scrapy 爬取拉勾网职位信息
需求:1.使用python爬虫框架,爬取拉勾网职位信息,
2.将爬取的职位信息存储到json格式的文件中
3.将爬取的数据进行数据分析

1.图片中的链接是职位列表页的链接,进行翻页,该链接没有变化,无法从该链接中爬取数据
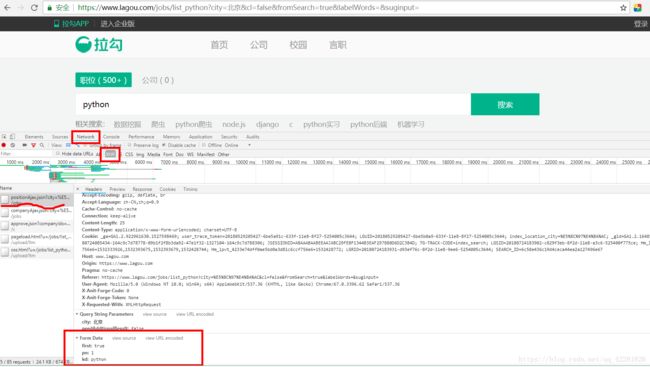
2.打开浏览器开发者模式,点击network的XHR,同时刷新页面,会出现ajax请求是post请求,红框中的Form Data是ajax请求需要携带的数据,kd是要搜索的职位

3.点击红框中的Response会看到ajax请求回的数据,
以上是拉勾网职位列表页分析,接下来进行网页信息爬取
步骤:
一.
创建scrapy项目:scrapy startproject lagouscrapy
进入项目目录中:cd lagouscrapy
创建爬虫文件:scrapy genspider worklagou lagou.com
二.使用pycharm编辑项目
1.编辑item.py文件,编辑要爬取的字段
import scrapy
class SelflagouItem(scrapy.Item):
# 爬取职位名称,学历要求,公司名称,工作经历,公司位置,工资水平几个字段
title=scrapy.Field()
education=scrapy.Field()
company=scrapy.Field()
experience=scrapy.Field()
location=scrapy.Field()
salary=scrapy.Field()
2.编写爬虫 worklagou.py文件
根据以上分析,拉勾网的职位信息是ajax的请求,所以
# -*- coding: utf-8 -*-
import json
import scrapy
from scrapy import FormRequest
from selflagou.items import SelflagouItem
class WorklagouSpider(scrapy.Spider):
name = 'worklagou'
allowed_domains = ['lagou.com']
# kd是要爬取的职位,拉勾网的职位信息是通过ajax,将kd设置为输入框,可以输入你想要爬取的职位
kd = input('输入职位:')
start_urls = ['https://www.lagou.com/jobs/list_'+str(kd)]
# 设置cookie和Referer
headers={
'Cookie':'_ga=GA1.2.922961630.1527598469; user_trace_token=20180529205427-6be5a91c-633f-11e8-8f27-5254005c3644; LGUID=20180529205427-6be5b0a9-633f-11e8-8f27-5254005c3644; index_location_city=%E5%8C%97%E4%BA%AC; _gid=GA1.2.1648551100.1532305833; WEBTJ-ID=20180724085434-164c9c7d78778-09b1f2f8b3da92-47e1f32-1327104-164c9c7d788306; _gat=1; LGSID=20180724085434-220c9119-8edc-11e8-a379-525400f775ce; PRE_UTM=m_cf_cpc_baidu_pc; PRE_HOST=www.baidu.com; PRE_SITE=https%3A%2F%2Fwww.baidu.com%2Fbaidu.php%3Fsc.K00000jqTgoHCHWeZa5tm_Mn-7o1hRsTpgd5Aft4aFAeIFCmk1MPUOomATl49rRv-56MQdMX78tlhPndTxS1qn_-ZsbCMr-u_bmMBZaJbpyU4vugwA2ErCbLcjWZzjkEw5K_L6h3ZLVwS_asOJ5UoU80lOitPwNmpM07Dn4RflfVCSKw0s.DD_NR2Ar5Od663rj6tJQrGvKD7ZZKNfYYmcgpIQC8xxKfYt_U_DY2yP5Qjo4mTT5QX1BsT8rZoG4XL6mEukmryZZjzL4XNPIIhExzLu2SMcM-sSxH9vX8ZuEsSXej_qT5o43x5ksSEzseld2s1f_U2qS4f.U1Yk0ZDqs2v4VnL30ZKGm1Yk0Zfqs2v4VnL30A-V5HczPfKM5yF-TZnk0ZNG5yF9pywd0ZKGujYk0APGujYs0AdY5HDsnHIxnH0krNtknjc1g1DsPjuxn1msnfKopHYs0ZFY5Hf10ANGujYkPjRkg1cknjb3g1cznHR30AFG5HcsP0KVm1YLPWnznj6Yn1KxnH0snNtkg1Dsn-ts0Z7spyfqn0Kkmv-b5H00ThIYmyTqn0K9mWYsg100ugFM5H00TZ0qn0K8IM0qna3snj0snj0sn0KVIZ0qn0KbuAqs5H00ThCqnfKbugmqTAn0uMfqn0KspjYs0Aq15H00mMTqnH00UMfqn0K1XWY0IZN15Hn1rjRdP10zPHbYPW6sP10LnW00ThNkIjYkPHnzn1b1PWTsrjD30ZPGujdhn16LPWRsuH0snjf1mWTv0AP1UHdKnjfzfHNAnYm3wDN7nHD40A7W5HD0TA3qn0KkUgfqn0KkUgnqn0KlIjYs0AdWgvuzUvYqn7tsg1Kxn7ts0Aw9UMNBuNqsUA78