神经网络解决推荐系统问题(ONCF)
Outer Product-based Neural Collaborative Filtering(ONCF)
ϕ G M F = p u G ⊙ q i G , ϕ M L P = a L ( W L T ( a L − 1 ( . . . a 2 ( W 2 T [ p u M q i M ] + b 2 ) . . . ) ) + b L ) , y ^ u i = σ ( h T [ ϕ G M F ϕ M L P ] ) . \phi^{GMF}={\bf p}_u^G\odot{\bf q}_i^G,\\\phi^{MLP}=a_{L}(W_L^T(a_{L-1}(...a_{2}(W_2^T\begin{bmatrix}{{\bf p}_u^M}\\{{\bf q}_i^M}\end{bmatrix}+{\bf b}_2)...))+{\bf b}_L),\\\widehat{y}_{ui}=\sigma({\bf h}^T\begin{bmatrix}{\phi^{GMF}}\\{\phi^{MLP}}\end{bmatrix}).\ \ \ \ ϕGMF=puG⊙qiG,ϕMLP=aL(WLT(aL−1(...a2(W2T[puMqiM]+b2)...))+bL),y ui=σ(hT[ϕGMFϕMLP]).
1)回顾CF,设计CF模型的关键在于:1)如何表示用户和项目;2)如何在表示的基础上对用户和项目的交互进行建模。
2)回顾MF,MF是将用户表示为潜在因素的向量(embedding),并将交互作用建模为内积—— f ( p , q ) = p T q ∈ R f(p,q) = p^Tq \in \mathbb{R} f(p,q)=pTq∈R,正是MF使用了一个固定的、依赖于数据的函数,即函数内积作为交互作用函数,特别是在NCF中指出的MF的局限性限制了它的表达。而且它假定嵌入维(即embedding维数)彼此相互独立,并对所有数据点的预测做出了同样的贡献,如p , q。而恰恰embedding是可以解释为项目的某些属性不一定是独立的,能产生更好的组合,可能是存在有不同的权重,如AFM。
然后由于NCF直接从DNN中学习,效果很不错,只是NCF及其变体模型大多采用特征向量内积、拼接操作的局限性(如最上的NCF处理公式),即NCF的设计的潜在局限性在于用户和项目的embedding之间几乎没有关联。所以原作者团队又提出了一种基于 外积 的新的特征交互模型ONCF,并用CNN卷积*处理学习特征中每一维的高阶相互关系,也就是显式的捕捉嵌入维数之间的成对关联。
首先内积与外积,向量的点乘与叉乘,一个按对应元素相乘,一个按矩阵运算相乘。
![]()

这就让外积后的向量变成了一个能刻画每维之间的关系的矩阵,然后就在这个特征交互的矩阵上采用 CNN,从局部和全局,对每个维度进行高阶的交互。模型架构如下:
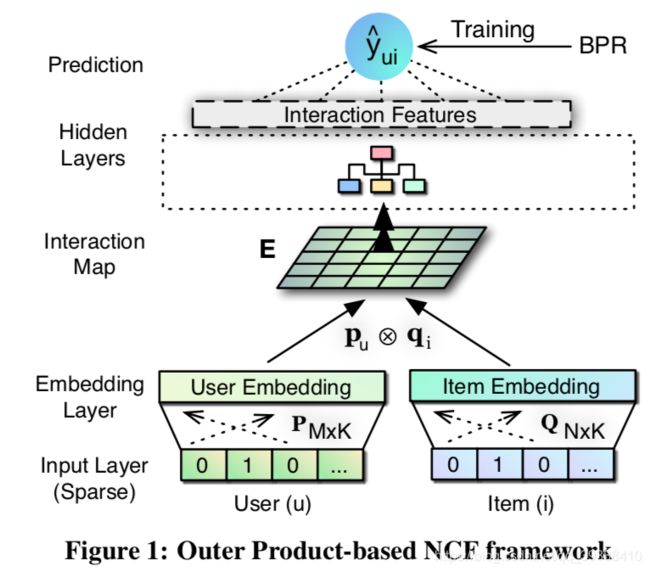
模型同样是先embedding,然后使用外积得到交叉映射 Interaction Map(是KxK的矩阵,K是embedding维数),然后使用CNN结构得到预测值,而且损失函数用了前一篇整理过的BPR损失来优化正例的排名,减少负例的影响。所以损失函数变成: L ( Δ ) = ∑ ( u , i , j ) ∈ D − ln σ ( y ^ u i − y ^ u j ) + λ Δ ∣ Δ ∣ 2 L(\Delta) = \sum\limits_{(u,i,j) \in \mathcal{D}} - \ln \sigma(\hat{y}_{ui} - \hat{y}_{uj}) + \lambda_\Delta |\Delta|^2 L(Δ)=(u,i,j)∈D∑−lnσ(y^ui−y^uj)+λΔ∣Δ∣2其中的D是能观测到的正例,同样对其使用梯度得到其他所需要的所有参数。
卷积NCF的卷积部分如下,具体也和与卷积大家族中的各位差不多。
- 对于64x64的 interaction Map,使用2x2的卷积核,激活函数选为RELU,每层得到32个Feature Map。整体下来参数的规模也不算很大,却又很好的学习到了交互信息。
部分代码为:
def _create_placeholders(self):
with tf.name_scope("input_data"):
self.user_input = tf.placeholder(tf.int32, shape = [None, 1], name = "user_input")
self.item_input_pos = tf.placeholder(tf.int32, shape = [None, 1], name = "item_input_pos")#正例
