@ubuntu:/$ file /usr/bin/ldd
/usr/bin/ldd: Bourne-Again shell script, ASCII text executable
通过设置相关的环境变量而实现的。
ldd默认开启的环境变量是:LD_TRACE_LOADED_OBJECTS=1
其他的变量(和值)分别对应一些选项:
-d, --data-relocs -> LD_WARN=yes
-r, --function-relocs ->LD_WARN和LD_BIND_NOW=yes
-u, --unused -> LD_DEBUG="unused"
-v, --verbose -> LD_VERBOSE=yes
LD_TRACE_LOADED_OBJECTS为必要环境变量,其他视具体情况。
ldd命令的本质是执行了:/lib/ld-linux.so.*,读取了ldconfig命令组建起来的文件(/etc/ld.so.cache)。
一般ld-linux.so会按照以下顺序搜索共享库:
1、DT_RPATH或DT_RUNPATH段
2、环境变量LD_LIBRARY_PATH
3、/etc/ld.so.cache文件中的路径,但如果可执行程序在连接时候添加了-z nodeflib选项,则跳过。
4、默认路径/lib和/usr/lib,但如果添加了-z nodeflib,则跳过。
二、nm指令分析
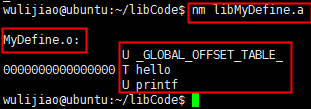
我对nm指令最初的认识就是可以列出二进制文件的符号列表(变量和函数)。
1.指令参数说明:
-a/-debug-syms:显示调试信息
-B/--format=bsd,用于对MIPS的兼容
-C/-demangle,将低级符号解码为用户级名字
-D/--dynamic 显示动态符号(仅对动态目标生效)
-f format(bsd-默认,sysv,posix)
-g/--extern-only 仅显示外部符号
-n,-v/--numeric-sort 按照符号对应地址的顺序排序
-p/--no-sort 按目标文件中遇到的符号顺序显示,不排序
-P/--portability 使用posix.2标准输出格式取代默认输出格式
-s/--print-armap 列出库中的成员符号及索引
-r/--reverse-sort 反转排序的顺序
--size-sort 按照大小排列符号顺序
-t radix/--radix=radix 使用radix显示符号值
--target=bfdname 指定目标代码的格式
-u/-undefined-only 仅仅显示未定义的符号
-l/--line-numbers 对每个符号,使用调试信息来试图找到文件名和行号。对已定义符号,查找符号地址的行号。对未定义符号,查找指向符号重定位入口的行号。如果可以找到行号信息,显示在符号信息之后。
-V/--version 显示nm的版本号
--help
2.指令符号输出说明
A 该符号值是绝对的,在以后的链接过程中不可以改变。(常出现在中断向量表中,表示哥中断函数的位置)
B 出现于非初始化数据段(bss:未初始化的全局变量和静态变量)中,其值表示在bss段中的偏移。
C 未初始化数据段,为包含在数据段中,只有在链接过程中才可以进行分配。符号值,表示该符号所需要的字节数。该符号的空间不在执行文件中,而是在初始化环境是进行分配的,不会被清零,可以读写。
D 该符号位于初始化数据段中,data section。该符号所占空间存在于执行文件中,初始化执行环境的时候进行分配的,复制数据到执行空间,可以被读写。
G 位于初始化数据段中,主要用于小文件,提高对晓得目标文件的访问。
I 表示该符号对另一个符号的间接引用。
N 调试信息debugging 符号。
R 只读数据区,例如定义全局const int test[] = {123, 123};则test就是一个只读数据区的符号。注意在cygwin下如果使用gcc直接编译成MZ格式时,源文件中的test对应_test,并且其符号类型为D,即初始化数据段中。但是如果使用m6812-elf-gcc这样的交叉编译工具,源文件中的test对应目标文件的test,即没有添加下划线,并且其符号类型为R。一般而言,位于rodata section。值得注意的是,如果在一个函数中定义const char *test = “abc”, const char test_int = 3。使用nm都不会得到符号信息,但是字符串“abc”分配于只读存储器中,test在rodata section中,大小为4。
S 位于非初始化数据区。
T 位于代码区。
U 相对于当前文件该符号未被定义。
V 弱文件引用。
W 符号是一个弱符号,没有被特别标记为弱对象符号。
- 次符号,默认输出文件a.out中调试信息符号
? 该符号未定义
2.对nm指令源码分析
我们可以到http://ftp.gnu.org/gnu/binutils/上下载相关的nm源码,在下图的文件夹下可以找到nm.c文件。

