你不知道的Linux Kernel——Linux内核的工作原理
Linux内核更新是越来越快了,可能由于Linux的普及,大家都开始关注了,各种安全隐患也越来越多。支持Intel、Alpha、PPC、Sparc、IA-64、ARM、MIPS、Amiga、Atari和IBMs/390等,还支持32位大文件系统。而在Intel平台上,物理内存最大支持可以达到64GB。加强对IDE和SCSI硬件系统的支持,并增强了对USB设备和3D加速卡的支持。下面向大家详细介绍LinuxKernel。
牛津字典中对"kernel"一词的定义是:"较软的、通常是一个坚果可食用的部分。"当然还有第二种定义:"某个东西核心或者最重要的部分。"对Linux来说,它的Kernel无疑属于第二种解释。让我们来看看这个重要的东西是如何工作的,先从一点理论说起。
广义地来说kernel就是一个软件,它在硬件和运行在计算机上的应用程序之间提供了一个层。严格点从计算机科学的角度来说,Linux中的Kernel指的是Linus Torvalds在90年代初期写的那点代码。
所有的你在Linux各版本中看到的其他东西--Bash shell、KDE窗口管理器、web浏览器、X服务器、Tux Racer以及所有的其他,都不过是运行在Linux上的应用而已,而不是操作系统自身的一部分。为了给大家一个更加直观的感觉,我来举个例子,比如RHEL5的安装大概要占据2.5GB的硬盘空间(具体多大当然视你的选择安装来定),在这其中,kernel以及它的各个模块组件,只有47MB,所占比例约为2%。
在kernel内部
那么kernel到底是如何工作的呢?如下面的图表。Kernel通过许多的进入端口也就是我们从技术角度所说的系统调用,来使得运行在它上面的应用程序可用。Kernel使用的系统调用比如"读"和"写"来提供你硬件的抽象(abstraction)。
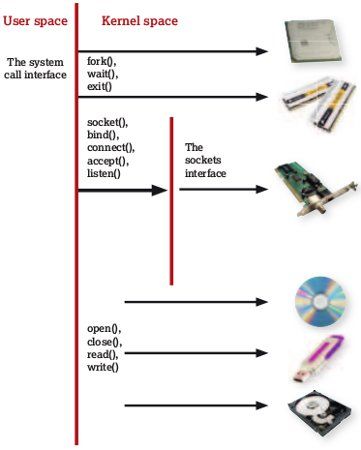
从程序员的视角来看,这些看起来只是普通的功能调用,然而实际上系统调用在处理器的操作模式上,从用户空间到Kernel空间有一个明显的切换。同时,系统调用提供了一个"Linux虚拟机",可以被认为是对硬件的抽象。
Kernel提供的更明显的抽象之一是文件系统。举例来说,这里有一段短的程序是用C写的,它打开了一个文件并将内容拷贝到标准的输出:
#include
int main()
{
int fd, count; char buf[1000];
fd=open("mydata", O_RDONLY);
count = read(fd, buf, 1000);
write(1, buf, count);
close(fd);
} 台前幕后
系统文件是Kernel提供的较为明显的一种抽象。还有一些特性不是这么的明显,比如进程调度。任何一个时间,都可能有好几个进程或者程序等待着运行。Kernel的时间调度给每个进程分配CPU时间,所以就一段时间内来说,我们会有种错觉:电脑同一时间运行好几个程序。这是另外一个C程序:
#include
main()
{
if (fork()) {
write(1, "Parent\n", 7);
wait(0);
exit(0);
}
else {
write(1, "Child\n", 6);
exit(0);
}
} 在这个程序中创建了一个新进程,而原来的进程(父进程)和新进程(子进程)都编写了标准输出然后结束。注意系统调用fork(), exit() 以及 wait()执行程序的创建、结束和各自同步。这是进程管理和调度中最典型的简单调用。
Kernel还有一个更加不易见到的功能,连程序员都不易察觉,那就是存储管理。每个程序运行得都好像它有个自己的地址空间来调用一样,实际上它跟其他进程一样共享计算机的物理存储,如果系统运行的存储过低,它的地址空间甚至会被磁盘的交互区暂时寄用。存储管理的另外一个方面是防止一个进程访问其他进程的地址空间--对于多进程操作系统来说这是很必要的一个防范措施。
Kernel同样还配置网络链接协议比如IP、TCP和UDP等,它们在网络上提供机器对机器(machine-to-machine)和进程对进程(process-to-process)的通信。这里又会造成一种假象,即TCP在两个进程之间提供了一个固定连接--就好像连接两个电话的铜线一样,实际中却并没有固定的连接,特殊的引用协议比如FTP、DNS和HTTP是通过用户级程序来实施的,而并非Kernel的一部分。
Linux(像之前的Unix)在安全方面口碑很好,这是因为Kernel跟踪记录了每个运行进程的user ID和group ID,每次当一个应用企图访问资源(比如打开一个文件来写入)的时候,Kernel就会核对文件上的访问许可然后做出允许/禁止的命令。这种访问控制模式最终对整个Linux系统的安全作用很大。
Kernel还提供了一大套模块的集合,其功能包括如何处理与硬件设备交流的诸多细节、如何从磁盘读取一个分区、如果从网络接口卡获取数据包等。有时我们称这些为设备驱动。
模块化的Kernel
现在我们队Kernel是做什么的已经有了一些了解,让我们再来简单看下它的物理组成。早期版本的Linux Kernel是整体式的,也就是说所有的部件都静态地连接成一个(很大的)执行文件。
相比较而言,现在的Linux Kernel是模块化的:许多功能包含在模块内,然后动态地载入kernel中。这使得kernel的内核很小,而且在运行kernel时可以不必reboot就能载入和替代模块。
