Tesseract-OCR识别 学习(一)命令识别
1、Tesseract概述(来自网页)
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封。
数年以后,HP意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生--2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。
Tesseract目前已作为开源项目发布在Google Project,其项目主页在查看,其最新版本3.0已经支持中文OCR,并提供了一个命令行工具。本次我们来测试一下Tesseract 3.0,由于命令行对最终用户不太友好,我用WPF简单封装了一下,就可以方便的进行中文OCR了。
1.1、首先到Tesseract项目主页下载命令行工具、源代码、中文语言包:
链接: http://pan.baidu.com/s/1bptAnsN 密码: hd2y 下载后解压到相应的文件下。文件如下:

Tesseract-OCR识别 学习(一)命令识别
文件介绍:tif,jpg是要识别的图片。tessdata:识别时使用语言包的类型,
jTessBoxEditor:这个是要训练时候用的,运行里面的bat文件即可。
2.使用步骤
A:命令行进入到相应的文件下,直接使用:tesseract 3.jpg result -l eng 即可。
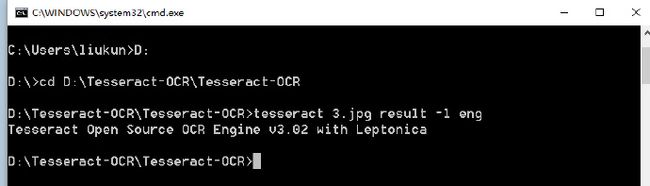
Tesseract-OCR识别 学习(一)命令识别
会在当前目录下生成:result.txt文件。里面既识别的结果.
3.训练(机器不是所有的字符都可以识别)
A:先要目录下创建font_properties文件 填写内容:
font 0 0 0 0 0
B:运行jTessBoxEditor工具,在点击菜单栏中Tools—>Merge TIFF。在弹出的对话框中选择样本图像(按Shift选择多张)
合并成num.font.exp0的tif图片文件。
注:Make Box File的命令格式为:
tesseract [lang].[fontname].exp[num].tif [lang].[fontname].exp[num] batch.nochop makebox
C:生成Box File文件
tesseract.exe num.font.exp0.tif num.font.exp0 batch.nochop makebox
会生成一个num.font.exp0.box 文件
D:以此执行下面的命令
echo 1:Compute the Character Set…
unicharset_extractor.exe num.font.exp0.box
echo 2:生成tr文件
tesseract.exe num.font.exp0.tif num.font.exp0 nobatch box.train
echo 3:
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp0.tr
echo 4:Clustering…
cntraining.exe num.font.exp0.tr
echo 5:Rename Files… 重命名
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo 6:Create Tessdata… 生成自己的识别库 num.traineddata,拷贝到tessdata目录下即可
combine_tessdata.exe num.
训练参考来自 :http://blog.csdn.net/firehood_/article/details/8433077
注:训练时候的图片必须是要大小相同的,这样识别的地方才一直。