函数内容较多,我们从main函数作为入口,对其进行简析。
首先是对本地信息的一些配置,启动进程,进行bfd库的初始化并进行匹配,这个只是个人的理解,仅供参考。接着是对输入指令参数的判断,执行相应的操作(将对应的标志参数进行设置),深入宏定义可以看到@bfd_version_string@宏定义这种的是linux特殊的定义方式,感兴趣可以去深入的研究一下,里面有很多bfd的函数,这又是一个需要深入的地方。
(1)----$nm -V 版本信息查询指令源码进行分析:
终端执行显示

源码分析:
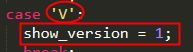
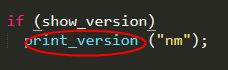

上下结果对比,一些不一样知识因为我使用的linux系统版本与源码分析使用的版本不一样,但是还是可以明白这个过程的。
(2)----$nm filename.* 无指令参数时,对文件的解析过程,源码分析。
对输入命令进行判断,如下是没有参数的文件解析,display_file便是对文件进行字符解析函数;
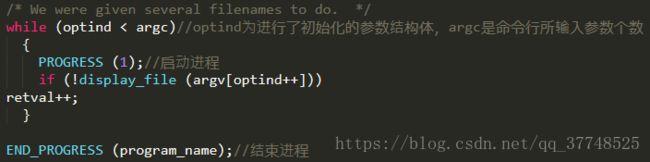
下面是display_file的函数,其先对文件进行判断之后再进行数据的解析,否则进行错误的输出:

对于其函数,很多都是对BFD库的调用。
bfd库是什么?
全称为--二进制文件格式描述符,其是bin-util二进制操作工具集(eg:ar、nm、ld等)对目标文件操作的接口,各指令的实现也是通过对bfd库的调用,进而对目标文件的二进制格式进行判断。
三.ar命令

ar[-dmpqrtx][cfosSuvV][a<成员文件>][b<成员文件>][i<成员文件>][备存文件][成员文件]
ar可让您集合许多文件,成为单一的备存文件。在备存文件中,所有成员文件皆保有原来的属性与权限
- 参数
必要参数:
d 删除备存文件中的成员文件。
-m 变更成员文件在备存文件中的次序。
-p 显示备存文件中的成员文件内容。
-q 将文件附加在备存文件末端。
-r 将文件插入备存文件中。
-t 显示备存文件中所包含的文件。
-x 自备存文件中取出成员文件。
选项参数:
a<成员文件> 将文件插入备存文件中指定的成员文件之后。
b<成员文件> 将文件插入备存文件中指定的成员文件之前。
c 建立备存文件。
f 为避免过长的文件名不兼容于其他系统的ar指令指令,因此可利用此参数,截掉要放入备存文件中过长的成员文件名称。
i<成员文件> 将问家插入备存文件中指定的成员文件之前。
o 保留备存文件中文件的日期。
s 若备存文件中包含了对象模式,可利用此参数建立备存文件的符号表。
S 不产生符号表。
u 只将日期较新文件插入备存文件中。
v 程序执行时显示详细的信息。
V 显示版本信息

ar指令值对别人只是的引用,我个人没有实际的进行操作。来自:http://www.runoob.com/linux/linux-comm-ar.html
四、PIC(Position Independent Code:地址无关代码)
其代码中使用的都是相对地址,即它的地址都是相对于当前的工作路径来定的,当基地址发生改变的时候,并不影响运行程序对代码的加载。于是我们的代码可以加载到内存的任意位置,正因如此,这正是我们的库需要被共享所需要的性质,不同的使用者所对应的内存的位置也不同。
相反,如果我们不使用地址无关的代码生成方式,代码段在被引用的时候就需要进行重定位,将编译与链接后的指令及数据所用相对地址转换为内存单元的实际地址,这样便会修改代码段的内容。不同的使用者都会修改代码段,从而无法实现库的共享。