用Python 爬虫批量下载PDF文档
更新:之前代码是用 python2 写的,有关 python3 的代码可以参考这位博主的:https://blog.csdn.net/baidu_28479651/article/details/76158051
代码如下:
# coding = UTF-8
# 爬取李东风PDF文档,网址:http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/index.htm
import urllib.request
import re
import os
# open the url and read
def getHtml(url):
page = urllib.request.urlopen(url)
html = page.read()
page.close()
return html
# compile the regular expressions and find
# all stuff we need
def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?\.pdf)'
url_re = re.compile(reg)
url_lst = url_re.findall(html.decode('gb2312'))
return(url_lst)
def getFile(url):
file_name = url.split('/')[-1]
u = urllib.request.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print ("Sucessful to download" + " " + file_name)
root_url = 'http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/'
raw_url = 'http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/index.htm'
html = getHtml(raw_url)
url_lst = getUrl(html)
os.mkdir('ldf_download')
os.chdir(os.path.join(os.getcwd(), 'ldf_download'))
for url in url_lst[:]:
url = root_url + url
getFile(url)
--------------------------------------------------------------------------- 我是分割线 --------------------------------------------------------------------------
之前稍微看了用Python爬虫爬取贴吧图片的文章,发现用Python爬虫确实方便。一个非常有用的东西便是自动下载网上的PDF文档。下面就来举两个例子,程序主要参考自这篇文章:http://ddswhu.com/2015/03/25/python-downloadhelper-premium/ 。
爬取PDF文档与爬取图片是有所不同的,因为网页(HTML文件)的PDF链接往往并不是该PDF文件的实际所在地址。下面的两个具体例子会说明。
先看一个例子。我们想下载这个页面上的几个文档,网址是:
http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/index.htm ,里面是李东风老师的一些LaTex排版心得,截图如下:
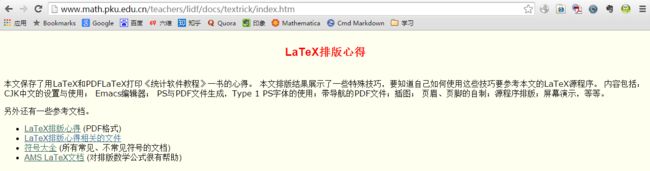
其中第2个是一个zip压缩包,其它三个是PDF文档,我们的目的是把这三篇文档下载下来。用谷歌浏览器查看网页源文件可得:

可以看到那三个PDF的连接,分别是tricks.pdf,symbols-a4.pdf和AmsLatex.pdf。嗯,直接就是文档的名字,这也挺好的。但是,如果爬虫的时候只用正则表达式匹配到这三个字符串进行下载是不行的,因为这不是其实际的网址。比如说我们点击一下tricks.pdf,进入其实际的URL,发现是 http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/tricks.pdf ,这才是其完整的URL,即 http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/ 再加上文档名tricks.pdf,还好其他两篇文档的完整的URL是类似的,为我们爬虫提供了方便。
按照参考程序,稍微加以修改,可得爬虫代码如下(版本为Python 2.7):
# coding = UTF-8
# 爬取李东风PDF文档,网址:http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/index.htm
import urllib2
import re
import os
# open the url and read
def getHtml(url):
page = urllib2.urlopen(url)
html = page.read()
page.close()
return html
# compile the regular expressions and find
# all stuff we need
def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?\.pdf)'
url_re = re.compile(reg)
url_lst = re.findall(url_re,html)
return(url_lst)
def getFile(url):
file_name = url.split('/')[-1]
u = urllib2.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print "Sucessful to download" + " " + file_name
root_url = 'http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/'
raw_url = 'http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/index.htm'
html = getHtml(raw_url)
url_lst = getUrl(html)
os.mkdir('ldf_download')
os.chdir(os.path.join(os.getcwd(), 'ldf_download'))
for url in url_lst[:]:
url = root_url + url
getFile(url)
程序中我们把原网址 http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/index.htm 称为raw_url,把PDF文档实际的URL前面有规律性的那一部分 http://www.math.pku.edu.cn/teachers/lidf/docs/textrick/ (注意最后那个斜杠在代码中不能省略)称为root_url,运行效果如图所示(为了简单起见,这里直接用了Python自带的IDLE来运行的程序):

运行后会自动下载那3篇PDF文档,并将它们存放在ldf_download文件夹中(该文件夹由程序自动创建,无需事先手动建立)。嗯,确实很方便啊!
下面来看另一个例子。其实原理一样啦,关键是查看PDF文档完整的URL而已。我们想下载这个页面上的15篇PDF文档,网址是: http://gr.xjtu.edu.cn/web/jiansun/teaching ,里面是孙剑老师的教学课件,截图如下:

我们先来查看网页源文件,见下图:

可以发现里面PDF链接的名字有点奇葩,并不是PDF文档的标题之类的。当然,我们更关注的是文档完整的URL,点击第一个Chapter 1: Introduction 进去,发现完整的网址是: http://gr.xjtu.edu.cn/c/document_library/get_file?folderId=1826595&name=DLFE-33613.pdf ,而且其它几个也是类似的,即要下载的root_url为 http://gr.xjtu.edu.cn/c/document_library/get_file?folderId=1826595&name=DLFE- (注意不要忘了最后的短破折号),后面再加上33613.pdf即可,因此代码稍作修改即可,见下:
# coding = UTF-8
# 爬取孙剑PDF文档,网址:http://gr.xjtu.edu.cn/web/jiansun/teaching
import urllib2
import re
import os
# open the url and read
def getHtml(url):
page = urllib2.urlopen(url)
html = page.read()
page.close()
return html
# compile the regular expressions and find
# all stuff we need
def getUrl(html):
reg = r'(?:href|HREF)="?((?:http://)?.+?\.pdf)'
url_re = re.compile(reg)
url_lst = re.findall(url_re,html)
return url_lst
def getFile(url):
file_name = url.split('-')[-1]
u = urllib2.urlopen(url)
f = open(file_name, 'wb')
block_sz = 8192
while True:
buffer = u.read(block_sz)
if not buffer:
break
f.write(buffer)
f.close()
print "Sucessful to download" + " " + file_name
root_url = 'http://gr.xjtu.edu.cn/c/document_library/get_file?folderId=1826595&name=DLFE-'
raw_url = 'http://gr.xjtu.edu.cn/web/jiansun/teaching'
html = getHtml(raw_url)
url_lst = getUrl(html)
os.mkdir('sunjian_download')
os.chdir(os.path.join(os.getcwd(), 'sunjian_download'))
for i in range(1,16):
temp = url_lst[i].split('-')[-1]
url = root_url + temp
getFile(url)
程序中我们用正则表达式匹配了PDF链接,并用split函数提取了那一串数字(比如33613.pdf)作为PDF文档的名字,所以文档是全部下载好了,见下图:

但是可以发现,用数字作为文档名挺乱的,所以该程序虽然完成了任务,但是还不够好,有待进一步完善。