Kernel的内核在boot time时从位于/boot 目录的一个文件加载进存储中,通常这个/boot 目录会被叫做KERNELVERSION,KERNELVERSION与kernel版本有关。(如果你想知道你的kernel版本是什么,运行命令行显示系统信息-r。)kernel的模块位于目录/lib/modules/KERNELVERSION之下,所有的组件都会在kernel安装时被拷贝。
管理模块
大部分情况下,Linux管理它的模块不需要你的帮忙,但是如果必要的时候有命令行可以来手动检查和管理模块。比如,为了查清楚当前到底哪个模块在载入kernel。这里有一个lsmod输出的例子:
# lsmod
pCSPkr 4224 0
hci_usb 18204 2
psmouse 38920 0
bluetooth 55908 7 rfcomm,l2cap,hci_usb
yenta_socket 27532 5
rSRC_nonstatIC 14080 1 yenta_socket
iSOFs 36284 0输出的内容包括:模块的名字、大小、使用次数和依赖于它的模块列表。使用次数对防止卸载当前活跃的模块非常总要。Linux只允许使用次数为零的模块被移除。
你可以使用modprobe来手动加载和卸载模块,(还有两个命令行叫做insmod和rmmod,但modprobe更易于使用因为它自动移除了模块依赖)。比如lsmod的输出在我们的电脑上显示了一个名叫isofs的卸载模块,它的使用次数是零而且没有依赖模块,(isofs是一个模块,它支持CD上使用的ISO系统文件格式)这种情况下,kernel会允许我们卸载模块:
# modprobe -r isofs 现在,isofs不再显示在Ismod的输出中,kernel由此节省了36,284字节的存储。如果你放入CD并且让它自动安装,kernel将自动重新载入isofs模块,而且isofs的使用次数增加到1次。如果这时候你还试图移除模块,就不会成功了因为它正在被使用:
# modprobe -r isofs
FATAL: Module isofs is in use.Lsmod只是列出了当前被载入的模块,modprobe则将列出所有可用的模块,它实际上输出了/lib/modules/KERNELVERSION目录下所有的模块,名单会很长!
实际上,使用modprobe来手动加载一个模块并不常见,但确实可以通过modprobe命令行来对模块设置参数,例如:
# modprobe usbcore blinkenlights=1 我们并不是在创建blinkenlights,而是usbcore模块的实参数。
那么如何知道一个模块会接受什么参数呢?一个比较好的方法是使用modinfo命令,它列出了关于模块的种种信息。这里有一个关于模块snd-hda-intel的例子
# modinfo snd-hda-intel
filename: /lib/modules/2.6.20-16-generic/kernel/sound/PCI/hda/snd-hda-intel.ko
description: Intel HDA driver
license: GPL
srcversion: A3552B2DF3A932D88FFC00C
alias: pci:v000010DEd0000055Dsv*sd*bc*sc*i*
alias: pci:v000010DEd0000055Csv*sd*bc*sc*i*
depends: snd-PCM,snd-page-alLOC,snd-hda-codec,snd
vermagic: 2.6.20-16-generic SMP mod_unload 586
parm: index:Index value for Intel HD audio interface. (int)
parm: id:ID string for Intel HD audio interface. (charp)
parm: model:Use the given board model. (charp)
parm: position_fix:Fix DMA pointer (0 = auto, 1 = none, 2 = POSBUF, 3 = FIFO size). (int)
parm: probe_mask:Bitmask to probe codecs (default = -1). (int)
parm: single_cmd:Use single command to communicate with codecs (for debugging only). (bool)
parm: enable_msi:Enable Message SignaLED Interrupt (MSI) (int)
parm: enable:bool对我们来说比较有兴趣的以"parm"开头的那些部分:显示了模块所接受的参数。这些描述都比较简明,如果想要更多的信息,那就安装kernel的源代码,在类似于/usr/src/KERNELVERSION/Documentation的目录下你会找到。
里面会有一些有趣的东西,比如文件/usr/src/KERNELVERSION/Documentation/sound/alsa/ALSA-Configuration.txt描述的是被许多ALSA声音模块承认的参数;/usr/src/KERNELVERSION/Documentation/kernel-parameters.txt这个文件也很有用。
前几天在Ubuntu论坛有一个例子,说的是如何将参数传递到一个模块(详见https://help.ubuntu.com/community/HdaIntelSoundHowto)。实际上问题的关键是snd-hda-intel参数在正确驱动声音硬件时需要一点操作,而且在boot time加载时会中止。解决方法的一部分是将probe_mask=1选项赋给模块,如果你是手动加载模块,你需要输入:
# modprobe snd-hda-intel probe_mask=1 更有可能,你在文件/etc/modprobe.conf中放置这样类似的一行:options snd-hda-intel probe_mask=1
这"告诉"modprobe每次在加载snd-hda-intel模块时包含probe_mask=1选项。现在的有些Linux版本将这一信息分离进/etc/modprobe.d下的不同文件中了,而不是放入modprobe.conf中。
/proc系统文件
Linux kernel同样通过/proc系统文件来展示了许多细节。为了说明/proc,我们首先需要扩展我们对于文件的理解。除了认为文件就是存储在硬盘或者CD或者存储空间上的持久信息之外,我们还应当把它理解为任何可以通过传统系统调用如:打开、读、写、关闭等访问的信息,当然它也可以被常见的程序访问。
/proc之下的"文件"完全是kernel虚拟的一个部分,给我们一个视角可以看到kernel内部的数据结构。实际上,许多Linux的报告工具均能够很好地呈现在/proc下的文件中寻到的格式化版本的信息。比如,一行/proc/modules将展示一行当前加载的模块。
同样的,/proc/meminfo提供了关于虚拟存储系统当前状态的更多细节信息,而类如vmstat的工具则是以一种更加可理解的方式提供了相同的一些信息;/proc/net/arp显示了系统ARP cache的当前内容,从命令行来说,arp -a显示的也是相同的信息。
尤其有意思的是/proc/sys下的"文件"。/proc/sys/net/ipv4/ip_forward下的设置告诉我们kernel是否将转发IP数据包,也就是说是否扮演网关的作用。现在,kernel告诉我们这是关闭的:
# cat /proc/sys/net/ipv4/ip_forward
0当你发现你可以对这些文件写入的时候,你会觉得更加有意思。继续举例来说:
# echo 1 > /proc/sys/net/ipv4/ip_forward将在运行的kernel中打开IP 转发(IP forwarding)
除了使用cat和echo来检查和更正/proc/sys下的设置以外,你也可以使用sysctl命令:
# sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0 这等同于:
# cat /proc/sys/net/ipv4/ip_forward
0 也等同于:
# sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1 还等同于:
# echo 1 > /proc/sys/net/ipv4/ip_forward 需要注意的是,以这种方式你所做的设置改变只能影响当前运行的kernel的,当reboot的时候就不再有效。如果想让设置永久有效,将它们放置在/etc/sysctl.conf文件中。在boot time时,sysctl将自动重新确定它在此文件下找到的任何设置。
/etc/sysctl.conf下的代码行大概是这样的:net.ipv4.ip_forward=1
性能调优(performance tuning)
有这样一个说法:/proc/sys下可写入的参数孕育了整个Linux性能调优的亚文化。我个人觉得这种说法有点过夸,但这里会有几个你确实很想一试的例子:Oracle 10g的安装说明(www.oracle.com/technology/obe/obe10gdb/install/linuxpreinst/linuxpreinst.htm)要求你设置一组参数,包括:kernel.shmmax=2147483648 这将公用存储器的大小设置为2GB。(公用存储器是处理期内的通信机制,允许存储单元在多个进程的地址空间内同时可用)
IBM 'Redpaper'在Linux性能和调优方面的说明(www.redbooks.ibm.com/abstracts/redp4285.html)在调教/proc/sys下的参数方面给出了不少建议,包括:vm.swappiness=100 这个参数控制着存储页如何被交换到磁盘。
一些参数可以被设置从而提高安全性,如net.ipv4.icmp_echo_ignore_broadcasts=1 它"告诉"kernel不必响应ICMP请求,从而使得你的网络免受类如Smurf攻击之类的拒绝服务器(denial-of-service)型攻击。
net.ipv4.conf.all.rp_filter=1 则是"告诉"kernel加强入站过滤(ingress filtering)和出站过滤(egress filtering)
那么有没有一个说明能涵盖这所有的参数?好吧,这有一行命令:# sysctl -a 它将展示所有的参数名字和当前值。列表很长,但是你无法知道这些参数是做什么的。另外比较有用的参考是Red Hat Enterprise Linux Reference Guide,对此有整章节的描述,你可以从www.redhat.com/docs/manuals/enterprise上下载。