pyw15HKxn7tsg1nkrHb1PNts0ZK9I7qhUA7M5H00uAPGujYs0ANYpyfqQHD0mgPsmvnqn0KdTA-8mvnqn0KkUymqn0KhmLNY5H00uMGC5H00uh7Y5H00XMK_Ignqn0K9uAu_myTqnfK_uhnqn0KWThnqPjDsrj6%26ck%3D742.1.87.298.565.298.557.393%26shh%3Dwww.baidu.com%26sht%3Dbaidu%26us%3D1.0.1.0.1.302.0%26ie%3Dutf-8%26f%3D8%26tn%3Dbaidu%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26rqlang%3Dcn%26inputT%3D3159%26bc%3D110101; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flp%2Fhtml%2Fcommon.html%3Futm_source%3Dm_cf_cpc_baidu_pc%26m_kw%3Dbaidu_cpc_bj_e110f9_d2162e_%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591; JSESSIONID=ABAAABAABEEAAJABC29FEBF1344B3EAF297880D6D2C3B4D; Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1532305833,1532333926,1532393675,1532393679; TG-TRACK-CODE=index_search; LGRID=20180724085445-280d3562-8edc-11e8-a379-525400f775ce; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1532393685; SEARCH_ID=f0feaea9597b46a6add3ed1909a978dd',
# 防盗链
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
}
page=1
def parse(self, response):
with open('lagou.html','w') as f:
f.write(response.text)
formdata={"kd":str(self.kd),"pn":'1',"first":"true"}
url="https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
yield FormRequest(url,callback=self.parse_work,formdata=formdata,headers=self.headers)
def parse_work(self,response):
text=json.loads(response.text)
res=[]
try:
res=text["content"]["positionResult"]["result"]
except:
pass
if len(res)>0:
for position in res:
item=SelflagouItem()
try:
item['title']=position["positionName"]
item["education"]=position["education"]
item["company"]=position["companyFullName"]
item["experience"]=position["workYear"]
item["location"]=position["city"]
item["salary"]=position["salary"]
except:
pass
yield item
self.page+=1
url="https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
formdata={"kd":str(self.kd), "pn": str(self.page), "first": "false"}
yield FormRequest(url,callback=self.parse_work,formdata=formdata,headers=self.headers)
else:
print('爬虫结束')3.编辑pipeline.py文件
import json
class SelflagouPipeline(object):
def process_item(self, item, spider):
with open('work.json','a',encoding='utf-8') as f:
f.write(json.dumps(dict(item),ensure_ascii=False)+'\n')
return item
4.设置settings文件
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 20
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
}
DOWNLOADER_MIDDLEWARES = {
'selflagou.middlewares.SelflagouDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'selflagou.pipelines.SelflagouPipeline': 300,
}
运行爬虫,将爬取的文件存储为csv格式的文件
#运行start.py文件,将爬取的数据存储成为csv格式
from scrapy import cmdline
cmdline.execute('scrapy crawl worklagou -o info2.csv'.split())数据分析:对以上的数据进行数据分析,使用工具jupyter notebook ,结合pandas ,numpy,matplotlib进行数据筛选,分析汇总,以及图表呈现
import pandas as pd
import numpy as np
import seaborn as sns
lagou=pd.read_csv('./workinfo.csv')
lagou.info()运行结果:
RangeIndex: 1260 entries, 0 to 1259 Data columns (total 6 columns): company 1260 non-null object education 1260 non-null object experience 1260 non-null object location 1260 non-null object salary 1260 non-null object title 1260 non-null object dtypes: object(6) memory usage: 59.1+ KB
查看数据的前五行数据
lagou.head()
查看职位的城市分布
city=lagou['location']
city=pd.DataFrame(city.unique())
city运行结果

使用seaborn进行数据的图表展示,查看python职位招聘的学历水平分布情况,ps:seaborn不支持中文,需要将中文替换成英文
education=lagou['education']
education=pd.DataFrame(education.unique())
lagou['education']=lagou['education'].replace('不限','unlimited')
lagou['education']=lagou['education'].replace('大专','junitor')
lagou['education']=lagou['education'].replace('本科','bachelor')
lagou['education']=lagou['education'].replace('硕士','master')
lagou['education']=lagou['education'].replace('博士','doctor')
# 使用seaborn需要使用英文,不支持中文
import seaborn as sns
sns.set_style('whitegrid')
sns.countplot(x='education',data=lagou,palette='Blues_d')
# 下图显示招聘学历要求以本科学历为主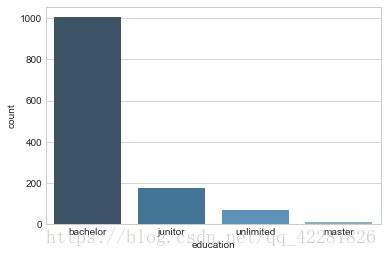
使用seaborn进行数据的图表展示,查看python职位招聘的要求的工作经验情况
experience=lagou['experience']
experience=pd.DataFrame(experience.unique())
lagou['experience']=lagou['experience'].replace('不限','unlimited')
lagou['experience']=lagou['experience'].replace('1年以下','<1')
lagou['experience']=lagou['experience'].replace('1-3年','1-3')
lagou['experience']=lagou['experience'].replace('3-5年','3-5')
lagou['experience']=lagou['experience'].replace('5-10年','5-10')
lagou['experience']=lagou['experience'].replace('应届毕业生','intern')
experience
sns.countplot(x='experience',data=lagou,palette='Greens_d')
# 下图数据显示,招聘的工作经验人数以3-5年最多,其次是1-3年工作经验者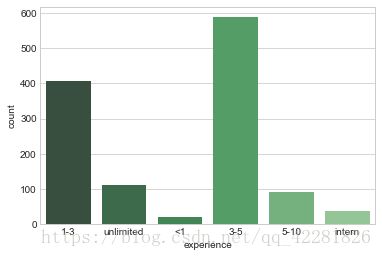
使用matplotlib进行薪资水平的展示,查看各个薪资分布的职位数是多少,哪个薪资区间的人数是最多的
import matplotlib.pyplot as plt
%matplotlib inline
d,ax1=plt.subplots(figsize=(20,20))
sns.countplot(y='salary',data=lagou,ax=ax1)
ax1.set_title('python salary distribute',fontsize=18)
# 薪资各水平分布
ax1.set_xlabel('salary')
ax1.set_ylabel('level')
plt.show()
# 下图显示薪资在15-30k的最多
# 以上数据为拉勾网python职位分析
以上是根据拉勾网的python职位的爬虫和数据分析,同样可以爬取其他职位的数据并进行数据分析和图表展示,也可以几个职位进行对比,以上的图表只是简单的使用了pandas ,numpy和matplotlib,还可以进行更多维度的数据和图表分析