self.item_input_neg = tf.placeholder(tf.int32, shape = [None, 1], name = "item_input_neg")#负例
self.keep_prob = tf.placeholder(tf.float32, name = "keep_prob")#dropout比率
def _conv_weight(self, isz, osz):#CNN权重
return (weight_variable([2,2,isz,osz]), bias_variable([osz]))
#卷积层
def _conv_layer(self, input, P):
conv = tf.nn.conv2d(input, P[0], strides=[1, 2, 2, 1], padding='SAME')
return tf.nn.relu(conv + P[1])
def _create_variables(self):
with tf.name_scope("embedding"):#初始化P和Q的embedding变量
self.embedding_P = tf.Variable(tf.truncated_normal(shape=[self.num_users, self.embedding_size], mean=0.0, stddev=0.01),
name='embedding_P', dtype=tf.float32) #(users, embedding_size)
self.embedding_Q = tf.Variable(tf.truncated_normal(shape=[self.num_items, self.embedding_size], mean=0.0, stddev=0.01),
name='embedding_Q', dtype=tf.float32) #(items, embedding_size)
#64x64,6层网络,所以使用6层的iszs
iszs = [1] + self.nc[:-1]
oszs = self.nc
self.P = []
for isz, osz in zip(iszs, oszs):
self.P.append(self._conv_weight(isz, osz))
self.W = weight_variable([self.nc[-1], 1])
self.b = weight_variable([1])
#卷积NCF
def _create_inference(self, item_input):
with tf.name_scope("inference"):
##分别得到embedding的P和Q
self.embedding_p = tf.nn.embedding_lookup(self.embedding_P, self.user_input)
self.embedding_q = tf.nn.embedding_lookup(self.embedding_Q, item_input)
#使用matmul函数外积 P_u 和 Q_i
self.relation = tf.matmul(tf.transpose(self.embedding_p, perm=[0, 2, 1]), self.embedding_q)
self.net_input = tf.expand_dims(self.relation, -1)
# CNN
self.layer = []
input = self.net_input
for p in self.P:
self.layer.append(self._conv_layer(input, p))
input = self.layer[-1]
# prediction
self.dropout = tf.nn.dropout(self.layer[-1], self.keep_prob)
self.output_layer = tf.matmul(tf.reshape(self.dropout,[-1,self.nc[-1]]), self.W) + self.b
return self.embedding_p, self.embedding_q, self.output_layer
ONCF通过外积操作形成一个更具表现力的二维交互映射。而交互映射可以说是非常适合CF任务,因为它不仅包含MF(其对角线)中与内积的中间结果,也产生了所有其他维度的两两关联。交互映射中这种丰富的语义为以下非线性层提供了便利,从而学习可能的高阶维关联。使用了卷积神经网络学习它,从参数和规模上也合理,损失函数也采用了BRP的优化,很精彩的模型。
完整代码的逐行源码阅读笔记在 :https://github.com/nakaizura/Source-Code-Notebook/tree/master/ONCF
我简陋的复现结果: